As a woman from Ethiopia in the field of AI, I’ve often found myself navigating a world that wasn’t built with me in mind. From algorithms that struggle to recognize my face to datasets that don’t reflect my reality, the biases embedded in technology are not just abstract concepts to me, they are a part of my daily life. So, when I had the opportunity to listen to Olga Russakovsky’s talk on fairness in AI, it felt like a breath of fresh air. Here was a leading researcher in computer vision, not just acknowledging the problems I’ve seen, but dedicating her work to solving them.
The Unseen Biases in Our Everyday Tech
Olga’s talk started with a powerful premise: AI models are everywhere, and they are learning from a world that is far from equal. She shared some unsettling examples that I think everyone should know about. Have you ever used a “hotness filter” on a photo app? Olga pointed out that one such app was found to lighten users’ skin to increase “attractiveness”. Or consider the groundbreaking Gender Shades study by MIT’s Joy Buolamwini and Dr. Timnit Gebru, which Olga highlighted. Their work exposed how commercial facial recognition systems were significantly less accurate for Black women compared to white men.
These biases extend beyond just our faces; they encode cultural stereotypes. Olga showed how one major dataset’s idea of a “groom” is almost exclusively a white man in a tuxedo next to a woman in a puffy white dress. This isn’t a global truth; it’s a narrow, Western-centric view frozen into code and perpetuated by algorithms.
These aren’t just isolated incidents. They are symptoms of a deeper problem: the data we use to train our AI models is often skewed. As Olga explained, many of these datasets are overwhelmingly composed of images of people with lighter skin. This lack of diversity in the data leads to a lack of fairness in the technology built from it.
A World Beyond the West: The Geographic Bias in AI
What really hit home for me was Olga’s discussion of geographic bias. She showed a map of the world where the countries that contributed the most to a popular computer vision dataset were shaded darkest. The United States and Western Europe were dark, while the entire continent of Africa was almost invisible. This isn’t just about representation; it has real-world consequences. Olga gave a brilliant example of a commercial computer vision system that failed to recognize a bar of soap because it was primarily trained on images of liquid soap dispensers from higher-income US households.
Growing up in Ethiopia, I can tell you that a bar of soap is a far more common sight than a fancy liquid dispenser. This example might seem trivial, but it speaks to a much larger issue. If AI is trained on a narrow slice of the world, how can we expect it to serve the needs of a global population? It’s a question that keeps me up at night, and it’s why I’m so passionate about bringing my own perspective and experiences into this field.
So, What Can We Do About It?
Olga didn’t just leave us with the problems; she also talked about the solutions. And it’s not as simple as just collecting more data. While more representative datasets are a crucial first step, we also need to be creative with our algorithmic interventions. This means developing new techniques to train AI models to be fair, even when the data is not. It’s a complex challenge that requires a combination of technical skill, ethical consideration, and a deep understanding of the societal context in which these technologies are deployed.
But perhaps the most important solution, and the one that resonated with me the most, is the need for more diversity in the field of AI itself. Olga shared a personal story about how a robot she was working on during her PhD could understand everyone’s speech except for hers. It was her own lived experience of being an “outlier” in the data that sparked her interest in this research. This is why organizations like AI4ALL, which Olga co-founded, are so vital. Their mission is to educate and support a diverse next generation of AI leaders, because they know that the people who build AI will ultimately shape its future.
I loved how Olga closed this part of her talk with a dose of humility, reminding us that this work is a marathon, not a sprint. She said, “No dataset is perfect. No algorithm is perfect. Let’s give each other grace. Let’s keep moving forward.”. It’s a call for persistent, collective effort.
The Road Ahead
Olga’s talk was a powerful reminder that building fair and equitable AI is not just a technical problem, it’s a human one. It’s about who gets to be in the room, whose voices are heard, and whose experiences are valued. As I continue my journey in AI, I carry this with me. My background as a woman from Ethiopia is not a limitation; it is a strength. It gives me a unique perspective that is desperately needed in this field. The question Olga left us with is one I want to leave with you: AI will change the world, but who will change AI? I hope that you, like me, will be inspired to be a part of the answer.
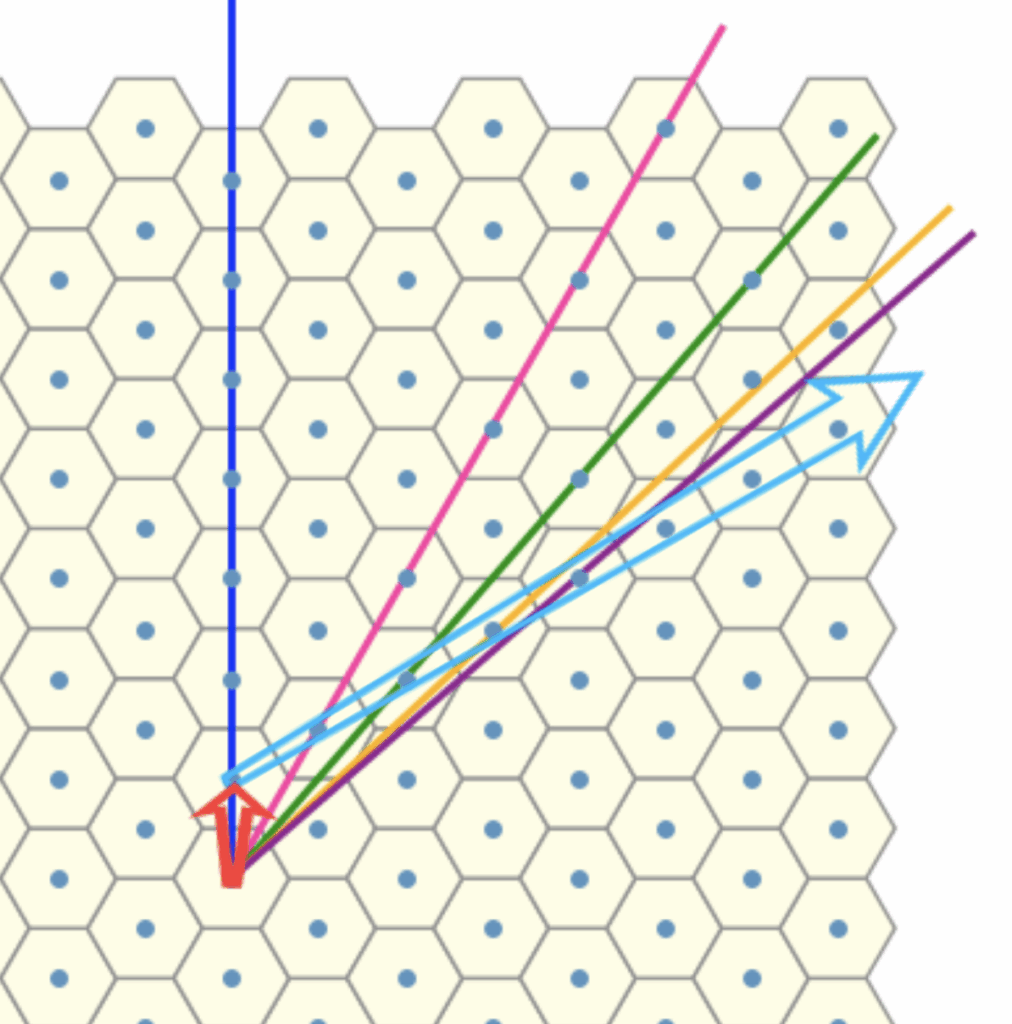
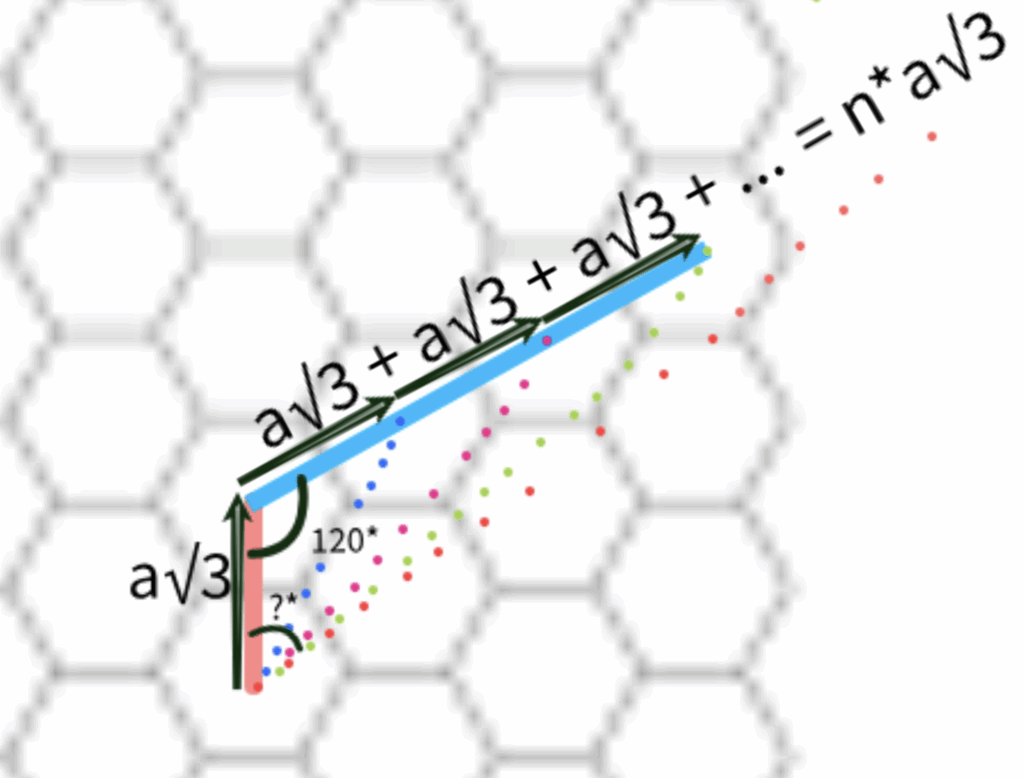
One will probably ask “what is even discrete morse theory?” A good question. But a better question is, “what is even morse theory?”
A Detour to Morse Theory
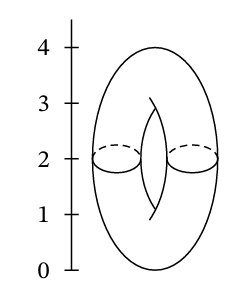
It would be a sin to not include this picture of a torus on any text for an introduction to Morse Theory.
Consider a height function \(f\) defined on this torus \(T\). Let \(M_z = \{x\in T | f(x)\le z\}\), i.e., a slice of the torus below level \(z\).
Morse theory says critical points of \(f\) can tell us something about the topology of the shape. The critical points can be determined by recalling from calculus that those points correspond to the points where the partial derivatives all equal zero. Then, the four critical points on the torus at heights 0, 1, 3, and 4 can be identified, each of which correspond to topological changes in the sublevel sets (\(M_z\)) of the function. In particular, imagine a sequence of sublevel sets \(M_z\) with ever increasing \(z\) values. Notice that each time we pass through a critical point, there is an important topological change in the sublevel sets.
At height 0, everything starts with a point
At height 1, a 1-handle is attached
At height 3, another 1-handle is added
Finally, at height 4, the maximum is reached, and a 2-handle is attached, capping off the top and completing the torus.
Through this process, Morse theory illustrates how the torus is constructed by successively attaching handles, with each critical point indicating a significant topological step.
Discretizing Morse Theory
Originally, Forman introduces discrete Morse Theory to let it inherit many similarities from its smooth counterpart, but it deals with discretized objects like CW complexes or a simplicial complex. In particular, we will focus on discrete morse theory on a simplicial complex.
Definition. Let \(K\) be a simplicial complex. A discrete vector field V on \(K\) is a set of pairs of cells \((\sigma, \tau) \in K\times K\), with \(\sigma\) a face of \(\tau\), such that each cell of \(K\) is contained in at most one pair of \(V\). Definition. A cell \(\sigma\in K\) is critical with respect to \(V\) if \(\sigma\) is not contained in any pair of \(V\).
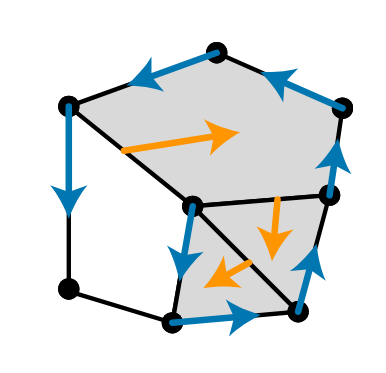
A discrete vector filed V can be readily visualized as a set of arrows like below.
Figure 1. The bottom left vertex is critical
Definition. Let \(V\) be a discrete vector field. A \(V\)-path \(\Gamma\) from a cell \(\sigma_0\) to a cell \(\sigma_r\) is a sequence \((\sigma_0, \tau_0, \sigma_1, \dots, \tau_{r-1}, \sigma_r)\) of cells such that for every \(0\le i\le r-1:\) $$ \sigma_i \text{ is a face of } \tau_i \text{ with } (\sigma_i, \tau_i \in V) \text{ and } \sigma_{i+1} \text{ is a face of } \tau_i \text{ with } (\sigma_{i+1}, \tau_i)\notin V. $$\(\Gamma\) is closed if \(\sigma_0=\sigma_r\), and nontrivial if \(r>0\).
Definition. A discrete vector field V is adiscrete gradient vector field if it contains no nontrivial closed V-paths.
Finally, with this in mind, we can define what properties should a Morse function satisfy on a given simplicial complex \(K\).
Definition. A function \(f: K\rightarrow \mathbb{R}\) on the cells of a complex K is a discrete Morse function if there is a gradient vector field \(V_f\) such that whenever \(\sigma\) is a face of \(\tau\) then $$ (\sigma, \tau)\notin V_f \text{ implies } f(\sigma) < f(\tau) \text{ and } (\sigma, \tau)\in V_f \text{ implies } f(\sigma)\ge f(\tau). $$\(V_f\) is called the gradient vector field of \(f\).
