Primary mentors: Silvia Sellán, University of Toronto and Oded Stein, University of Southern California
Volunteer assistant: Andrew Rodriguez
Fellows: Johan Azambou, Megan Grosse, Eleanor Wiesler, Anthony Hong, Artur RB Boyago, Sara Samy

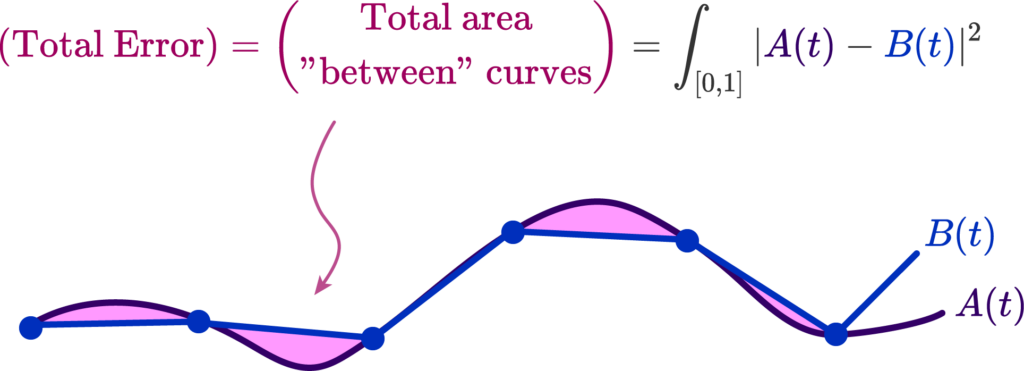
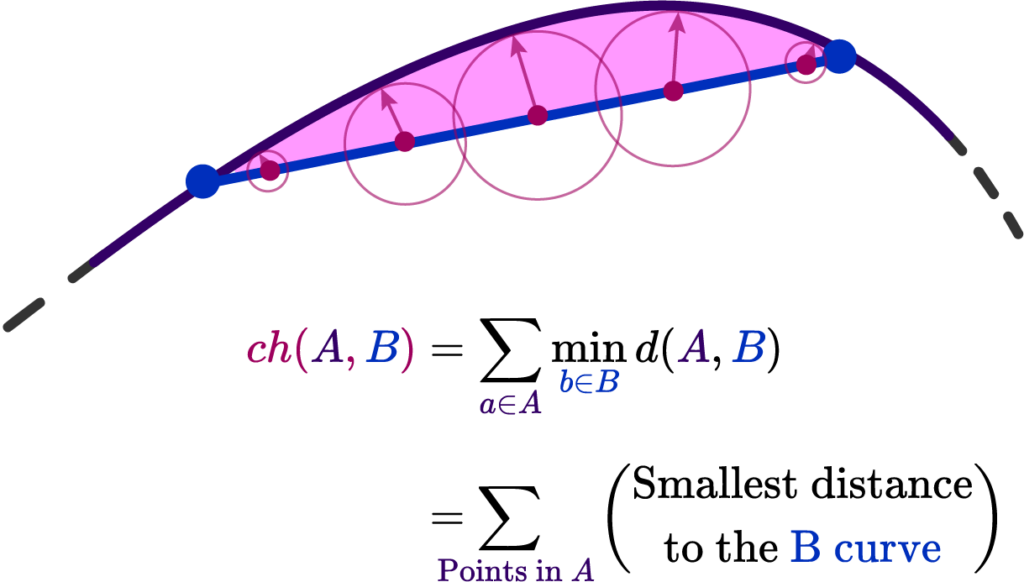
After talking about what are some of the ways to reconstruct sdfs (see part one), we now study the question of how to evaluate their performance. Two classes of error function are considered, the first more inherent to our sdf context, and the second more general in all situations. We will first show results by our old friends, Chamfer distance, Hausdorff distance, and area method (see here for example), and then introduce the inherent one.
Hausdorff and Chamfer Distance
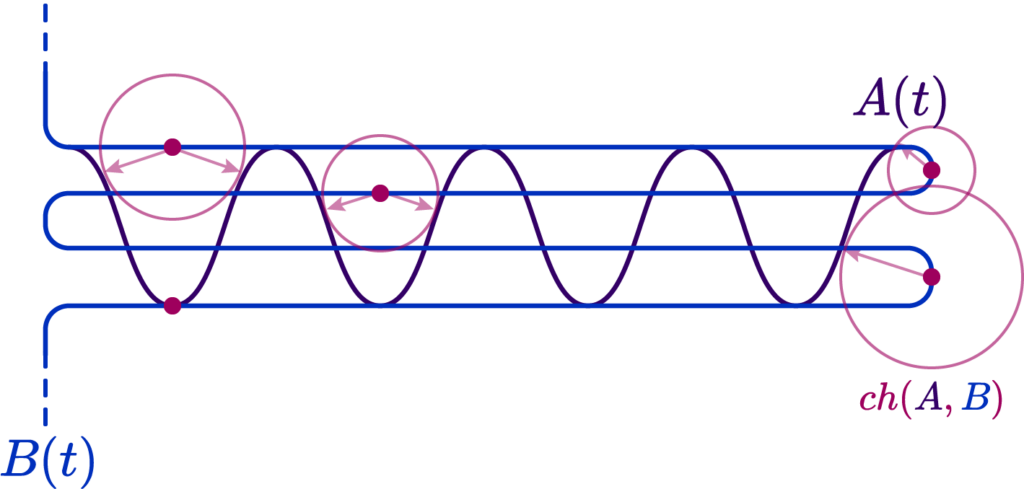
The Chamfer distance provides an average-case measure of the dissimilarity between two shapes. It calculates the sum of the distances from each point in one set to the nearest point in the other set. This measure is particularly useful when the goal is to capture the overall discrepancy between two shapes while being less sensitive to outliers. The Chamfer distance is defined as:
