Thanks to Ioannis Mirtsopoulos, Elshadai Tegegn, Diana Avila, Jorge Rico Esteban, and Tinsae Tadesse for invaluable assistance with this article.
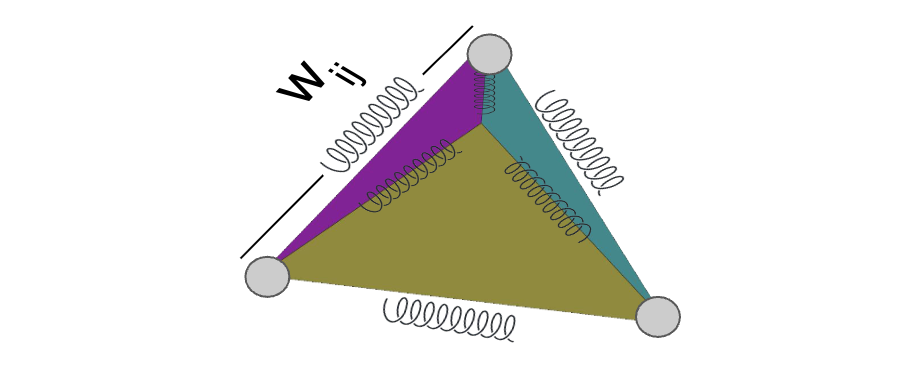
A truss is a collection of rigid beams connected together with joints which can rotate, but not slip by each other. Trusses are used throughout engineering, architecture, and other structural design; you’ll see them in railway bridges, supporting ceilings, and forming the foundation for many older roller coasters. When designing trusses, it is often necessary to design for static equilibrium; that is, such that the forces at each joint in the truss sum to zero, and the truss
does not move. One of the most effective ways to accomplish this is by parameterizing our graphs through the ratios between the axial force along each edge and the length of that edge. Our goal for this article is to show that these force-densities parametrize graphs in static equilibrium, subject to certain constraints.
The first constraint we will place upon our system is topological. Recall that a graph is a collection of vertices, together with a collection of edges linking pairs of those vertices. We will fix, once and for all, a graph \(G\) to represent the topology of our truss. We will also designate some of the vertices of our graph as fixed vertices and the rest as free vertices. The fixed vertices represent vertices which are attached to some solid medium external to the truss, and so experience normal forces which cancel out any forces which are present from the loading of the truss. In addition to these fixed vertices, to each free vertex we assign a load, which represents the force placed on that point.
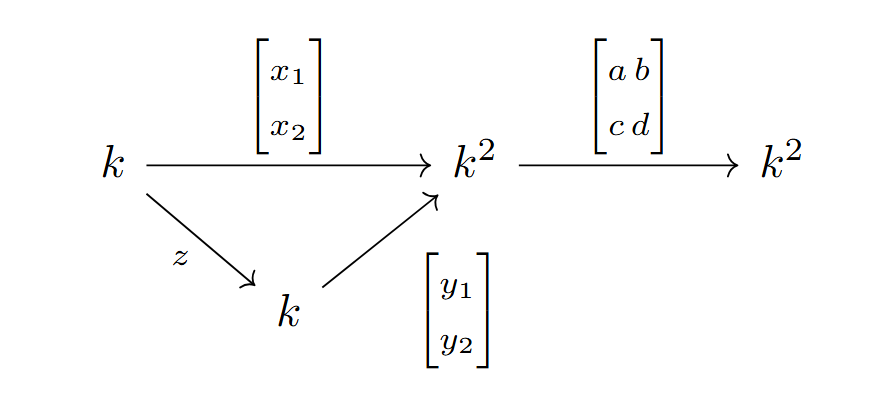
First we introduce the incidence matrix of a (directed)
graph. Recall that a directed graph where the edges have a destinguished ‘first’ vertex; that is, the edges are represented by ordered pairs rather than sets. Given such a graph, the incidence matrix of the graph is the matrix having in the \(i,j\)-th position a 1 if the \(i\)-th edge begins with the
\(j\)-th vertex, a \(-1\) if the \(i\)-th edge ends with the \(j\)-th vertex, and a 0 otherwise. We split the entire adjacency matrix \(A\) of our graph \(G\) into two matrices, \(C\) and \(C_f\), where \(C\) consists of the columns of \(A\) which correspond to free vertices, and \(C_f\) consists of those columns corresponding to fixed vertices. We will also work with the vectors \(p_x\) and \(p_y\) of forces, and
the vectors \(x_f\) and \(y_f\) of equilibrium points. We wish to construct a map \[F:\mathscr Q \to \mathscr C\]
where \(\mathscr Q\) is the space of vectors \(q = (q_1, …, q_n)\) of force-length ratios, and \(\mathscr C\) is the space of all possible lists of coordinate pairs \((x, y) = (x_1, …, x_n, y_1,
…, y_n)\). It turns out that the map we want is \[F(q) = \left(D^{-1}(p_x – D_fx_f), D^{-1}(p_y – D_fy_f)\right)\]