Definition. Let \(V\) be a discrete gradient vector field and consider the relation \(\leftarrow_V\) defined on \(K\) such that whenever \(\sigma\) is a face of \(\tau\) then $$ (\sigma, \tau)\notin V \text{ implies } \sigma\leftarrow_V \tau \text { and } (\sigma, \tau)\in V \text{ implies } \sigma\rightarrow_V \tau. $$ Let \(\prec_V\) be the transitive closure of \(\leftarrow_V\) . Then \(\prec_V\) is called the partial order induced by V.
We are now ready to introduce one of the main theorems of discrete Morse Theory.
Theorem. Let \(V\) be a gradient vector field on \(K\) and let \(\prec\) be a linear extension of \(\prec_{V}\). If \(\rho\) and \(\psi\) are two simplices such that \(\rho \prec \psi\) and there is no critical cell \(\phi\) with respect to \(V\) such that \(\rho\prec\phi\preceq\psi\), then \(\kappa(\psi)\) collapses (homotopy equivalent) to \(\kappa(\rho)\). Here, $$\kappa(\sigma) = closure(\cup_{\rho\in K; \rho\preceq\sigma}\rho)$$ an equivalent of sublevel set in the discrete setting.
This theorem says that given a gradient vector filed to a simplicial complex, and we consider how it is built over time by bringing each simplex in \(\prec\)’s order, then the topological changes happen only at the critical points determined by the gradient vector field. This strikingly is reminiscent of the case with the torus above.
This perspective is not only conceptually elegant but also computationally powerful: by identifying and retaining only the critical simplices, we can drastically reduce the size of our complex while preserving its topology. In fact, several groups of researchers have already utilized the discrete morse theory to simplify a function by removing topological noise.
Reference
Bauer, U., Lange, C., & Wardetzky, M. (2012). Optimal topological simplification of discrete functions on surfaces. Discrete & computational geometry, 47(2), 347-377.
Forman, R. (1998). Morse theory for cell complexes. Advances in mathematics, 134(1), 90-145.
Scoville, N. A. (2019). Discrete Morse Theory. United States: American Mathematical Society.
SGI Fellows: Melisa Oshaini Arukgoda, David Uzor, Lydia Madamopouloua, Joana Owusu-Appiah Mentors: Oliver Gross, Quentin Becker SGI Volunteer: Denisse Garnica
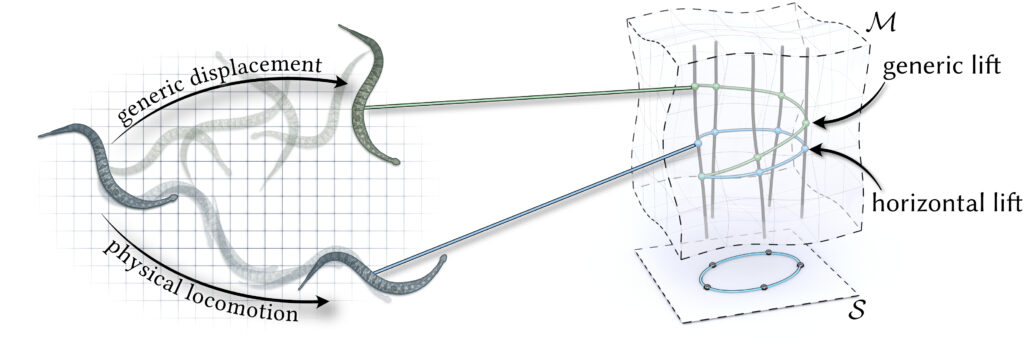
In Week 4 of SGI, we worked on a simulation project that built on the previous work of our Mentors Oliver Gross and Quentin Becker: motion from shape change and inverse geometric locomotion – to put it simply, identifying the sequence of shapes (gait) that a body will need to morph into in order to follow a specific path, without the influence of external forces. In nature, we see this behaviour in many different organisms: Stingrays, snails, Cats (when adjusting their position to allow them to land on their feet after falling), and snakes. Unlike standard physics-based simulations that rely on heavy Newtonian calculations of forces and accelerations, the approach we worked with reformulated the problem as an optimization over shape changes alone. By leveraging conservation laws through geometric mechanics, we could avoid full force-based simulations and instead compute efficient gaits directly — a shift that makes the process both faster and more generalizable.
Motion from Shape Change
Snake-like robots are fascinating because they don’t rely on wheels or legs for movement. Instead, they move by changing their shape over time. This type of motion is called geometric locomotion. By coordinating joint angles in a specific sequence, the robot can “slither” forward, turn, or even back up. Mathematically, we describe this by mapping changes in shape (joint angles) to displacements in space. The beauty of this approach is that the same principles apply whether the robot is operating on flat ground or navigating through more complex environments.
To simulate this, we used Python code that defines the joint angles, applies forward integration, and produces the resulting trajectory. By running sequences of positive and negative angles, we could generate gaits (movement patterns) and measure their effectiveness. Parameters like amplitude, phase shift, and anisotropy ratio all influence how efficient or smooth the motion becomes.
Inverse Geometric Locomotion
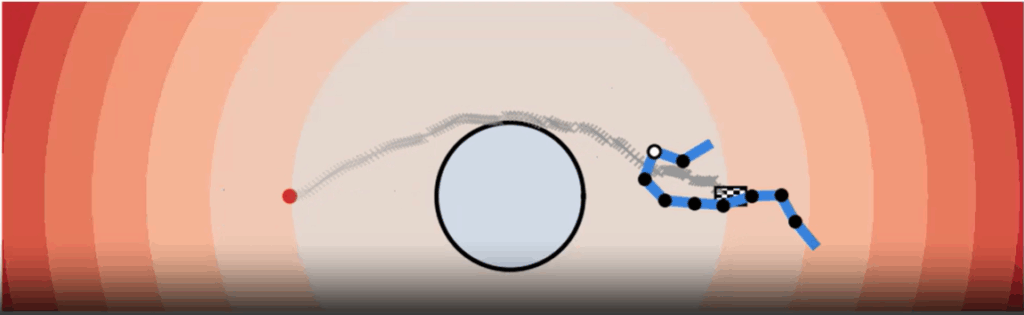
While forward motion planning tells us what happens when we execute a gait, inverse geometric locomotion helps us answer the opposite question: what shape sequence do we need to reach a target position or avoid an obstacle? This is formulated as an optimization problem. We define objectives such as “reach this point,” “avoid that obstacle,” or “turn left”, and then optimize the gait until the resulting motion matches the objective.
Here, the gradient descent optimization algorithm is applied to adjust the sequence of joint angles. Our experiments demonstrated that even when constraints are applied (such as broken joints or limited power), the robot can often still achieve meaningful locomotion by adapting its gait.
Breaking and Fixing Robots
One of the challenges with snake robots is robustness. What happens if a joint breaks? We simulated this by disabling certain joints and observing the effect. Unsurprisingly, the robot’s gait efficiency drops, but not all joints are equally important. Some failures severely reduce mobility, while others can be compensated for.
To “fix” the robot, we rerun the optimization process under the new constraints. By adapting the gait, the robot can still move, albeit with reduced performance. This kind of resilience is critical for real-world applications, where hardware failures are inevitable.
Avoiding Obstacles
Another core part of our experiments was obstacle avoidance. Instead of using explicit geometry, we represented obstacles as implicit functions (mathematical descriptions where the function is positive outside, negative inside, and zero at the boundary). This allows smooth and flexible definitions of obstacles of any shape.
The robot’s motion planner then ensures that the trajectory stays in the safe (positive) region. We tested this with different obstacle shapes and verified that the snake robot can successfully reconfigure its gait to slither around barriers.
Applications
This computational framework for inverse geometric locomotion opens doors for several interesting applications, particularly in the fields of animation and robotics. The video below shows the snake robot in action (courtesy of the MiniRo Lab at the University of Notre Dame), loaded with the shape sequences from the simulation.
🎭 A Tale of Two Transports: A Comic Drama in Three Acts 🎭
Dramatis Personae
King Louis XVI — monarch of France; dislikes chaos and prefers order.
Peasant — voice of everyday inefficiency.
Gaspard Monge — French mathematician; formulates transport as a deterministic map with elegant clarity.
Party Official — a bureaucrat, loves words like “plan.”
Leonid Kantorovich — Soviet mathematician; introduces the convex relaxation that makes transport broadly solvable.
Yann Brenier — mathematician; shows when the optimal plan is in fact a gradient map of a convex potential.
Act I — A Village in France, 1780
Scene: Grey dawn. Carts piled with wheat creak by; a boy staggers under chiming milk pails; two men shoulder grapes toward a wine press heroically far from grapes. Chickens run quality assurance on everyone’s ankles. A Peasant collapses onto a sack. Enter Louis XVI, in a plain cloak, incognito, attempting “peasant walk.”
👑 Louis XVI(softly, to himself): Ah, the countryside—so tranquil. (A wheelbarrow nearly flattenedhim.) … Enchanting.
“Pourquoi,” the Louis XVI asked a peasant who had stopped to breathe—and to reconsider his life choices—“is everyone running like headless hens? Why must you drag wheat halfway across France?”
👨🌾Peasant (gasping): New regulations—( he does not recognize him)—each farm must send all its wheat to the Rouen mill. Jean’s milk goes all beyond the river. Pierre’s grapes go all to that press on Mount Ridicule. Each farm is assigned to a factory regardless of whether it’s nearby or not. It is the system.
👑 Louis XVI(deadpan):System. Like umbrellas made of lace.
👨🌾 Peasant: They call it “Rational Logistics.” The rational part is the paperwork. The logistics we do on foot.
👑 Louis XVI: And why not send wheat to the nearest mill?
👨🌾Peasant: Nearest? (laughs, a little unwell) The Committee for Extended Journeys of Grain has determined “nearest” is bourgeois. We ship by destiny, not distance.
👨🌾Peasant (rising, grimly cheerful): Must be off. My route goes past Rouen, then back past here, then past my grave, then the mill.
👑 Louis XVI: Bon voyage. (beat) And bon sens… someday.
The Peasant trundles away, pursued by chickens. The King stares at the chaos like a man realizing his kingdom is a long proof with a missing lemma. He turns on his heel.Exit Louis XVI.
At the Royal Palace
Scene: A long table buried in maps. Brass compasses glint. Officials murmur in hexagons, puzzled. Enter Monge, ink on cuffs; Louis XVI presides.
👑 Louis XVI(curt): The villages in France are ruled by chaos. Help us fix it.
Monge (with the unstoppable serenity of a man who believes the world can be improved by equations.): The problem is assigning yields (wheat, milk, grapes) from farms in France to the appropriate factories (flour mills, dairies, wine presses) at minimal total transport cost. That is optimal transport similar to the one with mines and factories that I was working on. Let me show you how to solve it with wheat and mills.
Monge (to Louis XVI): Let us treat the country map as two mathematical worlds: \(X\) for farms and \(Y\) for mills. Plainly, \(Y\) and \(X\) are just set of points on your map (farm and mill locations), and any blob you can draw around those points is a region in which we might count wheat or capacity.
Precisely, take \(X\) and \(Y\) \( \in \mathbb{R}^2 \) (the plane of the map) and equip them with their restricted Borel \(\sigma\) -algebras: \[ \mathcal{B}_X:=\{U\cap X:\ U\text{ open in }\mathbb{R}^2\},\qquad \mathcal{B}_Y:=\{V\cap Y:\ V\text{ open in }\mathbb{R}^2\}. \] And there you have two measurable spaces: \((X,\mathcal{B}_X)\) and \((Y,\mathcal{B}_Y)\)
These \(\sigma\)-algebras specify which regions count as the measurable regions on which amounts can be tallied; the individual farm/mill points are measurable singletons and will serve as atoms.
Atomic data and finite Borel measures. Given farms at points \(x_i\in X\) with supplies \(s_i\ge0\) and mills at points \(y_j\in Y\) with capacities \(d_j\ge0\), define finite Borel measures (here \(\delta_x\) is the Dirac unit mass at \(x\)): \[ \tilde\mu=\sum_i s_i \, \delta_{x_i}\\ \text{on}(X,\mathcal{B}_X), \qquad \tilde\nu=\sum_j d_j \, \delta_{y_j} \ \\text{on }(Y,\mathcal{B}_Y). \] Assume mass balance \(\tilde\mu(X)=\tilde\nu(Y)=:S\in(0,\infty)\).
Normalize for clean bookkeeping. For cleaner formulas set \[ \mu:=\tilde\mu/S=\sum_i \frac{s_i}{S}\,\delta_{x_i},\qquad \nu:=\tilde\nu/S=\sum_j \frac{d_j}{S}\,\delta_{y_j}, \] so \(\mu(X)=\nu(Y)=1\).
Interpretation: \(\mu(A)\) is the fraction of national wheat in \(A\subset X\), and \(\nu(B)\) the fraction of national milling capacity in \(B\subset Y\). (Normalization rescales costs by \(S\).)
In this problem, we can work with a purely discrete model; We only care about the finitely many sites, thus we may take \[ X={x_1,\dots,x_m},\ \mathcal{B}_X=2^X,\qquad Y={y_1,\dots,y_n},\ \mathcal{B}_Y=2^Y, \] the power-set (\sigma\)-algebras.
Monge (drawing crisp arrows):Next, we declarea measurable, lower semicontinuous cost rule \(c:X\times Y\to[0,\infty]\); typical choices are \(c(x,y)=|x-y|\) or \(c(x,y)=\frac{1}{2} \|x-y\|^2\). The per–unit bill to haul from \(x\) to \(y\) is \(c(x,y)\).
Monge continues .. Then my principle is: one farm, one address via a map \(T:X\to Y\) Each farm sends all its wheat to exactly one mill. Mathematically, this means we find a measurable map \(T:X\to Y\) with the pushforward constraint \(T_{\#}\mu=\nu\) minimizing \[ \ \min_{T_{\#}\mu=\nu}\ \int_X c\big(x,T(x)\big)\,d\mu(x)\ \quad\text{(no splitting of mass).} \] Probabilistic reading: if \(X\sim\mu\) and \(Y:=T(X)\), then \(Y\sim\nu\); the induced coupling is concentrated on the graph \({(x,T(x))}\).