$$
d_{\mathrm{Chamfer }}(X, Y):=\sum_{x \in X} d(x, Y)=\sum_{x \in X} \inf _{y \in Y} d(x, y)
$$

The Bi-Chamfer distance is an extension that considers the average of the Chamfer distance computed in both directions (from \(X\) to \(Y\) and from \(Y\) to \(X\) ). This bidirectional measure provides a more balanced assessment of the dissimilarity between the shapes:
$$
d_{\mathrm{B} \mathrm{-Chamfer }}(X, Y):=\frac{1}{2}\left(\sum_{x \in X} \inf {y \in Y} d(x, y)+\sum{y \in Y} \inf _{x \in X} d(x, y)\right)
$$
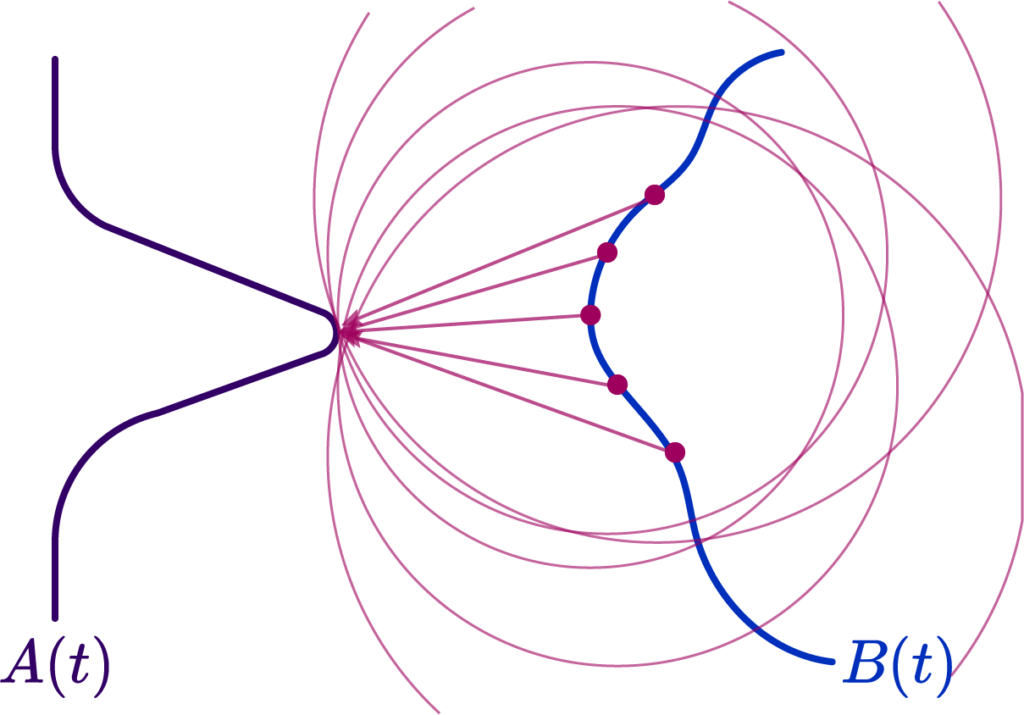
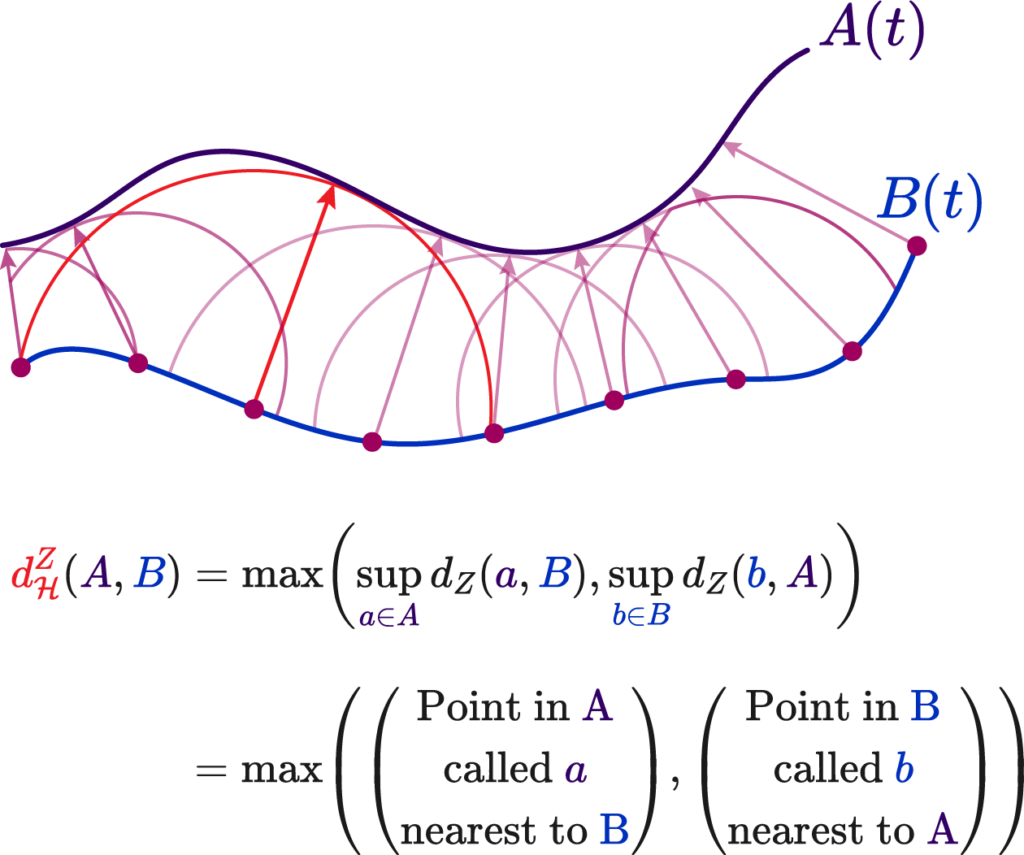
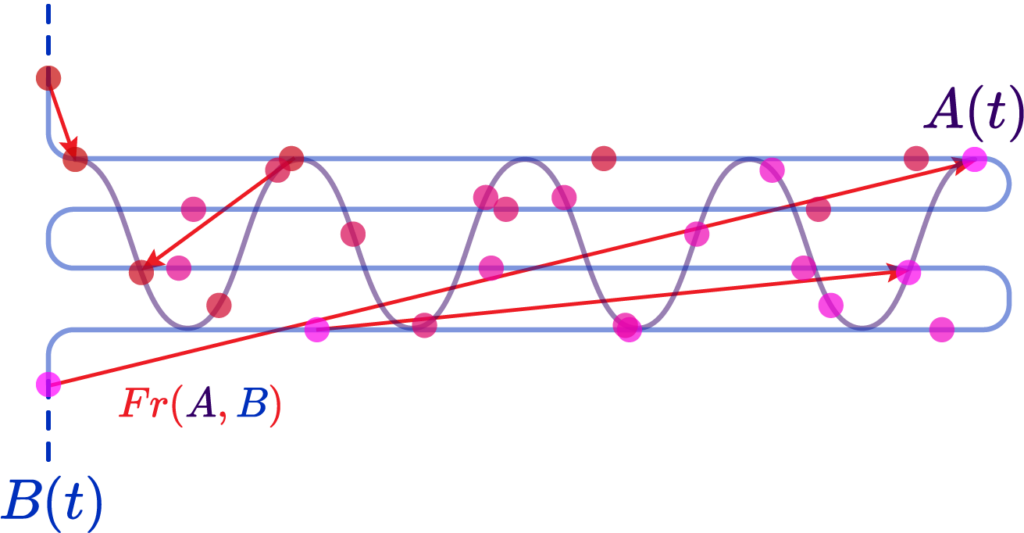
The Hausdorff distance, on the other hand, measures the worst-case scenario between two shapes. It is defined as the maximum distance from a point in one set to the closest point in the other set. This distance is particularly stringent because it reflects the largest deviation between the shapes, making it highly sensitive to outliers.
