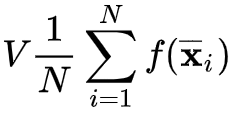Usually, we use neural networks to model complex and highly non-linear interactions between variables. A prototypical example is distinguishing pictures of cats and dogs.
The dataset consists of many images of cats and dogs, each labelled accordingly, and the goal of the network is to distinguish them in a way that can be generalised to unseen examples.
Two guiding principles when training such systems are underfitting and overfitting.
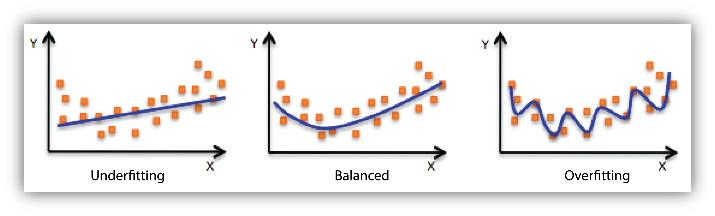
The first one occurs when our model is not “powerful enough” to capture the interaction we are trying to model so the network might struggle to learn even the examples it was exposed to.
The second one occurs when our model is “too powerful” and learns the dataset too well. This then impedes generalisation capabilities, as the model learns to fit exactly, and only, the training examples.
But what if this is a good thing?
Implicit Neural Representations
Now, suppose that you are given a mesh, which we can treat as a signed distance field (SDF), i.e. a function f : R3 \to R, assigning to each point in space its distance to the mesh (with negative values “inside” the mesh and positive “outside”).
This function is usually given in a discrete way, like a grid of values:

But now that we have a function, the SDF, we can use a neural network to model it to obtain a continuous representation. We can do so by constructing a dataset with input x = (x,y,z) a point in space and label the value of the SDF at that point.
In this setting, overfitting is a good thing! After all, we are not attempting to generalise SDFs to unseen meshes, we really only care about this one single input mesh (for single mesh tasks, of course).
But why do we want that?
We have now built a continuous representation of the mesh, and we can therefore exploit all the machinery of the continuous world: differentials, integration, and so on.
This continuous compression can also be used for other downstream tasks. For example, it can be fed to other neural networks doing different things, such as image generation, superresolution, video compression, and more.
There are many ways to produce these representations: choice of loss function, architecture, mesh representation…
In the next blog posts, we will discuss how we do implicit neural representations in our project.