👑 Louis XVI (applauding): One clean arrow from each farm to one mill. Very elegant. Very royal. Also, occasionally disastrous—like sending three tons from one farm to a single mill that can only swallow one.
Monge (unruffled): My constraint really is what it says: a map does not split atoms of mass. Elegance has limits.
Act II — Moscow, 1939
Scene: A Soviet planning office. Maps of farms and bread factories wallpaper the room. A portrait watches. A heavy desk. A heavier silence. Party Official sits; a clerk guards a terrifying spreadsheet. Enter Kantorovich, notebook in hand.
☭ Party Official (to Kantorovich): Wheat moves. Bread appears. Costs explode. Could you explain how the first two can occur without the third?
🧮 Kantorovich: Hmm, it is the Monge’s French approach to optimal transport. This method allows only one-to-one assignments — a farm to a single factory. It is beautiful—like a court etiquette manual. It also breaks the budget when capacities don’t line up.
☭ Official: Examples?
🧮 Kantorovich: Farm A has 2 tons; Mill 1 and Mill 2 each need 1 ton. Monge’s rule can’t split A—so either we overflow a mill or we ship the extra far away at great cost. It is time we shall stop assigning by etiquette and start assigning by fractions. One farm’s harvest may be shared among Leningrad, Moscow, and Kiev (several mills). No drama, no lace.
☭ Official (suspicious): Shared? You propose to slice the wheat like bourgeois cake?
🧮 Kantorovich (calmly): Not cake—convexity.
☭ Official: Could you explain your method. How do we schedule wheat to mills?
🧮 Kantorovich: We keep the same data: farms live in \(X\) with supply measure \(\mu\), mills live in \(Y\) with capacity measure \(\nu\), and \(c(x,y)\) is the per–unit haul cost. Normalize so \(\mu(X)=\nu(Y)=1).\)
We will not do a single address per farm, but a plan \(\pi\): it tells what fraction of wheat goes from each farm \(x\) to each mill \(y\). Mathematically, \(\pi\) is a measure on \(X\times Y\) with the correct row and column totals (marginals): \[\Pi(\mu,\nu):=\Big\{\pi\text{ on }X\times Y:\ \pi(A\times Y)=\mu(A),\ \ \pi(X\times B)=\nu(B)\ \ \forall A\in\mathcal B_X,\ B\in\mathcal B_Y\Big\}.\]
Spreadsheet intuition: rows = farms, columns = mills; the entry \(\pi(x,y)\) is the fraction shipped \(x\to y\). Row sums match \(\mu\) (every farm ships all its wheat); column sums match \(\nu\) (every mill is filled exactly).
☭ Official: And we choose \(\pi\) how?
🧮 Kantorovich: By minimizing the national bill (the expected cost under \(\pi)\):
\[ \min_{\pi\in\Pi(\mu,\nu)} \ \int_{X\times Y} c(x,y)\,d\pi(x,y)\ \qquad \text{(mass may split).}\]
If the country’s total wheat is \(S\) tons (before normalization), the physical cost is \(S!\int c\,d\pi\).
☭ Official: Why is this reliable?
🧮 Kantorovich: Because the feasible set \(\Pi(\mu,\nu)\) is convex (mixtures of schedules are schedules) and the objective is linear in \(\pi\). On reasonable spaces \(Polish (X,Y)\) (e.g.\ subsets of \(\mathbb R^2\)) with a lower semicontinuous cost \(c\) (no sudden discounts), an optimal plan exists. Always.
☭ Official (nodding): Fractions in the boxes, rows = supply, columns = demand, minimize the sum. No lace.
🧮 Kantorovich (smiles): Exactly. More bread, fewer marathons.
☭ Official: And how do we know which roads actually carry wheat? I dislike paying for decorations.
🧮 Kantorovich: We use shadow prices. Assign a number to each farm and each mill: \[ \varphi:X\to\mathbb R\quad(\text{farms}),\qquad \psi:Y\to\mathbb R\quad(\text{mills}), \] with the global no-underpricing rule \[ \varphi(x)+\psi(y)\le c(x,y)\quad\text{for all }(x,y). \] Then we maximize the total value \[ \sup_{\varphi,\psi}\ \Big(\int_X \varphi\,d\mu+\int_Y \psi\,d\nu\Big)\ \text{ subject to }\ \varphi+\psi\le c\ . \] Strong duality holds: this supremum equals the minimal transport cost. At the optimal schedule \(\pi^\ast\), \[ \varphi^\ast(x)+\psi^\ast(y)=c(x,y)\quad\text{for }\pi^\ast\text{-a.e. }(x,y), \] so wheat flows only on tight routes. Overpriced routes carry no flow.
☭ Official: Good. Prices that turn lights on where grain should move. When do we get back to one arrow per farm?
🧮 Kantorovich: When nature is kind. If supply isn’t all concentrated at points and the cost rewards straight, nearby routes, the best schedule often behaves like a single address per source—effectively a map. But that conclusion belongs to future mathematics, Comrade; today we use the plan.
☭ Official: And what do the clerks actually compute while I frown at the portrait?
🧮 Kantorovich: A linear program. With farms \(i\), mills \(j\), shipments \(x_{ij}\ge0\), costs \(c_{ij}=c(x_i,y_j)\): \[ \begin{aligned} \min_{x_{ij}\ge0}\quad & \sum_{i,j} c_{ij}\,x_{ij} \ \text{s.t.}\quad & \sum_j x_{ij}=s_i\quad(\text{ship all supply}),\qquad \sum_i x_{ij}=d_j\quad(\text{fill all mills}). \end{aligned} \] Normalize by \(S=\sum_i s_i): (\pi_{ij}:=x_{ij}/S\) is a discrete coupling in \(\Pi(\mu,\nu)\) and \(\sum c_{ij}x_{ij}=S\int c\,d\pi\). They can solve it by transportation algorithms; your signature appears only at the end.
☭ Official(closing the file): Prices to light the roads, plans to split the loads, and arrows when the heavens permit. Acceptable.
🧮 Kantorovich(dry): Monge when you can, coupling when you must. Either way, warm bread—without marathons.
The clerk exhales. The portrait approves. The spreadsheet looks slightly less terrifying.
Act III — Paris, 1991
Scene: Seminar room; chalk dust in sunbeams. A blackboard already half-conquered. Enter Yann Brenier, chalk in hand. In the back row sit two ghosts: Monge (with a ruler) and Kantorovich (with a ledger).
Brenier (calm, to the room): Suppose our cost is the squared distance, \[ c(x,y)=\frac{1}{2}\|x-y\|^2, \] and the country’s wheat is not piled into atoms but spread with a density (i.e., \(\mu\) is absolutely continuous). Then the optimal transport is not merely a schedule—it is a map. More precisely:
Brenier’s Theorem (1991). Let \(\mu,\nu\) be probability measures on \(\mathbb{R}^d\) with finite second moments, and assume \(\mu\ll \mathrm{Leb}\) (no atoms). For \(c(x,y)=\tfrac12|x-y|^2\), there exists a (a.e.\ unique) optimal Monge map \[ \boxed{\,T=\nabla \Phi\,} \] for some convex potential \(\Phi:\mathbb{R}^d\to\mathbb{R}\cup{+\infty}\), and the optimal plan is concentrated on its graph: \[ \pi^\ast=(\mathrm{id},T)_{\#}\mu . \]
Finite second moments: \(\int |x|^2\,d\mu(x)<\infty\) and \(\int |y|^2\,d\nu(y)<\infty\). This says the average squared distance of mass from the origin is finite (a finite “moment of inertia”). It guarantees that the quadratic transport cost \(\int \tfrac12|x-y|^2\,d\pi\) can be finite for some coupling \(\pi\).
Absolute continuity of \(\mu\): no single point of \(X\) carries positive mass. Physically, the supply is a density, not a pile of atoms. This prevents a point-mass from being forced to split and allows the optimal coupling to be given by a function \(T\) rather than a multivalued plan.
Quadratic cost: the geometry of \(\tfrac12|x-y|^2\) forces optimal couplings to be (c)-cyclically monotone; such sets are subdifferentials of convex functions. This is the mechanism that produces \(T=\nabla\Phi\).
Brenier (sketches gradient arrows): Think of \(\Phi\) as a convex landscape over the country. At location \(x\), the arrow \(\nabla\Phi(x)\) points “straight uphill.” My theorem says: for squared-distance cost and a smooth supply, the cheapest rearrangement sends each infinitesimal grain along these gradient arrows to its unique destination \(T(x)\). Convexity forbids cost-lowering cycles; gradients do not swirl. Each farm-point \(x\) sends its infinitesimal mass along \(\nabla\Phi(x)\) to a unique mill \(T(x)\). No crossings, no marathons.
Monge (ghost, delighted): Une fl`eche par point. The arrows return!
🧮 Kantorovich (ghost, approving): Through a convex potential—my ledger smiles.
Consequences (when densities exist). If \(\mu=\rho(x)\,dx\) and \(\nu=\sigma(y)\,dy\), then \(\Phi\) solves, in the weak (a.e.) sense, the Monge–Amp`ere equation \[ \det\big(\nabla^2\Phi(x)\big)=\frac{\rho(x)}{\sigma\big(\nabla\Phi(x)\big)}\,, \qquad\text{and}\qquad T_{\#}\mu=\nu . \] The displacement interpolation \[ \mu_t:=\big((1-t)\,\mathrm{id}+t\,T\big)_{\#}\mu,\qquad t\in[0,1], \] is a constant-speed geodesic in the 2-Wasserstein space \(W_2(\mathbb{R}^d)\) between \(\mu\) and \(\nu\).
Short answer to why. Optimal couplings for the quadratic cost are (c)-cyclically monotone; Rockafellar’s theorem puts such sets inside the subdifferential \(\partial\Phi\) of a convex \(\Phi\). Absolute continuity of \(\mu\) makes \(\partial\Phi\) single-valued \(\mu\)-a.e., yielding \(T=\nabla\Phi\) (existence and uniqueness).
Brenier drops the chalk. The ghosts exchange a courteous bow: arrows for Louis XVI, convexity for the Bureau. Outside, somewhere, peasants are happy, and there is enough bread to feed the kingdom.
Acknowledgments. I’m grateful to professor Nestor Gullen, who introduced me to the main ideas of optimal transport during my time as a volunteer assistant on his Algorithms for Convex Surface Construction project. Many thanks to research fellows Stephanie Atherton; Matthew Hellinger; Minghao Ji; Amar KC; Marina Oliveira Levay Reis, for being a joy to work with—curious, rigorous, and creative, and to professor Justin Solomon as well for assigning me this project, and making SGI awesome.
Historical note & disclaimer
This tale is fictional. The conversations attributed to Louis XVI, Gaspard Monge, and Leonid Kantorovich are the product of the author’s imagination.
SGI Fellows: Lydia Madamopoulou, Nhu Tran, Renan Bomtempo and Tiago Trindade Mentor. Yusuf Sahillioglu SGI Volunteer. Eric Chen
Introduction
In the world of 3D modeling and computational geometry, tackling geometrically complex shapes is a significant challenge. A common and powerful strategy to manage this complexity is to use a “divide-and-conquer” approach, which partitions a complex object into a set of simpler, more manageable sub-shapes. This process, known as shape decomposition, is a classical problem, with convex decomposition and star-shaped decomposition being of particular interest.
The core idea is that many advanced algorithms for tasks like creating volumetric maps or parameterizing a shape are difficult or unreliable on arbitrary models, but work perfectly on simpler shapes like cubes, balls, or star-shaped regions.
The paper by Hinderink et al. (2024) demonstrates this perfectly. It presents a method to create a guaranteed one-to-one (bijective) map between two complex 3D shapes. They achieve this by first decomposing the target shape into a collection of non-overlapping star-shaped pieces. By breaking the hard problem down into a set of simpler mapping problems, they can apply existing, reliable algorithms to each star-shaped part and then stitch the results together. Similarly, the work by Yu & Li (2011) uses star decomposition as a prerequisite for applications like shape matching and morphing, highlighting that star-shaped regions have beneficial properties for many graphics tasks.
Ultimately, these decomposition techniques are a foundational tool, allowing researchers and engineers to extend the reach of powerful geometric algorithms to handle virtually any shape, no matter how complex its structure. Some applications include:
Guarding and Visibility Problems. Star decomposition is closely related to the 3D guarding problem: how can you place the fewest number of sensors or cameras inside a space so that every point is visible from at least one of them? Each star-shaped region corresponds to the visibility range of a single guard. This is widely used in security systems, robot navigation and coverage planning for drones.
Texture mapping and material Design. Star decomposition makes surface parameterization much easier. Since each region is guaranteed to be visible from a point, its much simpler to unwrap textures (like UV mapping), apply seamless materials and paint and label parts of a model.
Fabrication and 3D printing. When preparing a shape for fabrication, star decomposition helps with designing parts for assembly, splitting objects into printable segments to avoid overhangs. It’s particularly useful for automated slicing, CNC machining, and even origami-based folding of materials.
Shape Matching and Retrieval. As mentioned in Hinderink et al. (2024), matching or searching for shapes based on parts is a common task. Star decomposition provides a way to extract consistent, descriptive parts, enabling sketch-based search, feature extraction for machine learning, and comparison of similar objects in 3D data sets.
In this project, we tackle the problem of segmenting a mesh into star-shaped regions. To do this, we explore two different approaches to try to solve this problem:
An interior based approach, where we use interior points on the mesh to create the mesh segments;
A surface based approach, where we try to build the mesh segments by using only surface information.
We then discuss results and challenges of each approach.
What is a star-shape?