The formula for Hausdorff distance is:
$$
d_{\mathrm{H}}^Z(X, Y):=\max \left(\sup {x \in X} d_Z(x, Y), \sup {y \in Y} d_Z(y, X)\right)
$$
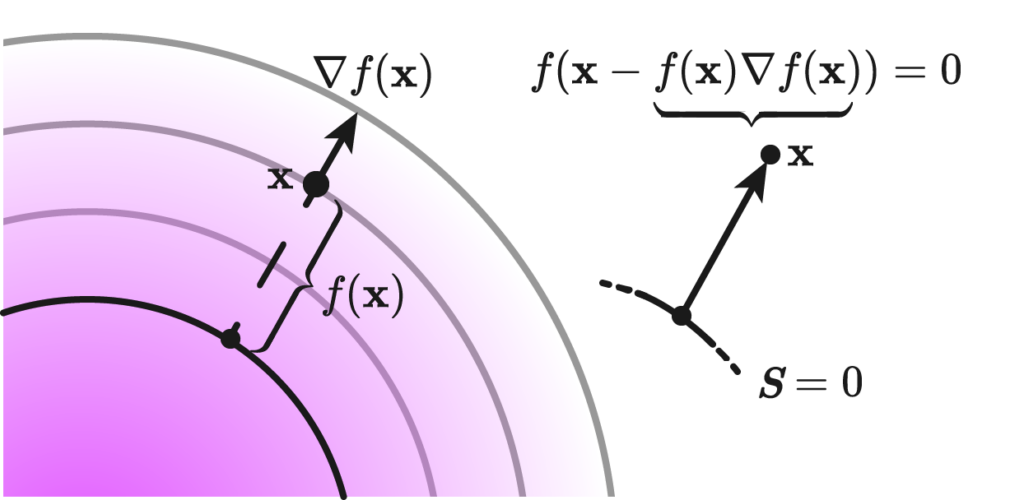
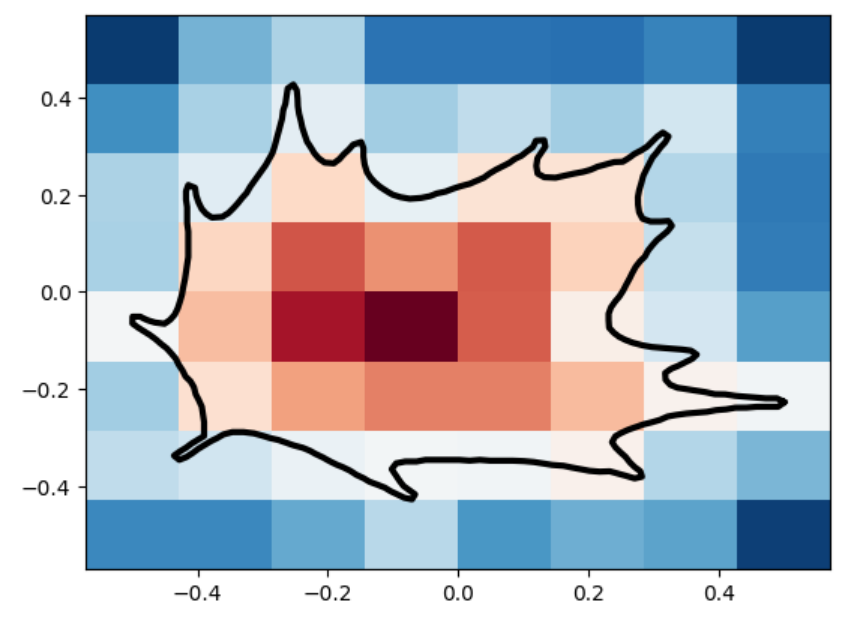
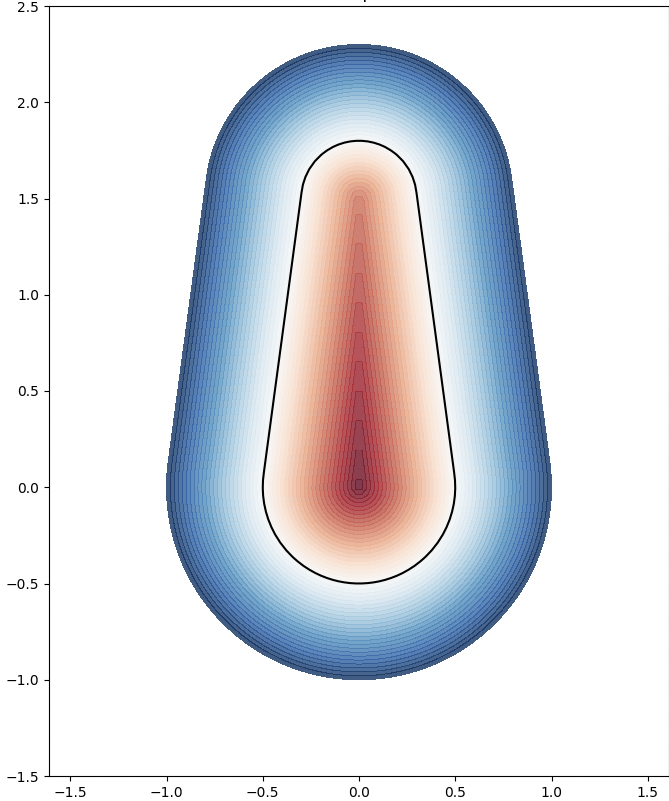
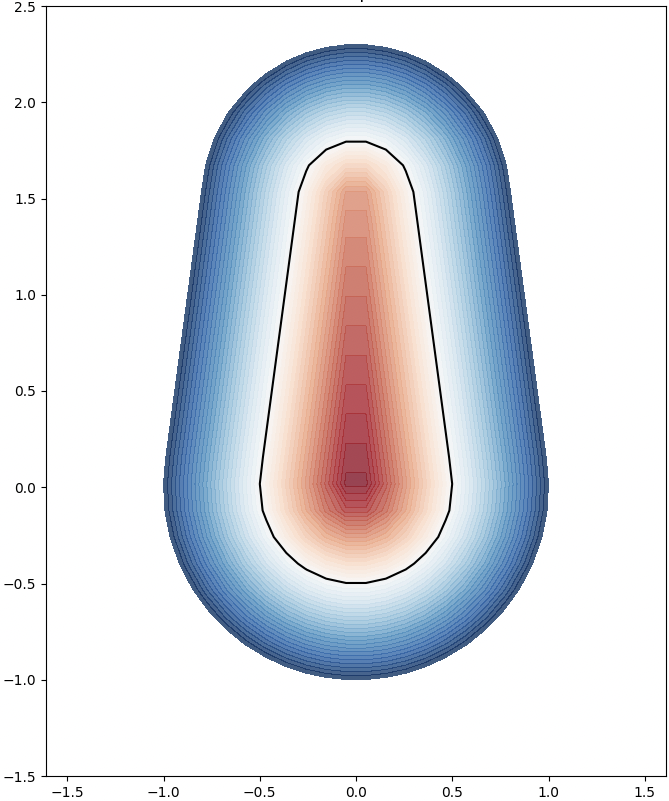