Where we set \(D = C^TQC, D_f = C^TQC_f\), and \(Q\) is the diagonal matrix with the \(q_i\) along the diagonal. Clearly, this map is a rational map in the \(q_i\), and is regular away from where \(\det(D) = 0\) (when viewed as a function of \(q\)).
Derivation
We suppose we have a system with free coordinate vectors \((x, y) = (x_1, …, x_n, y_1, …, y_n)\) and fixed coordinate vectors \((x_f, y_f) = (x_{1f}, …, y_{1f}, …)\) which is
in static equilibrium. First note that we can easily obtain the vectors of coordinate differences \(u\) and \(v\) (in the \(x\) and \(y\) directions respectively) using the incidence matrices \(C\) and \(C_f\).
\[u = Cx + C_fx_f\]
\[v = Cy + C_fy_f\]
We form the diagonal matrices \(U\) and \(V\) corresponding to \(u\) and \(v\), letting \(L\) be the matrix with the lengths of the edges down the diagonal and \(s\) the vector of axial forces along each edge. We note that if we divide the axial force along each edge by that edge’s length, and then multiply by the length in the \(x\) or \(y\) direction, we have then calculated the force that edge contributes to each vertex at it’s ends. Multiplying on the left by the transpose of the incedence matrix \(C\) then gives the total force on the vertex from all the bars coincident with it, which must then be
equal to the external load applied. This yields the equations
\[C^TUL^{-1}s = p_x,\ \ \ C^TVL^{-1}s = p_y,\]
which hold if and only if the system is in equilibrium. We define \(q=L^{-1}s\) to be the vector of force densities, simplifying our equations to
\[C^TUq = p_x,\ \ \ C^TVq = p_y.\]
We note that \(Uq = Qu\) and \(Vq=Qv\), by the definition of matrix multiplication (each matrix is a diagonal matrix!). Thus we obtain by the definitions of \(u\) and \(v\)
\[p_x = C^TUq = C^TQ(Cx+C_fx_f) = C^TQCx+C^TQC_fx_f, \]
\[p_y = C^TVq = C^TQ(Cy+C_fy_f) = C^TQCy+C^TQC_fy_f.\]
We set, as above, \(D = C^TQC\) and \(D_f = C^TQC_f\), yielding
\[p_x – D_fx_f= Dx , \]
\[p_y – D_fy_f= Dy ,\]
or as promised
\[D^{-1}(p_x – D_fx_f)=x ,\]
\[D^{-1}(p_y – D_fy_f)=y .\]
Clearly these equations hold if and only if the system is in equilibrium. Since every system (in equilibrium or not) has force densities, this yields an important corallary: Every system which is in equilibrium is of the form \(F(q)\) for some choice of force-density ratios \(q\), and no system which is not in equilibrium is of such a form.
It turns out to be incredibly useful to have this method to parametrize the set of all graphs in static equilibrium. This method is used to calculate the deformation of nets, cloth, and to design load-bearing trusses; it is also used to generate trusses based on particular design parameters. In
a later article we will also describe how one can use FDM to find an explicit representation for the set of possible point configurations which are in static equilibrium.





{kind=link}