You are probably familiar with the concept of a convex shape, that is a shape such that any two points on inside or on the boundary can be connected by straight line without leaving the shape. In simpler terms we can say that a shape is convex if any point inside it has a direct line of sight to any other point on its surface.
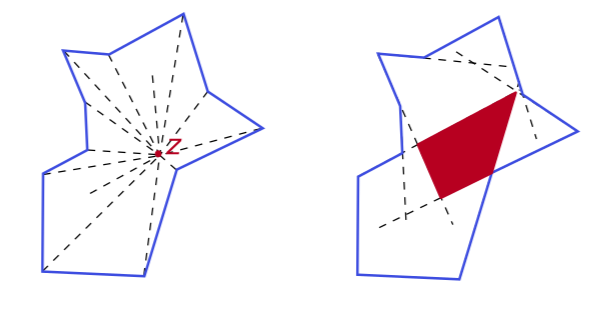
Now a shape is called star-shaped if there’s at least one point inside it from which you can see the entire object. Think of it like a single guard standing inside a room; if there’s a spot where the guard can see every single point on every wall without their view being blocked by another part of the room, then the room is star-shaped. This point is called a kernel point, and the set of all possible points where the guard could stand is called the shape’s visibility kernel. If this kernel is not empty, the shape is star-shaped.
On the left we see an irregular non-convex closed polygon where a kernel point is shown along with the lines that connect it to all other vertices.
On the right we now show its visibility kernel in red, that is the set of all kernel points. Also, it is important to note that the kernel may be computed by simply taking the intersection of all inner half-planes defined by each face, i.e. the half-planes of each face whose normal vector points to the inside of the shape.
As a 3D example, we shown in the image bellow a 3D mesh of the tip of a thumb, where we can see a green point inside the mesh (a kernel point) from which red lines are drawn to every vertex of the mesh.
3D mesh example showing a kernel point.
Point Sampling
Before we explore the 2 approaches (interior and surface), we first go about finding sample points on the mesh from which to grow the regions. These can be both interior and surface points.
Surface points
To sample points on a 3D surface, several strategies exist, each with distinct advantages. The most common approaches are:
Uniform Sampling: This is the most straightforward method, aiming to distribute points evenly across the surface area of the mesh. It typically works by selecting points randomly, with the probability of selection being proportional to the area of the mesh’s faces. While simple and unbiased, this approach is “blind” to the actual geometry, meaning it can easily miss small but important features like sharp corners or fine details.
Curvature Sampling: This is a more intelligent, adaptive approach that focuses on capturing a shape’s most defining characteristics. The core idea is to sample more densely in regions of high geometric complexity. These areas, often called “interest points,” are identified by their high curvature values, such as Gaussian curvature (\(\kappa_G\)) or mean curvature (\(\kappa_H\)). By prioritizing these salient features (corners, edges, and sharp curves), this method produces a highly descriptive set of sample points that is ideal for creating robust shape descriptors for matching and analysis.
Farthest-Point Sampling (FPS): This iterative algorithm is designed to produce a set of sample points that are maximally spread out across the entire surface. The process is as follows:
A single starting point is chosen randomly.
The next point selected is the one on the mesh that has the greatest geodesic distance (the shortest path along the surface) to the first point.
Each subsequent point is chosen to be the one farthest from the set of all previously selected points.
This process is repeated until the desired number of samples is reached.
In this project we implemented the curvature and FPS methods. However, none of these approaches gave us the desired distribution of points. So we came up with a hybrid approach: Farthest-Point Curvature-Informed sampling (FPCIS) . It aims to achieve a balance between two competing goals:
Coverage: The sampled points should be spread out evenly across the entire surface, avoiding large unsampled gaps. This is the goal of the standard Farthest Point Sampling (FPS) algorithm.
Feature-Awareness: The sampled points should be located at or near geometrically significant features, such as sharp edges, corners, or deep indentations. This is where curvature comes into play.
We start by selecting the highest curvature point in the mesh. Then, similar to FPS we compute the geodesic distances from this selected point to all other points using the Dijkstra algorithm over the mesh. However, instead of just taking the farthest point, we first create a pool of the top 30% farthest points, and from this pool we then select the one with highest curvature. The subsequent points are chosen in a similar manner to FPS.
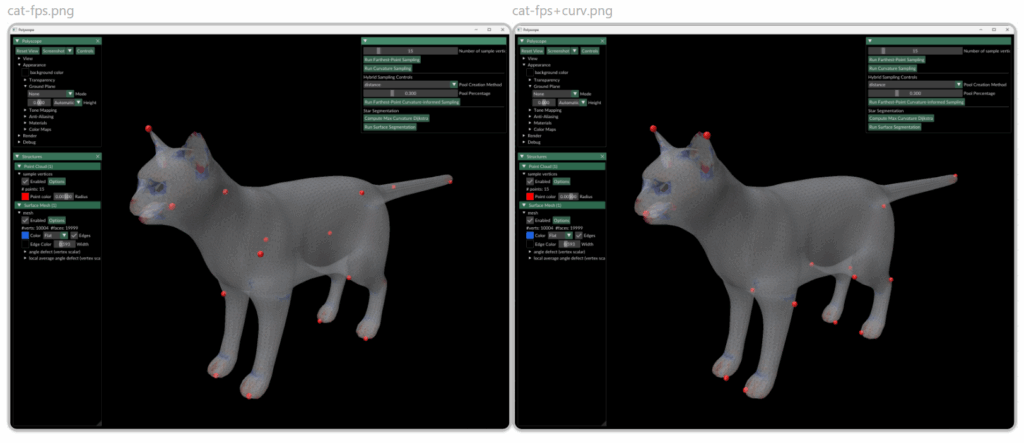
Visualization of surface point sampling methods created using Polyscope.
The image above shows the sampling of 15 points using pure FPS (left) and using the FPCIS (right). we see that although FPS gives a pretty well distributed set of sample points we found that some regions that we deemed important where being left out. For example, when sampling 15 points using FPS on the cat model one of the ears was not being sampled. When using the curvature-informed approach we can see that the important regions are correctly sampled.
Interior points
To achieve a list of points that lie well inside the mesh and have good visibility out to the surface, we cast rays inward from every face and recording where they first hit the opposite side of the mesh. Concretely:
For each triangular face, we compute its centroid.
We flip the standard outward face normal to get an inward direction \(d\).
From each centroid, we cast a ray along \(d\), offset by a tiny \(\epsilon\) so it doesn’t immediately self‐intersect.
We use the Möller–Trumbore algorithm to find the first triangle hit by each ray.
The midpoint between the ray origin and its first intersection point becomes one of our skeletal nodes—a candidate interior sample.
Casting one ray per face can produce thousands of skeletal nodes. We apply two complementary down‐sampling techniques to reduce this to a few dozen well‐distributed guards:
EuclideanFarthest Point Sampling (FPS)
Start from an arbitrary seed node.
Iteratively pick the next node that maximizes the minimum Euclidean distance to all previously selected samples.
This spreads points evenly over the interior “skeleton” of the mesh.
k-Means Clustering
Cluster all the midpoints into k groups via standard k-means in \(\mathbb R^3\).
Use each cluster centroid as a down‐sampled guard point.
This tends to place more guards in densely populated skeleton regions while still covering sparser areas.
Interior Approach
Building upon the interior points sampled earlier, Yu & Li (2011) proposed 2 methods to decompose the mesh into star-shaped pieces: Greedy and Optimal.
1. Greedy Strategy
To achieve this, we solve a fast set-cover heuristic:
Repeatedly pick the guard whose visible-face set covers the most currently uncovered faces, remove those faces, and repeat until every face is covered.
For each guard \(g\), we shoot one ray per face-centroid to decide which faces it can “see.” We store these as sets $$ C_j=\{i: \text{face i is visible from } g_j\}$$
Let \(U = { 0,1,…, |F|−1}\) be the set of all uncovered faces.
Repeat the following steps until \(U\) is empty:
For each guard j, compute the number of new faces it would cover: $$ s_j = | C_j \cap U | $$
Pick the guard j with the largest \(s_j\).
Record one star-patch of size \(s_j\).
Remove those faces: \(U = U \backslash C_j\).
Output: Get a list of guard indices (= number of star-shaped pieces) that covers the entire mesh.
2. Optimal Strategy
To get the fewest possible star-pieces from the pre-determined finite set of candidate guards, we cast the problem exactly as a minimum set-cover integer program:
Decision variables: Introduce binary \(x_j \in \{0,1\}\) for each guard \(g_j\).
Every face i must be covered by at least one selected guard (constraint) and we aim to minimize the total number of guards (thus pieces), hence together we solve:
The overall pipeline of our implementation is as follows:
We build the \(|F| \times L\) visibility matrix in sparse COO format.
We feed it to SciPy’s milp, wrapping the “≥1” rows in a LinearConstraint and all variables as binary in a single Bounds object.
The solver returns the provably optimal set of \(x_j\). The optimization problem can be stated as \(\min \sum_{i=1}^m x_i\) subject to \(x_i=0,1\) and \(\sum_{j\in J(i)} x_j\ge 1, \forall i\in\{1,\dots,n\}\).
Experimental Results
We ran both methods on a human hand mesh with 1515 vertices and 3026 faces. The results are shown below:
Results from Greedy algorithm (left) and Optimal ILP solver (right)
Down-sampling method
Strategy
# of candidate guards
# of star-shaped pieces
Piece connectivity
FPS sampling
Greedy
25
13
No
50
9
Yes
Optimal
25
9
No
50
6
No
K-means clustering
Greedy
25
8
No
50
8
No
Optimal
25
7
No
50
6
No
Some key observations are:
Both interior approaches have no constraints to ensure connectivity among faces of the same guard, hence causing difficulties in closing the mesh of each piece or inaccurate calculation of final connected piece number.
Down-sampling methods: k‐means clustering tends to slightly better distribute guards in high‐density skeleton regions, hence having a smaller gap between greedy and optimal strategy.
Surface Approach: Surface-Guided Growth with Mesh Closure
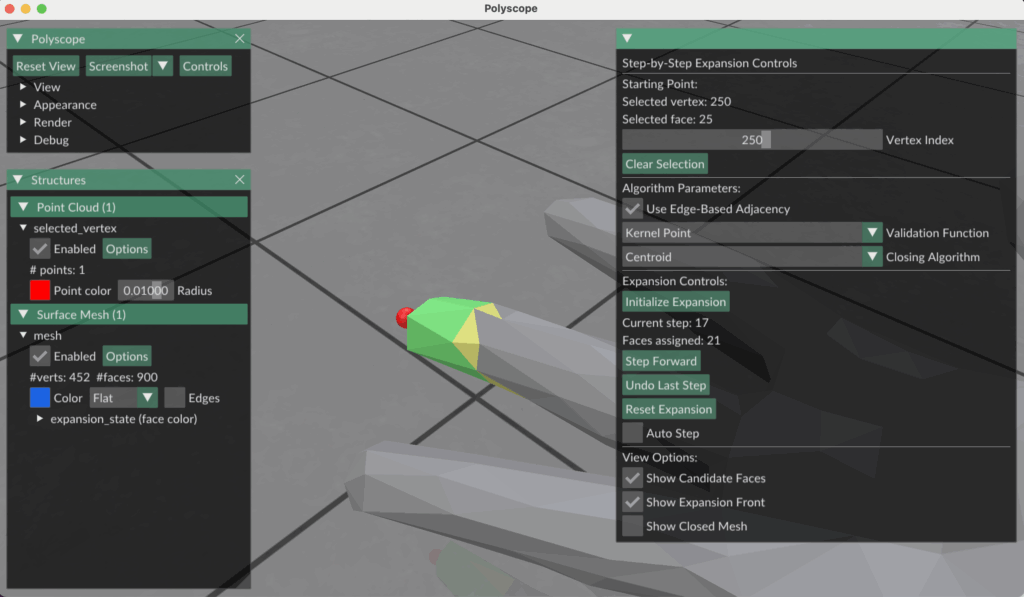
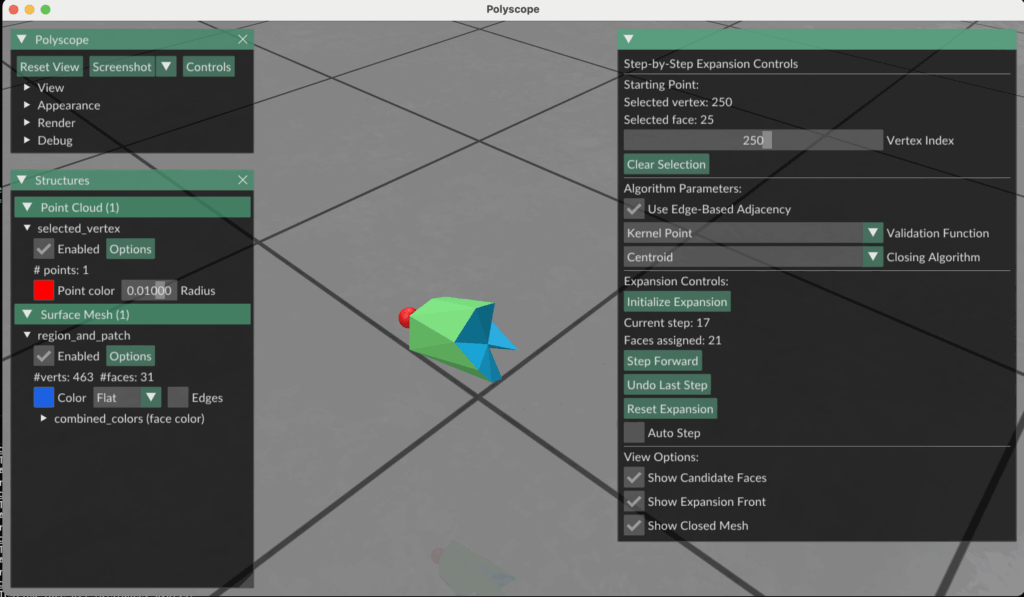
One surface-based strategy we explored is a region-growing method guided by local surface connectivity and kernel validation, with explicit mesh closure at each step. The goal is to grow star-shaped regions from sampled points, ensuring at every expansion that the region remains visible from at least one interior point.