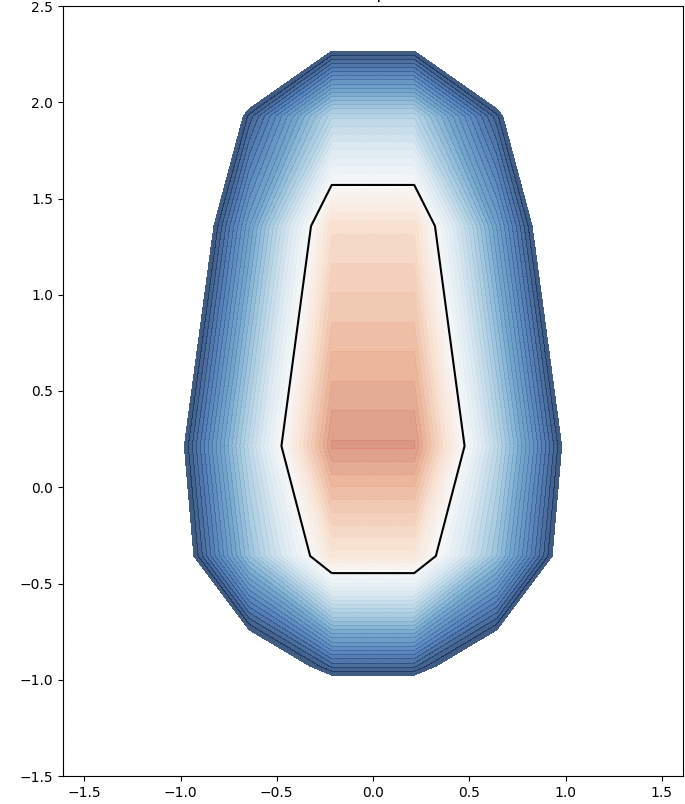
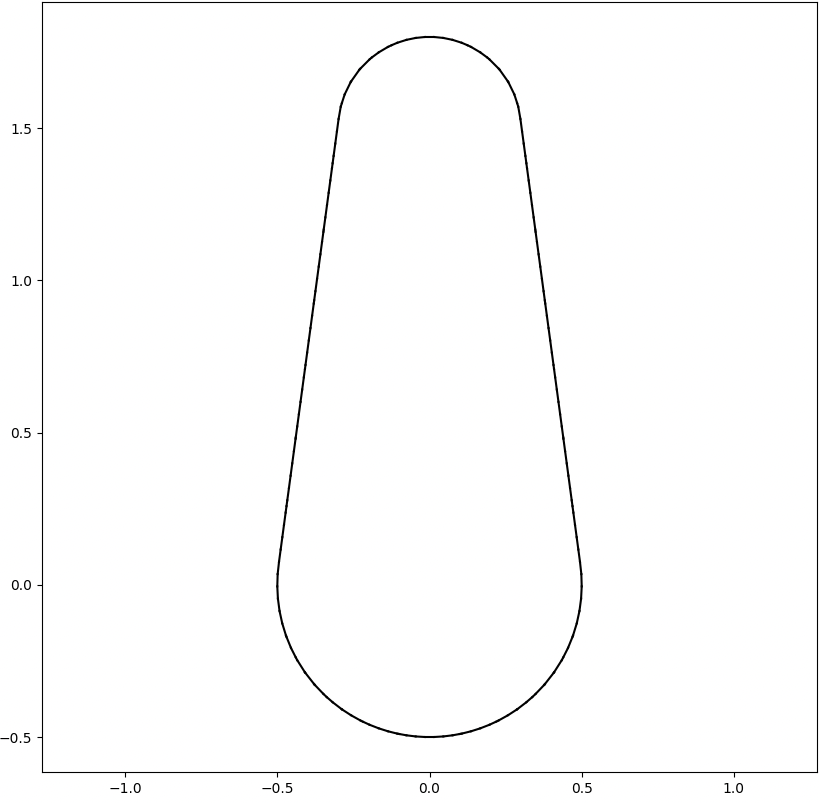
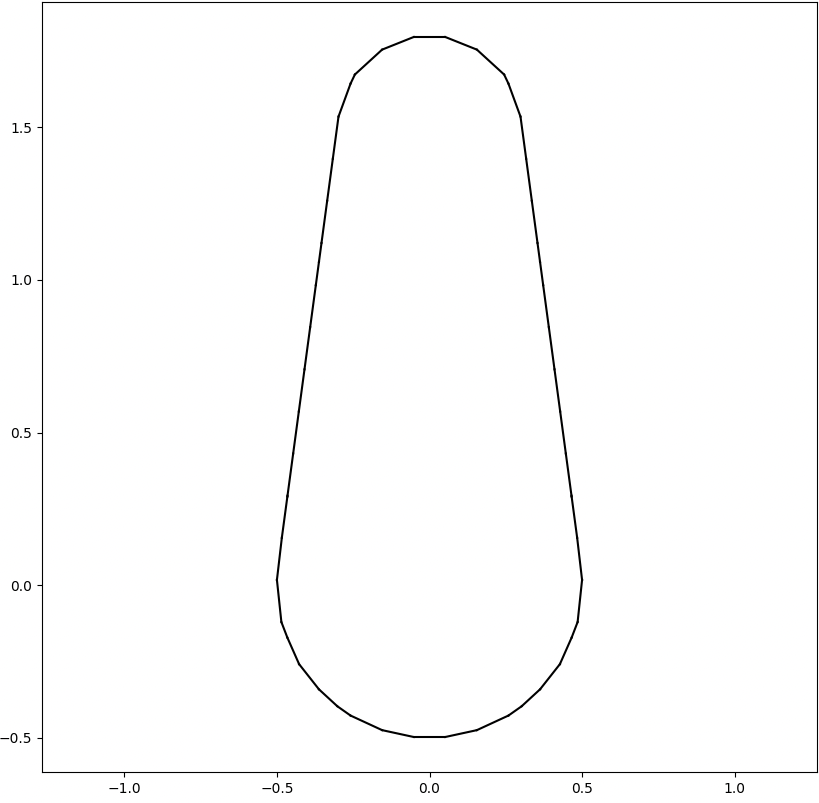
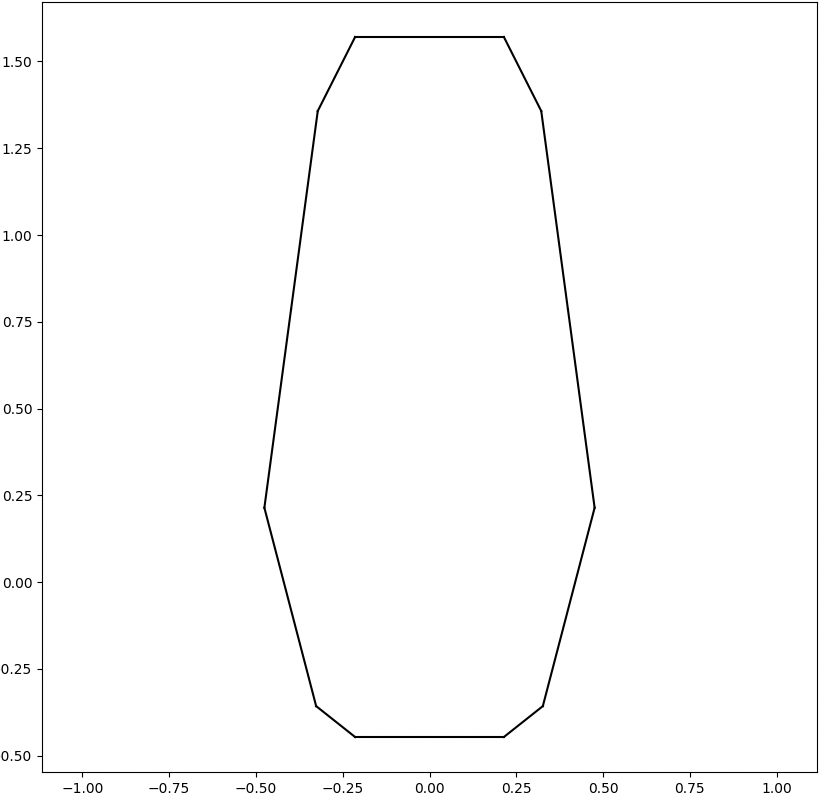
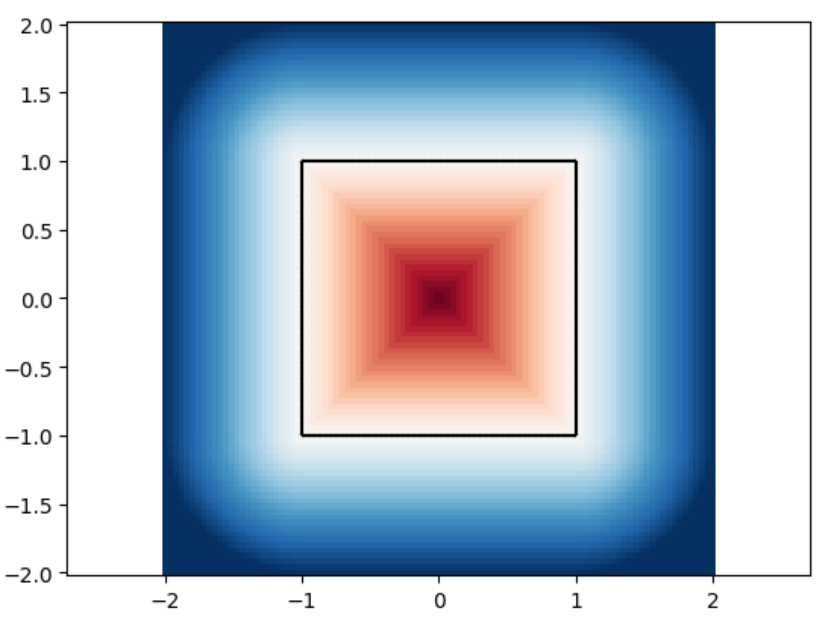
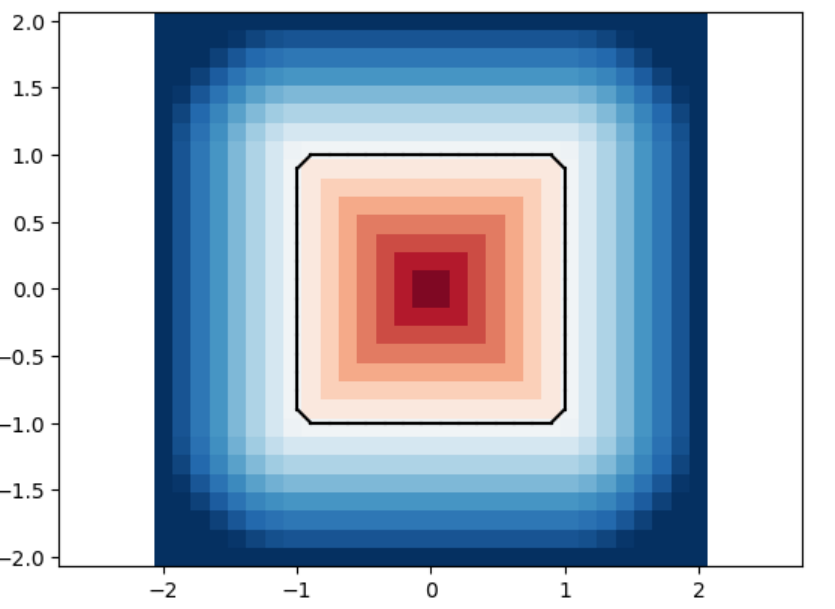
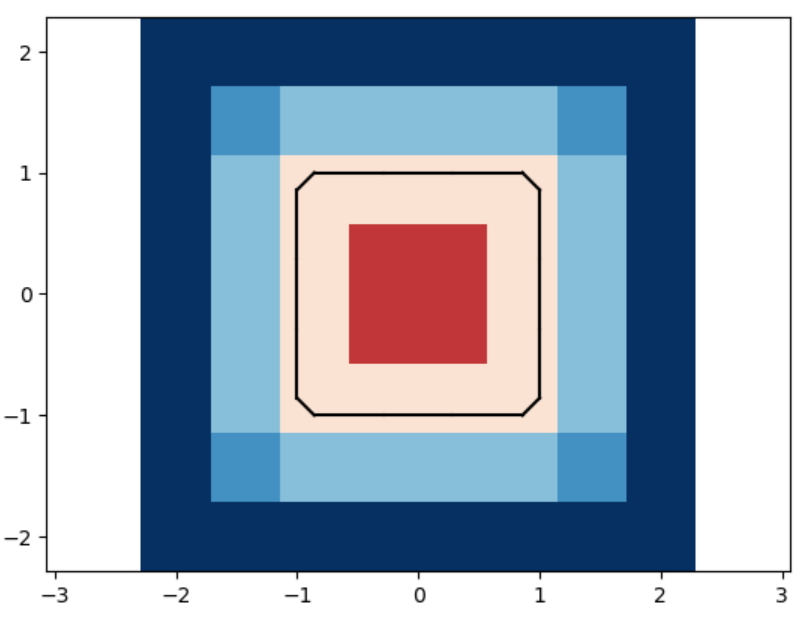
