By Tiago De Souza Fernandes, Bryan Dumond, Daniel Scrivener and Vivien van Veldhuizen
If you have been keeping up with some of the recent developments in artificial intelligence, you might have seen AI models that can generate images from a text-based description, such as CLIP or DALL·E. These models are able to generate completely new images from just a single text-prompt (see for example this twitter account). Models such as CLIP and DALL·E operate by embedding text and images in the same vector space, which makes it possible to frame the image synthesis as an optimization problem, ie: find an image that, when processed by a neural network, yields an embedding similar to a corresponding text embedding. A problem with this setup, however, is that it is severely underconstrained: there are many such images and some of them are not very interesting from the perspective of a human. To circumvent this issue, previous research has focused on incorporating priors into this optimization.
Over the last few weeks, our team, under the supervision of Matheus Gadelha from Adobe Research, looked into a specific instance of such constraints: namely, what would happen if the images could only be formed through a simple assembly of geometric primitives (spheres, cuboids, planes, etc)?
An Overview of the Optimization Problem
The ability to unite text and images in the same vector space through neural networks like CLIP lends itself to an intuitive formulation of the problem we’d like to solve: What image comprising a set of geometric primitives is most similar to a given text prompt?
We’ll represent CLIP’s mapping between images/text and vectors as a function, $\phi$. Since CLIP represents text and images alike as n-dimensional vectors, we can measure their similarity in terms of the angle between the two vectors. Assuming that the vectors it generates are normalized, the cosine of the angle between them is simply the dot product \(\langle \phi(Image), \phi(Text) \rangle\). Minimizing this quantity with respect to the image generated from our geometric primitive of choice should yield a locally optimal solution: something that more closely approximates the desired text prompt than its neighbors.



In order to get a sense of where the solution might exist relative to our starting point, we’d like all operations involved in the process of computing this similarity score to be differentiable. That way, we’ll be able to follow the gradient of the function and use it to update our image at each step.
To achieve our goals within a limited two-week timeframe, we desire rasterizers built on simple but powerful frameworks that would allow for as rapid iteration as possible. As such, PyTorch-based differentiable renderers like diffvg (2D) and Nvdiffrast (3D) provide the machinery to relate image embeddings with the parameters used to draw our primitives to the screen: we’ll be making extensive use of both throughout this project.
2D Shape Optimization
We started by looking at the 2D case, taking this paper as our basis. In this paper, the authors propose CLIPDraw: an algorithm that creates drawings from textual input. The authors use a pre-trained CLIP language-image encoder as a metric for maximizing the similarity between the given description and a generated drawing. This idea is similar to what our project hopes to accomplish, with the main difference being that CLIPDraw operates over vector strokes. We tried a couple of methods to make the algorithm more geometrically aware, the first of which is some data augmentations.
By default, the optimizer has too much creative leeway to interpret which images match our text prompt, leading to some borderline incomprehensible results. Here’s an example of a result that CLIP identifies as a “golden retriever” when left to its own devices:

Here, the optimizer gets the general color palette right while missing out completely on the geometric features of the image. Fortunately, we can force the optimizer to approach the problem in a more comprehensive manner by “augmenting” (transforming) the output at each step. In our case, we applied four random perspective & crop transformations (as do the authors of CLIPDraw) and a grayscale transformation at each step. This forces the optimizer to imitate human perception in the sense that it must identify the same object when viewed under different ambient conditions.
Fortunately, the introduction of data augmentations produced near-instant improvements in our results! Here is a taste of what the neural network can generate using triangles:


Generating Meshes
In addition to manipulating individual shapes, we also tried to generate 2D triangular meshes using CLIP and diffvg. Since diffvg doesn’t provide automatic support for meshes, we circumvented this problem using our own implementation where individual triangles are connected to form a mesh. We started our algorithm with a simple uniform randomly-colored triangulation:

Simply following each step in the gradient direction could change their positions individually, destroying the mesh structure. So, at each iteration, we merge together vertices that would have been pushed away from each other. We also prevent triangles from “flipping”, or changing orientation in such a way that would produce an intersection with another existing triangle. Two of the results can be seen below:


Throughout this process, we introduce and subsequently undo a lot of changes, making the process inefficient and the convergence slow. Another nice approach is to modify only the colors of the triangles rather than their positions and shapes, allowing us to color the mesh structure like a pixel grid:

Non-differentiable Operations and the Evolutionary Approach
Up until this point, we’ve only considered gradient descent as a means of solving our central optimization problem. In reality, certain operations involved in this pipeline are not always guaranteed to be differentiable, especially when it comes to rendering. Furthermore, gradient descent optimization narrows the range of images that we’re able to explore. Once a locally optimal solution is found, the optimizer tends to “settle” on it without experimenting further — often to the detriment of the result.
On the other end of the “random-deterministic” spectrum are evolutionary models, which work by introducing random changes at each step. Changes that improve the result are preserved through future steps, whereas superfluous or detrimental changes are discarded. Unlike gradient descent optimization, evolutionary approaches are not guaranteed to improve the result at each step, which makes them considerably slower. However, by exploring a wider set of possible changes to the images, rather than just the changes introduced by gradient descent, we gain the ability to explore more images.
Though we did not tune our evolutionary model to the same extent as our gradient descent optimizer, we were able to produce a version of the program that performs simple tasks such as optimizing with respect to the overall image color.


3D Shape Optimization
Moving into the third dimension not only gives us a whole new set of geometric primitives to play with, but also introduces fascinating ideas for image augmentations, such as changing the position of the virtual camera. While Nvdiffrast provides a powerful interface for rendering in 3D with automatic differentiation, we quickly discovered that we’d need to implement our own geometric framework before we could test its capabilities.
Nvdiffrast’s renderer is very elegant in its design. It needs only a set of triangles and their indices in addition to a set of vertex colors in order to render a scene. Our first task was to define a set of geometric primitives, as Nvdiffrast doesn’t provide out-of-the-box support for anything but triangles. For anyone familiar with OpenGL, creating an elementary shape such as a sphere is very similar to setting up a VBO/EBO. We set to work creating classes for a sphere, a cylinder, and a cube.
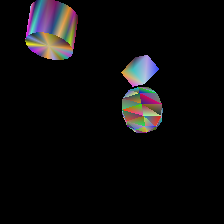
Because the input to Nvdiffrast is one contiguous set of triangles, we also had to design data structures to mark the boundaries between discrete shapes in our triangle list. We did not want the optimizer to operate erratically on individual triangles, potentially breaking up the connectivity of the underlying shape: to this end, we devised a system by which shapes could only be manipulated by a series of standard linear transformations. Specifically, we allowed the optimizer to rotate, scale, and translate shapes at will. We also optimized according to vertex colors as in our previous 2D implementation.
With more time, it would have been great to experiment with new augmentations and learning rates for these parameters: however, setting up a complex environment like Nvdiffrast takes more time than one might expect, and so we have only begun to explore different results at the writing of this blog post. Some features that show promising outcomes are color gradient optimization, as well as the general positioning of shapes:

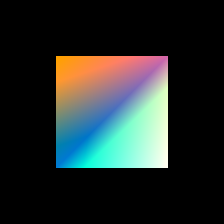
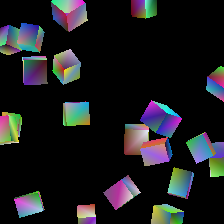

Conclusion
Working on this project over the last few weeks, we saw that it is possible to achieve a lot with neural networks in a relatively short amount of time. Through our exploration of 2D and 3D cases, we were able to generate some early but promising results. More experiments are needed to test the limits of our model, especially with respect to the assembly of complex 3D scenes. Nonetheless, this method of using geometric primitives to synthesize images seems to have great potential, with a number of artistic applications making themselves evident through the results of our work