This method operates in parallel for each of the N sampled seed points. Each seed initiates its own region and grows iteratively by considering adjacent faces.
Expansion Process
Initialization:
Begin with the seed vertex and its immediate 1-ring neighborhood—i.e., the three faces incident to the sampled point.
Iterative Expansion:
Identify all candidate faces adjacent to the current region (i.e., faces sharing an edge with the region boundary).
Sort candidates by distance to the original seed point.
For each candidate face:
Temporarily add the face to the region.
Close the region to form a watertight patch using one of the following mesh-closing strategies:
Centroid Fan – Connect boundary vertices to their centroid to create triangles.
2D Projection + Delaunay – Project the boundary to a plane and apply a Delaunay triangulation.
Run a kernel visibility check: determine if there exists a point (the kernel) from which all faces in the current region + patch are visible.
If the check passes, accept the face and continue.
If not, discard the face and try the next closest candidate.
If no valid candidates remain, finalize the region and stop its expansion.
Results and Conclusions
The kernel check was not robust enough—some regions were allowed to grow into areas that clearly violated visibility constraints.
Region boundaries could expand too aggressively, reaching parts of the mesh that shouldn’t logically belong to the same star-shaped segment.
Small errors in patch construction led to instability in the visibility test, particularly for thin or highly curved regions.
As such, the final segmentations were often overextended or incoherent, failing to produce clean, usable star regions. Despite these issues, this approach remains a useful prototype for purely surface-based decomposition, offering a baseline for future improvements in kernel validation and mesh closure strategies.
Expansion with the acquired region at the step.
Expansion step showing mesh and its closing patch.
References
Steffen Hinderink, Hendrik Brückler, and Marcel Campen. (2024). Bijective Volumetric Mapping via Star Decomposition. ACM Trans. Graph. 43, 6, Article 168 (December 2024), 11 pages. https://doi.org/10.1145/3687950
Project Mentors: Sainan Liu, Ilke Demir and Alexey Soupikov
Volunteer Assistant: Vivien van Veldhuizen
Introduction
What is Gaussian Splatting?
3D Gaussian Splatting (3DGS) is a new technique for scene reconstruction and rendering. Introduced in 2023 (Kerbl et al., 2023), it sits in the same family of methods as Neural Radiance Fields (NeRFs) and point clouds, but introduces key innovations that make it both faster and more visually compelling.
To better understand where Gaussian Splatting fits in, let’s take a quick look at how traditional 3D rendering works. For decades, the standard approach to building 3D scenes has relied on mesh modelling — a representation built from vertices, edges, and faces that form geometric surfaces. These meshes are incredibly flexible and are used in everything from video games to 3D printing. However, mesh-based pipelines can be computationally intensive to render and are not ideal for reconstructing scenes directly from real-world imagery, especially when the geometry is complex or partially occluded.
This is where Gaussian Splatting comes in. Instead of relying on rigid mesh geometry, it represents scenes using a cloud of 3D Gaussians — small, volumetric blobs that each carry position, color, opacity, and orientation. These Gaussians are optimized directly from multiple 2D images and then splatted (projected) onto the image plane during rendering. The result is a smooth, continuous representation that can be rendered extremely fast and often looks more natural than mesh reconstructions. It’s particularly well-suited for real-time applications, free-viewpoint rendering, and artistic manipulation, which makes it a perfect match for style transfer, as we’ll see next.
What is Style Transfer?
Figure 1: 2D Style Transfer via Neural Algorithm (Gatys et al., 2015)
Style transfer is a technique in computer vision and graphics that allows us to reimagine a given image (or in our case, a 3D scene) by applying the visual characteristics of another image, known as the style reference. In its most familiar form, style transfer is used to turn photos into “paintings” in the style of artists like Van Gogh or Picasso, as seen in Figure 1. This is typically done by separating the content and style components of an image using deep neural networks, and then recombining them into a new, stylized output.
Traditionally, style transfer has been limited to 2D images, where convolutional neural networks (CNNs) learn to encode texture, color, and brushstroke patterns. But extending this to 3D representations — especially ones that support free-viewpoint rendering — has remained a challenge. How do you preserve spatial consistency, depth, and lighting, while also injecting artistic style?
This is exactly the challenge we’re exploring in our project: applying style transfer to 3D scenes represented with Gaussian Splatting. Unlike meshes or voxels, Gaussians are inherently fuzzy, continuous, and rich in appearance attributes, making them a surprisingly flexible canvas for artistic manipulation. By modifying their colors, densities, or even shapes based on style references, we aim for new forms of stylized 3D content — imagine dreamy impressionist cityscapes or comic-book-like architectural walkthroughs. While achieving consistent and efficient rendering in all cases remains an open challenge, Gaussian Splatting offers a promising foundation for exploring artistic control in 3D.
We present a brief comparison of StyleGaussian and ABC-GS baselines, aiming to extend to style transfer for dynamic patterns, 4D scenes, and localized regions of 3DGS.
Style Gaussian Method
The StyleGaussian pipeline (Liu et al., 2024) achieves stylized rendering of Gaussians with real-time rendering and multi-view consistency through three key steps for style transfer: embedding, transfer, and decoding.
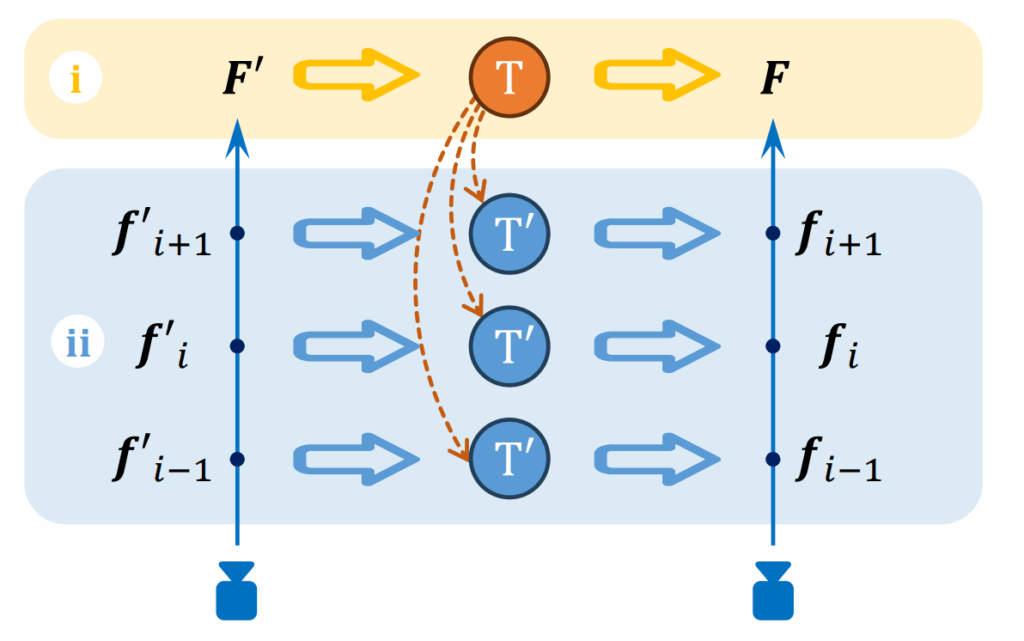
Step 1: Feature Embedding Given a Gaussian Splat and camera positions, the first stage of stylization is embedding deep visual features into the Gaussians. To do this, StyleGaussian uses VGG, a classical CNN architecture trained for image classification. Specifically, features are extracted from the ReLU3_1 layer, which captures mid-level textures like edges and contours that are useful for stylization. These are called VGG features, and they act like high-level visual descriptors of the content of an image. However, VGG features are high-dimensional (256 channels or more), and trying to render them directly through Gaussian Splatting might overwhelm the GPU.
Figure 2: Transformations for Efficient Feature Embedding (Liu et al., 2024)
To solve this, StyleGaussian uses a clever two-step trick illustrated in Figure 2. Instead of rendering all 256 dimensions at once, the program first renders a compressed 32-dimensional feature representation, shown as F’ in the diagram. Then, it applies an affine transformation T to map those low-dimensional features back up to full VGG features F. This transformation can either be done at the level of pixels (i) or at the level of individual Gaussians (ii) — in either case, we recover high-quality feature embeddings for each Gaussian using much less memory.
During training, the system aims to minimize the difference between predicted and true VGG features, so that each Gaussian carries a compact and style-aware feature representation, ready for stylization in the next step.
Step 2: Style Transfer With VGG features embedded, the next step is to apply the style reference. This is done using a fast, training-free method called AdaIN (Adaptive Instance Normalization). AdaIN works by shifting the mean and variance of the feature vectors for each Gaussian so that they match those of the reference image, “repainting” the features without changing their structure. Since this step is training-free, StyleGaussian can apply any new style in real time.
Figure 3: Sample Style Transfer (style references provided by StyleGaussian)
Step 3: RGB Decoding After the style is applied, each Gaussian now carries a modified feature vector — a set of abstract values the neural network uses to describe patterns like brightness, curvature, textures, etc. To render the image, this feature vector needs to be converted into RGB colors for each Gaussian. StyleGaussian does this via a 3D CNN that operates across neighboring Gaussians. This network is trained using a small subset of the style reference images. By comparing a rendered view of the style-transfer to the reference, the network learns how to color the entire scene in a way that reflects the chosen artistic style.
ABC-GS Method
While StyleGaussian offers impressive real-time stylization using feature embeddings and AdaIN, it has a major limitation: it treats the entire scene as a single unit. That means the style is applied uniformly across the whole 3D reconstruction, with no understanding of different objects or regions within the scene.
This is where ABC-GS (Alignment-Based Controllable Style Transfer for 3D Gaussian Splatting) brings something new to the table.
Rather than applying style globally, ABC-GS (Liu et al., 2025) introduces controllability and region-specific styling, enabling three distinct modes of operation:
Single-image style transfer: Apply the visual style of a single image uniformly across the 3D scene, similar to traditional style transfer.
Compositional style transfer: Blend multiple style images, each assigned to a different region of the scene. These regions are defined by manual or automatic masks on the content images (e.g., using SAM or custom annotation). For example, one style image can be applied to the sky, another to buildings, and a third to the ground — each with independent control.
Semantic-aware style transfer: Use a single style image that contains multiple internal styles or textures. You extract distinct regions from this style image (e.g., clouds, grass, brushstrokes) and assign them to matching parts of the scene (e.g., sky, ground) via semantic masks of the content. These masks can be generated automatically (with SAM) or refined manually. This allows for highly detailed region-to-region alignment even within one image.
Figure 4: ABC-GS Single Image Style Transfer
The Two-Stage Stylization Pipeline
ABC-GS achieves stylization using a two-stage pipeline:
Stage 1: Controllable Matching Stage (used in modes 2 and 3 only) In compositional and semantic-aware modes, this stage prepares the scene for region-based style transfer. It includes:
Mask projection: Content and style masks are projected onto the 3D Gaussians.
Style isolation: Each region of the style image is isolated to avoid texture leakage.
Color matching: A linear color transform aligns the base colors of each content region with its assigned style region.
This stage is not used in the single-image mode, since the entire scene is styled uniformly without regional separation.
Stage 2: Stylization Stage (used in all modes) In all three modes, the scene undergoes optimization using the FAST loss (Feature Alignment Style Transfer). This loss improves upon older methods like NNFM by aligning entire distributions of features between the style image and the rendered scene. It captures global patterns such as brushstroke directions, color palette balance, and texture consistency – even in single-image style transfer, FAST consistently yields more coherent and faithful results.
To preserve geometry and content, the stylization is further regularized with:
Content loss: Retains original image features.
Depth loss: Maintains 3D structure.
Regularization terms: Prevent artifacts like over-smoothed or needle-like Gaussians.
Together, these stages make ABC-GS uniquely capable of delivering stylized 3D scenes that are both artistically expressive and structurally accurate — with fine-grained control over what gets stylized and how.
Visual & Quantitative Comparison
Figure 5 illustrates style transfer applied to a truck composed of approximately 300k Gaussians by StyleGaussian (left) and ABC-GS (right). In choosing simple patterns like a checkerboard or curved lines, we hope to highlight how each method handles the key challenges of 3D style transfer, such as alignment with underlying geometry, multi-view consistency, and accurate pattern representation.
To evaluate these differences from a quantitative angle, Fréchet Inception Distance (FID) and Learned Perceptual Image Patch Similarity (LPIPS) metrics were used.
FID measures the distance between the feature distributions of two images sets, with lower scores indicating greater similarity. This metric is often used in generative adversarial network (GAN) and neural style transfer research to assess how well generated images match a target domain. Meanwhile, LPIPS measures perceptual similarity between image pairs by comparing deep features from a pre-trained network, with lower scores indicating better content preservation.
For our purposes, FID measures style fidelity (how well stylized images match the style reference), with scores generally between 0 and 200, and lower scores indicating strong style similarity. LPIPS measures geometry and content preservation (how well the original scene structure is retained) within a range [0, 1], with lower scores indicating better structural preservation.
Figure 5: Comparison between StyleGaussian and ABC-GS
There is a clear visual improvement in the geometric alignment of patterns in the ABC-GS style transfer, where patterns adhere more cleanly with the object boundaries. In contrast, StyleGaussian shows a more diffuse application, with some color-bleeding and areas with high pattern variance (e.g., the wooden panels on the truck). In terms of LPIPS and FID scores, ABC-GS generally outperforms StyleGaussian, but tends to apply a less stylistically-accurate transfer with regular patterns (i) compared to more “abstract” ones (iii).