We analyze the Hausdorff distance for the uneven capsule (the shape on the right; exact sdf taken from there) in particular.

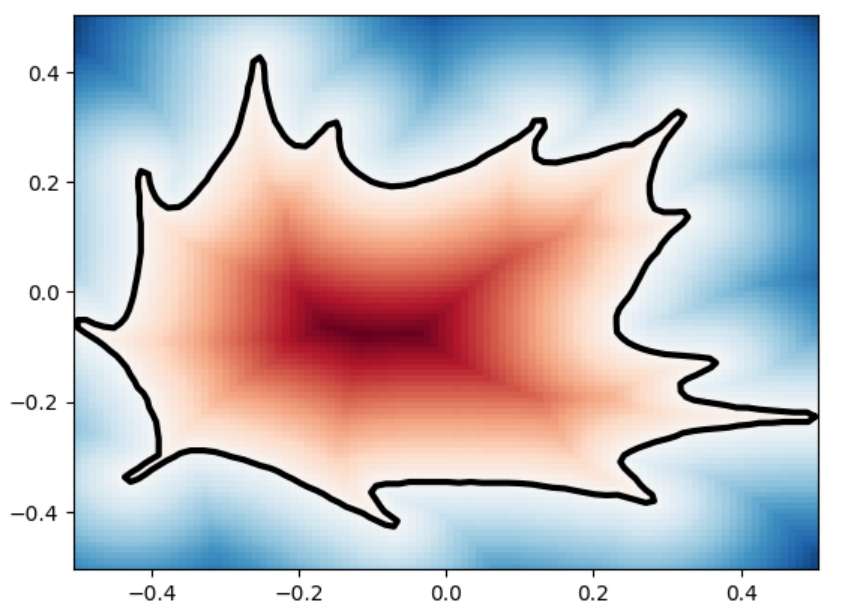
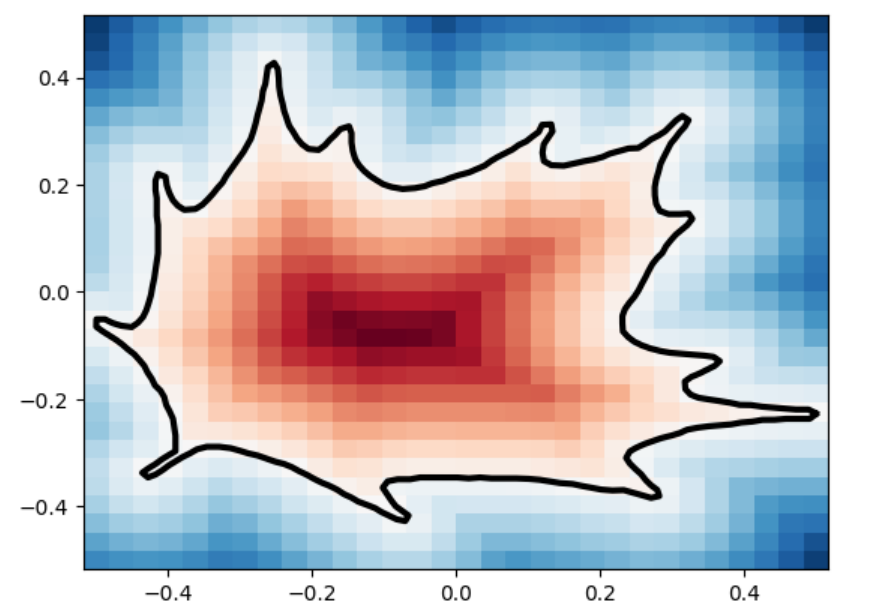
This plot visually compares the original zero level set (ground truth) with the reconstructed polyline generated by the marching squares algorithm at a specific resolution. The black dots represent the vertices of the polyline, showing how closely the reconstruction matches the ground truth, demonstrating the efficacy of the algorithm at capturing the shape’s essential features.