This difference in performance may stem from how StyleGaussian and ABC-GS handle feature alignment and geometry preservation. StyleGaussian applies a zero-shot AdaIN shift to all Gaussians, matching only the mean and variance of features; since higher-order structure is ignored, patterns can drift onto the wrong parts of the geometry. In contrast, ABC-GS optimizes the scene via FAST loss, computing a transformation that aligns the entire feature distribution of the rendered scene to that of the style. Meanwhile, content loss keeps the scene recognizable, depth loss maintains 3D geometry, and Gaussian regularization prevents distortions, resulting in better LPIPS and FID scores overall. However, in a case like (ii) where there is a lot of white background, ABC-GS’s competing content, depth, and regularization losses prevent large areas to be overwritten with pure white. Instead, it will try to keep more of the original scene’s detail and contrast, especially around geometry edges, which causes a deviation from the style reference and higher FID score. This interplay between geometry and style preservation is a key tradeoff in style transfer.
Although FID and LPIPS metrics are well-established in 2D image synthesis and style transfer, it is important to recognize potential limitations of applying them directly to 3D style transfer. These metrics operate on individual rendered views, without considering multi-view consistency, depth alignment, or temporal coherence. Future works should aim to better understand these benchmarks for 3D scenes.
Extensions & Experiments
Localized Style Transfer: Unsupervised Structural Decomposition of a LEGO Bulldozer via Gaussian Splat Clustering
We explore a novel technique for structural decomposition of complex 3D objects using the latent feature space of Gaussian Splatting. Rather than relying on pre-defined semantic labels or handcrafted segmentation heuristics, we directly use the parameters of a trained Gaussian Splat model as a feature embedding for clustering.
Motivation
The aim was twofold:
Discovery – to see whether clustering Gaussians reveals structural groupings that are not immediately obvious from the visual appearance.
Applicability – to explore whether these groupings could be useful for style transfer workflows, where distinct regions of a 3D object might be stylized differently based on structural identity.
Method
We trained a Gaussian Splatting model on a multi-view dataset of a LEGO bulldozer. The model was optimized to reconstruct the object from multiple angles, producing a 3D representation composed of thousands of oriented Gaussians.
From this representation, we extracted the following features per Gaussian:
3D Position(x, y, z) (weighted for stronger spatial influence)
Color(r, g, b)
Scale(scale_0, scale_1, scale_2) (downweighted to avoid overemphasis)
Opacity(if available)
Normal Vector(nx, ny, nz)(surface orientation)
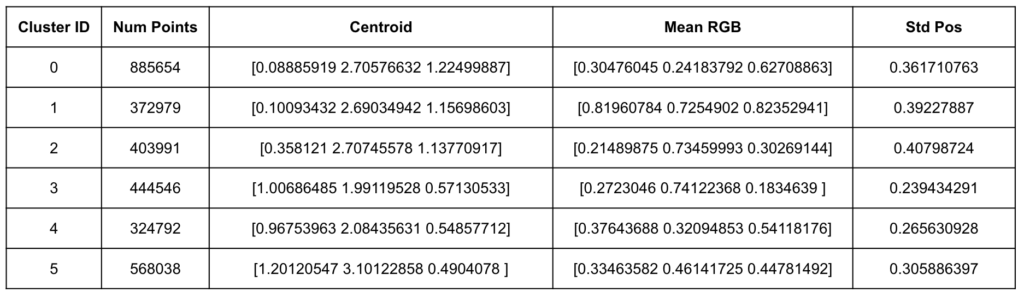
These features were concatenated into a single vector per Gaussian, weighted appropriately, and standardized. We applied KMeans clustering to segment the Gaussian set into six groups.
Results
The clustering revealed six distinct regions within the bulldozer’s Gaussian representation, each with unique spatial, chromatic, and geometric signatures.
Figure 6: Statistics for 6 Clusters
Figure 7: Visualization of KMeans groupings
Conclusion
The clustering was able to segment the bulldozer into regions that loosely align with intuitive sub-parts (e.g., the bucket, cabin, and rear assembly), but also revealed less obvious groupings—particularly in areas with subtle differences in surface orientation and scale that are hard to distinguish visually. This suggests that Gaussian-parameter-based clustering could serve as a powerful tool for automated part segmentation without requiring labeled data.
Future Work
Cluster Refinement – Experiment with different weighting schemes and feature subsets (e.g., excluding normals or opacity) to evaluate their effect on segmentation granularity.
Hierarchical Clustering – Apply multi-level clustering to capture both coarse and fine structural groupings.
Style Transfer Applications – Use cluster assignments to drive localized style transformations, such as recoloring or geometric exaggeration, to test their value in content creation workflows.
Cross-Object Comparison – Compare clustering patterns across different models to see if similar structural motifs emerge.
Dynamic Texture Style Transfer
Next, given StyleGaussian’s ability to apply new style references at runtime, a natural extension is style transfer of dynamic patterns. Below are some initial results of this approach, created by cycling through the frames of a gif or video in predetermined time intervals.
There is a key tradeoff between flexibility and quality: while zero-shot transfer enables dynamic patterns, the features are relatively muddled, making it difficult to project detailed media. Meanwhile, in the case of ABC-GS, this improved stylization is a result of optimization, which cannot occur at runtime as with StyleGaussian, making it difficult to render dynamic patterns.
Dynamic Scene Style Transfer
So far we’ve shown how incredibly powerful 3D Gaussian Splatting (3DGS) is for generating 3D static scene representations with remarkable detail and efficiency. The parallel to the dawn of photography is a compelling one: just as early cameras first captured the world on a static 2D canvas, 3DGS excels at creating photorealistic representations of real world scenes on a static 3D canvas. A logical next step is to leverage this technology to capture dynamic scenes.
Videos represent dynamic 2D scenes by capturing a series of static images that, when shown in rapid succession, let us perceive subtle changes as motion. In a similar fashion, one may attempt to capture dynamic 3D scenes as a sequence of static 3D scene representations. However, the curse of dimensionality plagues any naive approach to bring this idea to reality.
Lessons from Video Compression
In the digital age of motion picture, storing a video naively as a sequence of individual images (imitating a physical film strip) is possible but hugely inefficient. A digital image is nothing more than a 2D grid of small elements called pixels. In most image formats, each pixel usually stores about 3 bytes of color data, and a good quality Full HD image contains around 1920 x 1080 ≈ 2 million pixels. This amounts to around 6 million bytes (6 MB) of memory needed to store a single uncompressed Full HD image. Now, a reasonably good video should capture 1 second of a dynamic scene using 24 individual images (24 fps), which yields 144 MB of data to capture just a single second of uncompressed video (using uncompressed images). This means that a quick 30-second video would require a whopping 5 GB of memory.
So although possible, this naive approach to capturing dynamic 2D scenes quickly becomes impractical. To address this problem, researchers and engineers developed compression algorithms for both images and videos in an attempt to reduce memory requirements. The JPEG image format, for example, achieves an average of 10:1 compression ratio, shrinking a Full HD image to only 0.6 MB (600 KB) of storage. However, even if we store a 30-second video as a sequence of compressed JPEG frames, we would still be looking at a 500 MB video file.
The JPEG format compresses images by removing unnecessary and redundant information on the spatial domain, identifying patterns in different parts of the image. Following this same principle, video formats like MP4 identify patterns in the time domain and use them to construct a motion vector field to shift parts of the image from one frame to another. By storing only what changes, these video formats often achieve around 100:1 compression — depending on the contents of the scene — which takes our original 30-second 5 GB video to only 50 MB.
We will now see how this problem of scalability gets even worse when dealing with 3D Gaussian Splatting scenes.
The Curse of Dimensionality
Previously, we have discussed that while 2D grids are made up of pixels storing 3 bytes of color information, 3DGS Gaussians store position, orientation, scale, opacity, and color data. Thus, it is important to note that an image represents a scene from a single viewpoint, so its lighting information is static and can be easily stored using simple RGB colors. In contrast, since GS must represent a 3D scene from various viewpoints, we must have a way to store this dynamic lighting and change Gaussians’ colors depending on where the scene is viewed from. To achieve this, a technique called Spherical Harmonics is used to encode both color and lighting information for each Gaussian.
To store this information we need:
3 floats for position,
3 floats for scale,
4 floats for orientation (using quaternions),
1 float for opacity,
16 floats for color/lighting (using spherical harmonics*).
Using single-precision floats, that is 236 bytes per Gaussian. In a crude comparison, we can see that the building blocks of a 3DGS scene representation must store 78x more data than a pixel in a 2D image. While the next section shows that good 3DGS scenes require much fewer Gaussians than a good image requires pixels, moving to the 3rd dimension already poses a significant memory challenge.
For example, Figure 8 contains around 200.000 Gaussians, which amounts to about 23 MB of data for a single static scene.
Figure 8: Lego Bulldozer with 200k Gaussians, generated with PostShot
If we were to follow the same naive idea for 2D videos and store a full static scene for each frame of a dynamic scene, we would need 24 static 3DGSs to represent 1 second of the dynamic scene (at 24 FPS), which would require 550 MB. A 30-second clip would then require a whopping 15 GB of storage. For more complex or detailed scenes, this problem only gets worse. And that’s just storage; generating and rendering all of this information would require a lot of computation and memory bandwidth, especially if we aim for real-time performance.
One notable approach to this problem was presented by Luiten et al. (2023), where the authors take a canonical set of Gaussians and keep intrinsic properties like color, size and opacity constant in time, storing only the position and orientation of Gaussians at each timestep. While less data is needed for each frame, this approach still scales linearly with frame count.
A Solution: Learn How the Scene Changes
So, instead of representing dynamic scenes as sequences of static 3DGS frames, a compelling research direction is to employ a strategy similar to video compression algorithms: focus on encoding how the scene changes between frames.
This is the idea behind 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering (Wu et al., 2024). Their solution comes in the form of a Gaussian Deformation Field Network, a compact neural network that implicitly learns the function that dictates motion for the entire scene. This improves scalability, as the memory footprint depends mainly on the network’s size rather than video length.
Instead of redundantly storing scene information, 4DGS establishes a single canonical set of 3D Gaussians, denoted by \( \mathscr{G} \), that serves as the master model for the scene’s geometry. From there, the Gaussian Deformation Field Network \( \mathscr{F}\) learns the temporal evolution of Gaussians. For each timestamp \(t\), the network predicts the deformation \(\Delta \mathscr{G}\) for the entire set of canonical Gaussians. The final state of the scene for that frame, \(\mathscr{G}’\), is then computed by applying the learned transformation:
The network’s encoder is designed with separate heads to predict the components of this transformation: a change in position (\(\Delta \mathscr {X}\)), orientation (\(\Delta r\)), and scale (\(\Delta s\)).
By encoding a scene as fixed geometry (the canonical Gaussian set) plus a learned function of its dynamics, 4DGS offers an efficient and compact model of the dynamic 3D world. Additionally, because the model is a true 4D representation, it enables rendering the dynamic scene from any novel viewpoint in real-time, thereby transforming a simple recording into a fully immersive and interactive experience.
The output is a canonical Gaussian Splatting scene stored as a .ply file together with a set of .pth files (the standard PyTorch model files) that encode the Gaussian Deformation Field Network. From there, the scene may be rendered from any viewpoint at any timestamp of the video.
To demonstrate, we use a scene from the HyperNerf dataset. Figure 9 compares the original video (left), the resulting trained-view 4DGS (center), and the resulting test-view 4DGS (right). The right video is rendered from a different viewpoint and is used to verify that the GS indeed generalized the scene geometry in 3D space.
Figure 9: Broom views from 4DGS
The 4DGS pipeline
Before explaining the 4DGS pipeline, we must first understand its input. We aim to generate a 4D scene — that is a 3D scene that changes over time (+1D). This requires a set of videos that capture the same scene simultaneously. In synthetic datasets, researchers use multiple cameras (e.g., 27 cameras in the Panoptic dataset) to film from multiple viewpoints at the same time. However, in real world setups, this is impractical, and usually a stereo setup (i.e. 2 cameras) is more common, as in the HyperNerf dataset.
With the input defined, the pipeline can be split into 3 main steps:
Initialization: Before anything can move, the model needs a 3D “puppet” to animate. The quality of this initial puppet depends heavily on the camera setup used to film the video.
Case A: The ideal multi-camera setup
Scenario: This applies to lab-grade datasets like the Panoptic Studio dataset, which uses a dome of many cameras (e.g., 27) all recording simultaneously.
Process: The model looks at the images from all cameras at the very first moment in time (t=0). Because it has so many different viewpoints of the scene frozen in that instant, it can use Structure-from-Motion (SfM) to create a highly accurate and dense 3D point cloud.
Result: This point cloud is turned into a high-fidelity canonical set of Gaussians that perfectly represents the scene at the start of the video. It’s a clean, sharp, and well-defined starting point.
Case B: The Challenging real-world scenario
Scenario: This applies to more common videos filmed with only one or two cameras, like those in the HyperNeRF dataset.
Process: With too few viewpoints at any single moment, SfM needs the camera to move over time to build a 3D model. Therefore, the algorithm must analyze a collection of frames (e.g., 200 random frames) from the video.
Result: The static background is reconstructed well, but the moving objects are represented by a more scattered, averaged point cloud. This initial canonical scene doesn’t perfectly match any single frame but instead captures the general space the object moved through. This makes the network’s job much harder.
Static Warm-up: With the initial puppet created, the model spends a “warm-up” period (the first 3,000 iterations in the paper’s experiments) optimizing it as if it were a static, unmoving scene. This step is crucial in both cases. For the multi-camera setup, it fine-tunes an already great model. For the single-camera setup, it’s even more important, as it helps the network pull the averaged points into a more coherent shape before it tries to learn any complex motion.
Dynamic Training: Now for the main step, the model goes through the video frame by frame and trains the Gaussian Deformation Field Network.
Pick a Frame: The training process selects a specific frame (a timestamp, t) from the video.
Ask the Network: It feeds the canonical set of Gaussians \(\mathscr G\) and the timestamp \(t\) into the deformation network \(\mathscr F\).
Predict the motion: The network predicts the necessary transformations \(\Delta \mathscr G\) for every single Gaussian to move them from their canonical starting position to where they should be at a timestamp t. This includes changes in position, orientation and scale.
Apply the motion: The predicted transformations are applied to the canonical Gaussians to create a new set of deformed Gaussians \(\mathscr G’\) for that specific frame.
Render the image: The model then renders the ‘splats’ the deformed Gaussians onto an image, creating a synthetic view of what the scene should look like.
Compare with original and calculate error: The rendered image is then compared with the actual video frame from the dataset. The difference between the two is used as the loss, which is calculated as simply the L1 color loss. It basically says how different each pixel of the splatted image is from the original video frame.
Backpropagation: This is the learning step, where the error is sent backward through the network so it can adjust the position, orientation, and scale of the Gaussians to better approximate the scene.
This loop repeats for different frames and different camera views until the network becomes so good at predicting the deformations that it can generate a photorealistic moving sequence from the single canonical set of Gaussians.
4D Stylization
Now that we understand how 4D Gaussian Splatting works, we present here an idea for integrating the StyleGaussian method into the 4DGS pipeline. Unfortunately we were not able to fully implement this idea due to time limitations, however we will explain how and why this idea should work.
The fact that the 4DGS pipeline works by generating a canonical static representation of the scene makes it suitable for integrating with StyleGaussian. We may simply run it on the canonical scene representation that was generated, and the deformation would then move the stylized gaussians to the right places.
One potential problem with this approach, however, is that the canonical scene generated with real-world scenes captured using a stereo camera setup may not correctly represent moving objects on the scene. Due to the lack of images for the initial frame (only 2) when using these datasets, the 4DGS method utilizes random frames from the whole video to obtain the canonical set of Gaussians, which ends up being an average of the scene. Thus, moving objects will not be correctly captured and if we apply a stylization on this averaged scene, it could potentially lead to a less stable or visually inconsistent application of the style on dynamic elements within the final rendered video.
Overall Conclusions & Future Directions
Given the time and resource constraints of our project, we have shown a visual and quantitative comparison of the preservation of pattern features during style transfer with Style Gaussian and ABC-GS. Additionally, using these baselines, we have experimented with some initial results for style transfer with dynamic patterns, proposed a method for combining StyleGaussian with 4DGS, and developed an effective GS clustering strategy that can be used for localized style applications.
Future research might expand on these experiments by:
Exploring better validation metrics for GS scenes that account for 3D components like multi-view consistency
Developing alternatives to random frames for generating canonical set of Gaussians from stereo camera scenes, which will prevent visually inconsistent stylization
Further refining clustering techniques and developing metrics to evaluate the effectiveness of local stylization
Applications of dynamic textures onto individual local GS components via clustering, building on the global transition effect explored previously. This direction could produce interesting “special effects” such as displaying optical illusions or giving a “fire effect” to a 3DGS scene
References
Gatys, L. A., Ecker, A. S., & Bethge, M. (2015, August 26). A neural algorithm of artistic style. arXiv.org. https://arxiv.org/abs/1508.06576
Kerbl, B., Kopanas, G., Leimkuehler, T., & Drettakis, G. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Transactions on Graphics, 42(4), 1–14. https://doi.org/10.1145/3592433
Liu, K., Zhan, F., Xu, M., Theobalt, C., Shao, L., & Lu, S. (2024, March 12). StyleGaussian: Instant 3D Style Transfer with Gaussian Splatting. arXiv.org. https://arxiv.org/abs/2403.07807
Liu, W., Liu, Z., Yang, X., Sha, M., & Li, Y. (2025, March 28). ABC-GS: Alignment-Based Controllable Style Transfer for 3D Gaussian splatting. arXiv.org. https://arxiv.org/abs/2503.22218
Luiten, J., Kopanas, G., Leibe, B., & Ramanan, D. (2023, August 18). Dynamic 3D Gaussians: Tracking by persistent dynamic view synthesis. arXiv.org. https://arxiv.org/abs/2308.09713
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., & Wang, X. (2023, October 12). 4D Gaussian Splatting for Real-Time Dynamic Scene rendering. arXiv.org. https://arxiv.org/abs/2310.08528
Thanks to Ioannis Mirtsopoulos, Elshadai Tegegn, Diana Avila, Jorge Rico Esteban, and Tinsae Tadesse for invaluable assistance with this article.
This article is a continuation of A Derivation of the Force Density Method, and will be continued by another article outlining results and next steps. Recall that we have constructed a function \[F:\mathscr Q \to \mathscr C,\] where \(\mathscr Q\) is the space of all possible force-length ratios and \(\mathscr C\) the space of all possible lists of coordinate pairs, such that the image of this function is the set of points in static equilibrium. Recall also that this function is a rational function (a ratio of two polynomial functions) with denominator given by a determinant. The goal of this article is to compute a simple description of the image of this function; in particular, we would like to compute polynomial equations which define the image.
Elimination Ideals and Groebner Bases
The technique we’ll use to compute the polynomial equations which define the image of this function is called an elimination ideal. Recall that the graph of a (polynomial) function \(f:\mathbb R^n\to \mathbb R^m\) is the set \(\{(x, f(x))\subset \mathbb R^n\times \mathbb R^m\}\). Note that there is an inclusion function \(\iota:x\mapsto (x, f(x))\) from \(\mathbb R^n\) to the graph of \(f\), and a projection function \(\pi\) from the graph of \(f\) to \(\mathbb R^m\) given by \((x, y)\mapsto y\), such that \(\pi\circ\iota = f\). Elimination theory first computes the polynomial equations for the graph of \(f\), and then computes the image of this graph under the projection function, thus computing the polynomial equations defining the image of \(f\).
In fact, this explanation has missed an important nuance: not every set can be defined by polynomial equations. If, however, the set cannot be defined by polynomial equations, this method will compute the smallest set which can be defined by polynomial equations and contains the image of \(f\).
The theory of Groebner bases and elimination ideals is rich and far exceeds the scope of this article; Eisenbud’s Commutative Algebra with a View Towards Algebraic Geometry is an excellent resource, in particular Chapter 15 on Groebner Bases, Section 15.10.4 being the relevant resource for this discussion. I will endeavor to sketch the techniques we use for this computation in layman’s terms, but it will be difficult to obtain a technical understanding of this theory without background in commutative algebra.
Localization
Recall first that the function \(F\) is a rational function, that is, it has a polynomial denominator and is thus only defined away from where that denominator attains the value zero. We need a way to ‘fix’ this, and the appropriate tool from commutative algebra is called localization. At a high level, localization is the process of formally inverting a polynomial, and considering the set of polynomials with that formally inverted polynomial. This not only allows us to work with this rational function, but also speeds up our computations down the line. There is a corresponding formal process which ensures that we only keep track of the solutions for this entire system which lie away from the set where that inverted polynomial is zero. For more information about this, look into the theory of affine schemes; the idea is that all of the information about the geometry we want to study is contained in the set of polynomials (called a ‘ring’) which are defined on that geometry. By inverting one of these polynomials, we remove the set where that polynomial is zero from the geometry of our space.
The Graph of \(F\) and projection
Computing the graph of the map \(F\) is not difficult; we simply take the set defined by polynomials of the form \(x_i – F_j\), where \(F_j\) is the polynomial defining the \(j\)th component of \(F\). Computing the image of the projection is more difficult; we must find a way of eliminating the first variables \(x_i\). To do this, we fix an ordering on the monomials of our polynomials, and use that ordering to perform a type of polynomial division – similar to the standard kind in one variable, but a little more complicated. For more information, see (for example) Chapter 15 of Eisenbud or Chapter 9.6 in Dummit and Foote’s Abstract Algebra. This leaves us with a set of polynomials, some of which will be in only the variables we want. It is a theorem (Proposition 15.29 in Eisenbud) that, so long as we pick our ordering correctly (it must be the case that whenever the first-ordered term in a polynomial contains only the variables we want to project onto, the entire polynomial contains only the variables we want to project onto), picking only the polynomials in the variables we want will give us polynomials who’s zero set contains every zero set of polynomials containing the image of this function.
Additional Thoughts
It’s important to realize that the result of this computation is not actually the image of the FDM map. This is a good thing, because the image of the FDM map cannot contain any values where nodes lying on the same line overlap, because this would result in a division by zero when computing force-length ratios. However, these are perfectly physical configurations, represented by a smaller network, and we want to be able to model them easily. The way to formally fix this is to introduce, instead of a single real variable for each force-length ratio, a point along the projective line. This allows the length to take the value zero, representing a force-length ratio of ‘infinity’, and yields a parameter space which consists of a copy of the projective line for every edge in the graph. This variety would be what is called a projective variety, for technical reasons; this would also imply that the variety was proper, in particular universally closed, another technical condition which implies that the projection map would take the zero sets of polynomials to the zero sets of polynomials (in the terms of algebraic geometry, the base-change of the map from the force-density space to the ground field along the map from the node-position space to the ground field would then be closed). It would be a little more complicated to apply our elimination theory method to this setup, but it would yield the assurance that the image of our map is exactly the set defined by the polynomials we obtain.
In a later blog post I will share the implementation of this algorithm in sage, and the results I obtained.
How can we extend the 2-close interaction to a general n-close interaction?
That was the question at the end of the triangle’s hex blog post. This post goes through the thought process and tools used to solve for the sequence that extends the 2-close interaction to a general \(n\)-close interaction.
The approach here focused on analyzing the rotation of the dual structure and determining the precise amount of rotation required to arrive at the desired \(n\)-case configuration. This result was obtained by solving a relatively simple Euclidean geometry subproblem, which sometimes is encountered as a canonical geometry problem at the secondary or high-school level. Through this perspective, a closed-form startingstep for the general sequence was successfully derived.
OPEN FOR SPOILER FOR ANSWER
The rotation angle, \(\theta\), required to obtain a part of the the \(n\)-close interaction term in the dual is given by:
As with many mathematical problems, there are multiple approaches to reach the same result. I really encourage you to explore doing it yourself but without further ado, here is the presentation of the thought process that led to this solution.
By the way, the working name for this article was Hex and the City: Finding Your N-Closest Neighbors , if you read all this way, I think you at least deserve to know this.
Constructing the Solution
We start off where we left off in the Auxiliary Insights section of the last blog post.
Recall that a rotation by \(60^\circ\) returns us to the original dual line due to the underlying sixfold symmetry. For the \(2\)-close interaction, we introduced a new dual by halving this angle to $30^\circ$. Naturally, to explore the \(3\)-close case, one might attempt the naive approach of halving again to $15^\circ$. However, as seen below, this approah does not yield the desired result, indicating that the simple halving approach cannot be extended straightforwardly.
By manually guessing and checking the rotation values, we end up with a somewhat unexpected sequence, something that, for me at least, is nothing immediately obvious.
This hints at the need to uncover a more subtle structure that lets us analytically determine the values we seek.
Some prerequisite background is provided in the next section, but if you’re already familiar, feel free to skip ahead to the solution process that builds on these ideas.
Some useful underlying mathematics prerequisites that could help
Modular Arithmetic
A Quick Introduction to Modular Arithmetic
Modular arithmetic is a system of arithmetic for integers where numbers “wrap around” after reaching a certain value called the modulus. Rather than focusing on the full quotient of a division, modular arithmetic concerns itself with the remainder. It is a foundational concept in number theory and has wide applications in cryptography, computer science, and abstract algebra.
Motivation
Suppose you are working with a standard 12-hour clock. If the current time is 9 and 5 hours pass, the clock shows 2, not 14. This is because clocks operate “modulo 12”, meaning we consider two numbers equivalent if they differ by a multiple of 12. So:
$$ 9 + 5 = 14 \equiv 2 \pmod{12} $$
This is a basic example of modular arithmetic: rather than computing the full sum, we reduce it to its residue modulo 12.
Definition
Let \(n \) be a fixed positive integer, called the modulus. For any integers \(a \) and \(b \), we say:
$$ a \equiv b \pmod{n} $$
(read as “a is congruent to b modulo n”) if and only if \(n \) divides \(a – b \); that is, there exists an integer \(k \) such that:
$$ a – b = kn $$
This defines an equivalence relation on the set of integers \(\mathbb{Z} \), which partitions \(\mathbb{Z} \) into \(n \) distinct congruence classes modulo \(n \). Each class contains all integers with the same remainder upon division by \(n \).
For example, with \(n = 5 \), the integers are grouped into the following classes:
$$ [0] = { \dots, -10, -5, 0, 5, 10, \dots } $$
$$ [1] = { \dots, -9, -4, 1, 6, 11, \dots } $$
$$ [2] = { \dots, -8, -3, 2, 7, 12, \dots } $$
$$ [3] = { \dots, -7, -2, 3, 8, 13, \dots } $$
$$ [4] = { \dots, -6, -1, 4, 9, 14, \dots } $$
Each integer belongs to exactly one of these classes. For computational purposes, we usually represent each class by its smallest non-negative element, i.e., by the residue \(r \in {0, 1, \dots, n-1} \).
Arithmetic in \(\mathbb{Z}/n\mathbb{Z} \)
The set of congruence classes modulo \(n \), denoted \(\mathbb{Z}/n\mathbb{Z} \), forms a ring under addition and multiplication defined by:
\([a] + [b] := [a + b] \)
\([a] \cdot [b] := [ab] \)
These operations are well-defined: if \(a \equiv a’ \pmod{n} \) and \(b \equiv b’ \pmod{n} \), then \(a + b \equiv a’ + b’ \pmod{n} \) and \(ab \equiv a’b’ \pmod{n} \).
If \(n \) is prime, \(\mathbb{Z}/n\mathbb{Z} \) is a finite field, meaning every nonzero element has a multiplicative inverse.
Formal Summary
Modular arithmetic generalizes the idea of remainders after division. Formally, for a fixed modulus \(n \in \mathbb{Z}_{>0} \), we say:
$$ a \equiv b \pmod{n} \iff n \mid (a – b) $$
This defines a congruence relation on \(\mathbb{Z} \), leading to a system where calculations “wrap around” modulo \(n \). It is a central structure in elementary number theory, forming the foundation for deeper topics such as finite fields, Diophantine equations, and cryptographic algorithms.