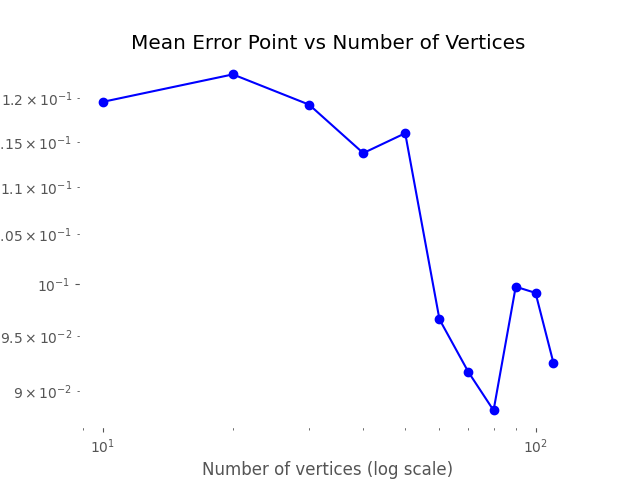
This plot shows the relationship between the Hausdorff distance and the resolution of the reconstruction. As resolution increases, the Hausdorff distance decreases, illustrating that higher resolutions produce more accurate reconstructions. The log-log plot with a linear fit suggests a strong inverse relationship, with the slope indicating a nearly quadratic decrease in Hausdorff distance as resolution improves.
Area Method for Error
Another error method we explored in this project is an area-based method. To start this process, we can overlay the original polyline and the generated polyline. Then, we can determine the area between the two, counting all regions as positive area. Essentially, this means that if we take values inside a polyline to be negative and outside a polyline to be positive, the area counted as error consists of the set of all regions where the sign of the original polyline’s SDF is not equal to the sign of the generated polyline’s SDF. The resultant area corresponds to the error of the reconstruction.
Here is a simple example of this area method using two quadrilaterals. The area between them is represented by their union (all blue area) with their intersection (the darker blue triangle) removed:

Here is an example of the area method applied to a star, with the area quantity corresponding to error printed at the top:

Inherent Error Function
We define the error function between the reconstructed polyline and the zero level set (ZLS) of a given signed distance function (SDF) as:
$$
\mathrm{Error}=\frac{1}{|S|} \sum_{s \in S} \mathrm{sdf}(s)
$$
Here, \(S\) represents a set of sample points from the reconstructed polyline generated by the marching squares algorithm, and \(|\mathrm{S}|\) denotes the cardinality of this set. The sample points include not only the vertices but also the edges of the reconstructed polyline.
The key advantage of this error function lies in its simplicity and directness. Since the SDF inherently encodes the distance between any query point and the original polyline, there’s no need to compute distances separately as required in Hausdorff or Chamfer distance calculations. This makes the error function both efficient and well-suited to our specific context, providing a more streamlined and integrated approach to measuring the accuracy of the reconstruction.
Note that one variant one can consider is to square the \(\mathrm{sdf}(s)\) part to get rid of the signed nature, because the signs can cancel with each other for the reconstructed polyline is not always entirely inside the ground truth or entirely cotains the ground truth.
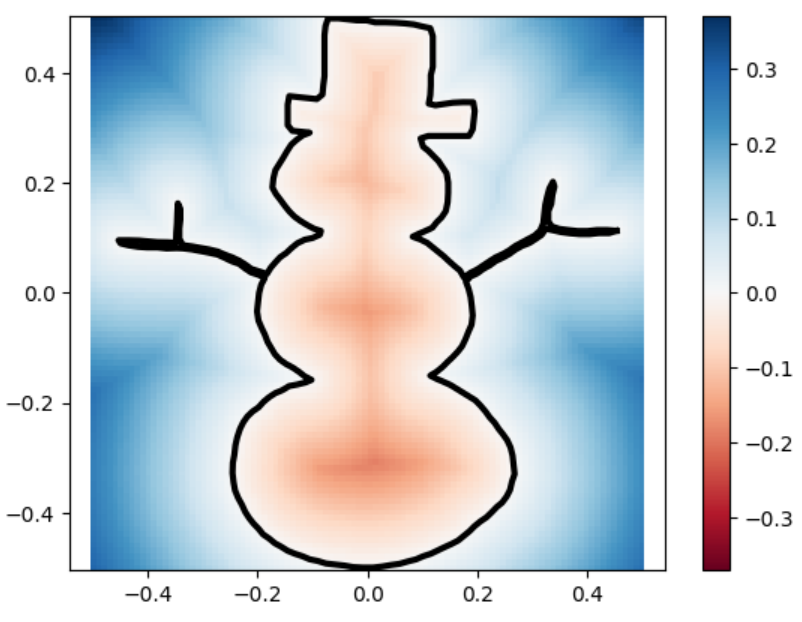
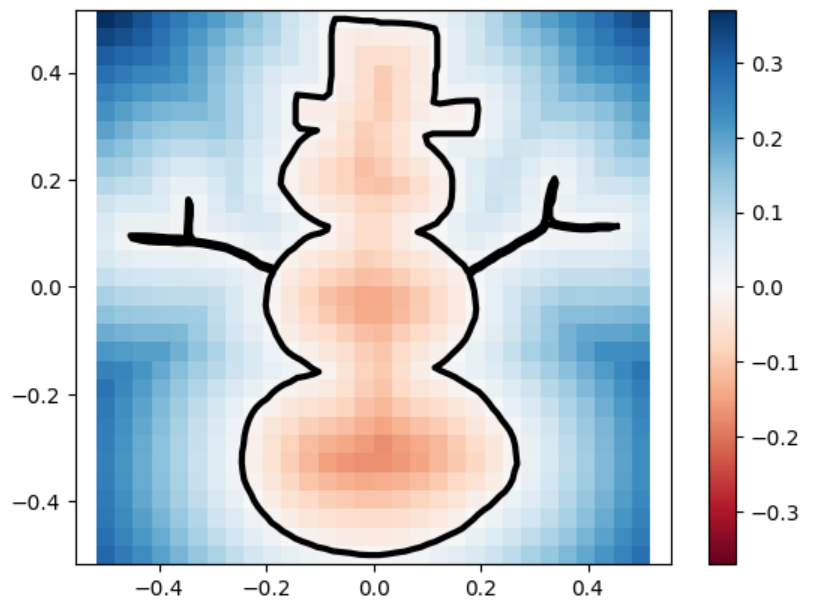
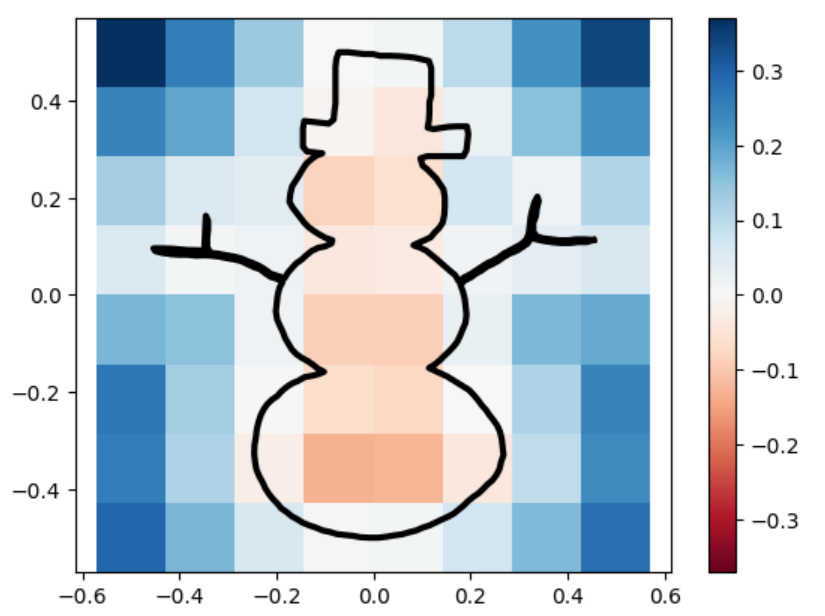
Below are one experiment we did for computing using this inherent error function, the unsquared one. We let the circle sdf be fixed and let the square sdf “escape” from the circle in a constant speed of \(0.2\). That is, we used the union of a fixed circle and a square with changing position as a series of shapes to do analysis. We then draw with color map used in this repo for the ground truths and the marching square results using the common color map.
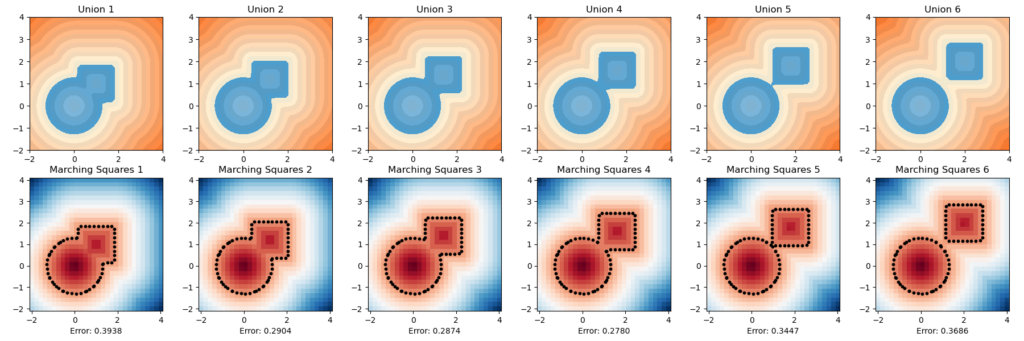
The inherent error of each union After several trials, one simple observation drawn from this escapaing motion is that when two shapes are more confounding with each other, as in the initial stage, the error is higher; and when the image starts to have two separated connected components, the error rises again. The first one can perhaps be explained by what the paper pointed out as pseudo-sdfs, and the second one is perhaps due to occurence of multipal components.
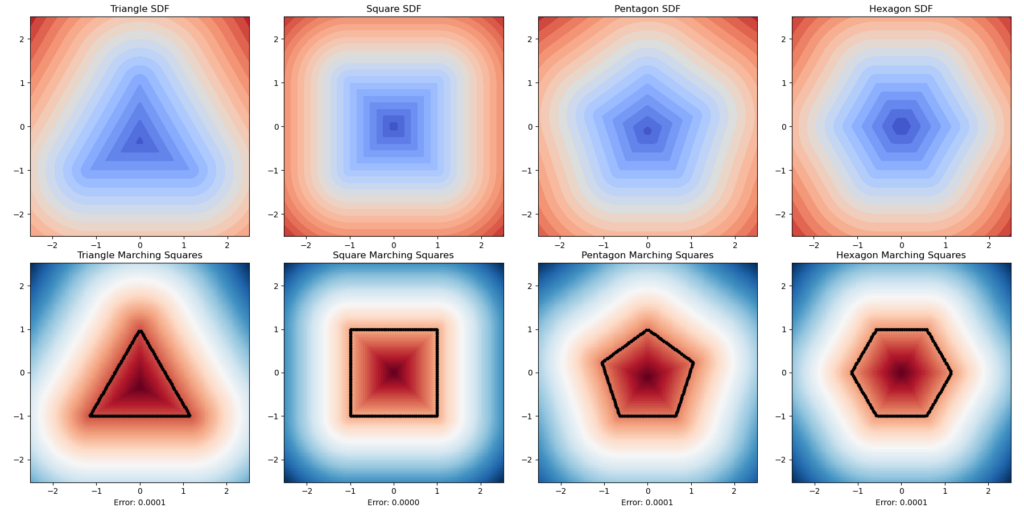
Here is another experiment. We want to know how well this method can simulate the physical characteristics of an object’s rugged level. We used a series of regular polygons. Although the result is theoretically unintheresting as the errors are all nearly zero, this is visually conformting.