Law Of Sines
Derivation of the Law of Sines
The Law of Sines is a fundamental result in trigonometry that relates the sides of a triangle to the sines of their opposite angles. This elegant identity allows us to find unknown angles or sides in oblique triangles using simple trigonometric ratios.
Setup and Construction
Consider an arbitrary triangle \(\triangle ABC \) with:
\(a = BC \)
\(b = AC \)
\(c = AB \)
To derive the Law of Sines, we draw an altitude from vertex \(A \) perpendicular to side \(BC \), and denote this height as \(h \).
Now consider the two right triangles formed by this altitude:
In \(\triangle ABC \), using angle \(B \): $$ \sin B = \frac{h}{a} \quad \Rightarrow \quad h = a \sin B $$
Using angle \(C \): $$ \sin C = \frac{h}{b} \quad \Rightarrow \quad h = b \sin C $$
Since both expressions equal \(h \), we equate them:
$$ a \sin B = b \sin C $$
Rewriting this gives:
$$ \frac{a}{\sin C} = \frac{b}{\sin B} $$
We can repeat this construction by drawing altitudes from the other vertices to derive similar relationships:
The Law of Sines implies that in any triangle, the ratio of a side to the sine of its opposite angle is constant. In fact, this constant equals \(2R \), where \(R \) is the radius of the circumcircle of the triangle:
This shows a deep geometric connection between triangles, circles, reflecting the underlyingsymmetry of some parts of Euclidean geometry.
Law Of Cosines (generalisation of Pythagorean theorem)
Derivation of the Cosine Angle Formula
The cosine angle formula, also known as the Law of Cosines, relates the lengths of the sides of a triangle to the cosine of one of its angles.
Motivation
Consider a triangle with sides of lengths \(a \), \(b \), and \(c \), and let \(\theta \) be the angle opposite side \(c \). When \(\theta \) is a right angle, the Pythagorean theorem applies:
$$ c^2 = a^2 + b^2 $$
For any angle \(\theta \), the Law of Cosines generalizes this relationship:
$$ c^2 = a^2 + b^2 – 2ab \cos \theta $$
This formula allows us to find a missing side or angle in any triangle, not just right triangles.
Setup and Coordinate Placement
To derive the formula, place the triangle in the coordinate plane:
Place vertex \(A \) at the origin \((0, 0) \).
Place vertex \(B \) on the positive x-axis at \((b, 0) \).
Place vertex \(C \) at \((x, y) \), such that the angle at \(A \) is \(\theta \).
By definition, the length \(a \) is the distance from \(B \) to \(C \), and \(c \) is the length from \(A \) to \(C \).
Since \(\theta \) is the angle at \(A \), the coordinates of \(C \) can be expressed using polar coordinates relative to \(A \):
$$ C = (a \cos \theta, a \sin \theta) $$
Distance Calculation
The length \(c \) is the distance between points \(A(0,0) \) and \(C(a \cos \theta, a \sin \theta) \):
$$ c = \sqrt{(a \cos \theta – 0)^2 + (a \sin \theta – 0)^2} = a $$
Actually, to keep consistent with the notation, let’s redefine:
\(AB = c \)
\(AC = b \)
\(BC = a \)
So placing:
\(A = (0, 0) \)
\(B = (c, 0) \)
\(C = (x, y) \)
with angle \(\theta = \angle A \) at point \(A \).
Point \(C \) has coordinates:
$$ C = (b \cos \theta, b \sin \theta) $$
The length \(a = BC = \) distance between \(B(c, 0) \) and \(C(b \cos \theta, b \sin \theta) \):
This is the Law of Cosines, it states that for any triangle with sides \(a, b, c \) and angle \(\theta \) opposite side \(a \):
$$ a^2 = b^2 + c^2 – 2bc \cos \theta $$
This formula generalizes the Pythagorean theorem and allows computation of unknown sides or angles in any triangle, making it fundamental in trigonometry and geometry.
Height of a Regular Hexagon of Side Length, \(a\)
Find the height of a regular hexagon with side length \(a\)
Understand the structure of a regular hexagon
A regular hexagon can be divided into 6 equilateral triangles.
Each triangle has side length \(a\).
The height of the hexagon is the distance between two parallel sides, i.e., it’s twice the height of one equilateral triangle formed inside.
So:
$$ \text{height of hexagon} = 2 \times \text{height of equilateral triangle with side } a $$
Use formula for height of an equilateral triangle
The height \(h\) of an equilateral triangle with side length \(a\) is:
$$ h = a \cdot \sin(60^\circ) $$
We use this since the height splits the triangle into two right triangles with angles \(30^\circ, 60^\circ, 90^\circ\).
Substitute:
$$ \sin(60^\circ) = \frac{\sqrt{3}}{2} $$
So:
$$ h = a \cdot \frac{\sqrt{3}}{2} $$
Multiply by 2 to get full hexagon height
$$ \text{Height of hexagon} = 2 \cdot \left( a \cdot \frac{\sqrt{3}}{2} \right) $$
Yielding Result:
$$ \text{Height of a regular hexagon with side length } a = a \sqrt{3} $$
Limits at infinity
Limits at Infinity: A Conceptual Overview
In mathematical analysis, the notion of a limit at infinity provides a rigorous framework for understanding the behavior of functions as their input grows arbitrarily large in magnitude. Specifically, we are interested in the asymptotic behavior of a function \(f(x) \) as \(x \to \infty \) (or \(x \to -\infty \)), that is, how \(f(x) \) behaves for sufficiently large values of \(x \).
Formally, we say that $$ \lim_{x \to \infty} f(x) = L $$ if for every \(\varepsilon > 0 \), there exists a real number \(N \) such that $$ x > N \Rightarrow |f(x) – L| < \varepsilon. $$ This definition captures the idea that the values of \(f(x) \) can be made arbitrarily close to \(L \) by taking \(x \) sufficiently large.
Limits at infinity play a crucial role in the study of convergence, asymptotics, and the global behavior of functions.
Continuing to derive the solution
Simplifying the focus
We begin by exploiting the inherent sixfold rotational symmetry, we reduce the problem “modulo 6”-style, effectively restricting our attention to a single fundamental sector (i.e one \(60\) degree sector). By doing so we simplify the analysis to just one representative section within this equivalence class.
If we restrict our view to along the direction of the blue arrow, we observe that the rotation lines align to form a straight “line” sequence. This linear arrangement reveals an underlying order that we can potentially use.
To proceed, we now seek an invariant, a quantity or structure that remains stable under the transformations, under consideration. The natural approach here is to introduce an auxiliary red arrow, aligned with the reference direction. By connecting this to each rotation line, we form triangles with a common “base”.
Let us now regard each line as encoding an angular offset, specifically, a rotation relative to a fixed reference direction given by the dark blue line (dual). , We can think of the red arrow as some sort of basis vector corresponding to the blue line . Our aim is to compute the rotational offset of each line with respect to this reference frame, treating the red arrow as a canonical representative of the direction encoded by the dark blue line.
Finding the general formula for the offset angle between the red arrow (a representation of the original dual) AND the \(n\)-case triangle
Dotted lines here are the lines we saw in the image earlier
Given:
Triangle with two sides:
Side 1: \(a \sqrt{3}\)
Side 2: \(a n \sqrt{3}\)
Included angle between them: \(120^\circ\)
Goal: Find the angle \(A\), opposite to the side \(a n \sqrt{3}\)
$$ c^2 = (a \sqrt{3})^2 + (a n \sqrt{3})^2 – 2 (a \sqrt{3})(a n \sqrt{3}) \cos(120^\circ) $$
Evaluate:
\((a \sqrt{3})^2 = 3 a^2\)
\((a n \sqrt{3})^2 = 3 a^2 n^2\)
\(2ab = 6 a^2 n\)
\(\cos(120^\circ) = -\frac{1}{2}\)
$$ c^2 = 3 a^2 + 3 a^2 n^2 + 3 a^2 n $$
$$ c^2 = 3 a^2 (n^2 + n + 1) $$
$$ c = a \sqrt{3 (n^2 + n + 1)} $$
Step 2: Use Law of Sines to find the angle opposite to \(a n \sqrt{3}\)
$$ \frac{\sin A}{a n \sqrt{3}} = \frac{\sin(120^\circ)}{c} $$
Substitute:
\(\sin(120^\circ) = \frac{\sqrt{3}}{2}\)
\(c = a \sqrt{3 (n^2 + n + 1)}\)
$$ \sin A = \frac{a n \sqrt{3}}{a \sqrt{3 (n^2 + n + 1)}} \times \frac{\sqrt{3}}{2} $$
Cancel \(a\):
$$ \sin A = \frac{n \sqrt{3}}{\sqrt{3 (n^2 + n + 1)}} \times \frac{\sqrt{3}}{2} $$
$$ \sin A = \frac{3 n}{2 \sqrt{3 (n^2 + n + 1)}} $$
Final Result for the ? angle:
$$ A = \sin^{-1} \left( \frac{3 n}{2 \sqrt{3 (n^2 + n + 1)}} \right) $$
Adjusting the Sequence for clearer understanding of the Asymptotics
We can now utilize the function defined above to generate the desired terms in the sequence. This brings us close to our objective. Upon closer inspection, we observe that the sequence aligns particularly well when interpreted as an angular offset. Specifically, as illustrated in the image below, we begin with the blue line corresponding to the case \(n = 0\), and for each subsequent value of \(n\), we proceed in a clockwise direction. (These lines correspond to the dotted rays shown in the previous image.)
Drawing a link between the symmetry and this
Originally, by leveraging the underlying symmetry of the problem, we simplified the analysis by focusing in a single direction, meaning in other words, we can intuitively infer that the sequence “resets” every 60 degrees.
Now instead, we can analyze the limiting behavior of the relevant angle in the \(n\)-th triangle considered earlier. As \(n\) grows large, the angle opposite the red line (the \(a \sqrt{3}\) side), which we denote by \(\omega\), decreases towards zero. Formally, this can be expressed as
$$ \lim_{n \to \infty} \omega = 0. $$
Using the triangle angle sum formula, the angle of interest (the ?, but lets call it \(\phi\)), satisfies
$$ \phi = 180^\circ – 120^\circ – \omega. $$
Therefore,
$$ \lim_{n \to \infty} \phi = 60^\circ, $$
showing that the sequence converges to \(60^\circ\).
Final Adjustment of the formula to reflect the rotation of the original dual and the intuition above
Thus, from both a mathematical (okay maybe more so an aesthetic) standpoint, it is preferable to redefine the sequence so that it converges to zero. This aligns with the conceptual goal of determining ‘how much to rotate’ the original dual structure to obtain the \(n\)-th dual. In its current form, the sequence converges to a fixed offset (specifically, \(60^\circ\)), which, at first glance, is not immediately apparent from the formula.
To clarify what is meant by ‘converging to zero’: when we rotate the original dual by any multiple of \(60^\circ\) (i.e., an element of \(60\mathbb{Z}\)), we return to the original dual; similarly, a rotation by \(30\mathbb{Z}\) yields the 2-close interaction. In this context, we seek a rotation angle \(\theta\) such that \(\theta \cdot \mathbb{Z}\) captures the \(n\)-close interaction, and thus, it is natural to define \(\theta\) as a function of \(n\) that tends to zero as \(n \to \infty\). This reframing reveals the underlying structure more clearly and places the emphasis on the relative rotation required to reach the \(n\)-th configuration from the base case.
This sequence tending to zero carries a natural interpretation: it suggests diminishing deviation or adjustment over time. This aligns well with the intuition that as \(n\) increases, the system or pattern is “settling down” or tending to the reset point. In contrast, convergence to a nonzero constant may obscure this interpretation (unless you know a-priory about the symmetries of this system) , since the presence of a persistent offset implies a kind of residual asymmetry or imbalance. By ensuring that the sequence vanishes asymptotically, we emphasize convergence toward a limiting behavior centered at zero.
This was the justification to introducing a subtraction of 60 in front of the A earlier to consider the sequence in the original notion of rotation of the dual instead. Yielding us
After this adjustment, hopefully it becomes apparent, even from a quick inspection of the formula, that the constant \(60\) plays a fundamental role in limiting structure of the problem.
Thus we have
The Problem is not finished
Now, reintroducing the 6-fold symmetry and examining the superposition of plots corresponding to the 1-close through \(n\)-close interactions (for increasingly large values of \(n\)), we observe:
But wait … this does not cover the full grid. It’s clearly missing parts! You scammed me! Well yes but not quite as I did mention at the start
“…closed-form startingstep”
Srivathsan Amruth, You really didn’t think I was going to give you the full answer right…
I intentionally stopped here, as I want you to explore the problem further and realize that there are, in fact, additional symmetries you can exploit to fully cover the hexagonal grid. I’ll leave you with a the following hint to start:
Consider the 1-ray case and its associated \(60^\circ\) cone.
Now look at the 3-close case (green) and the 2-close case (purple). Ask yourself: can I flip something to fill in the missing part of the 3-close structure?
Then, move on to the 4-close case. Since (spoiler) there will be two distinct 3-close components involved, can I once again use flipping to complete the picture? And if so, how many times, and where, should these flips occur?
It’s getting quite recursive from here… but I’ll let you figure out the rest.
Also, I’ll leave you with one final thought, i.e is there a way to avoid this recursive construction altogether or simplify the approach, and instead generate the full structure more efficiently using some iterative or closed-form approach?
Wishing you a hex-tra special day ahead with every piece falling neatly into place.
Srivathsan Amruth, i.e The person guiding offering you through this symmetry-induced spiral.
The goal of this post is to celebrate the question. History’s greatest intellectual leaps often began not with the answer itself, but with the journey of tackling a problem. Hilbert’s 23 problems charted the course of a good chunk of 20th-century mathematics. Erdős scattered challenges that lead to breakthroughs in entire fields. The Millennium Prize Problems continue to inspire and frustrate problem solvers.
There’s magic in a well-posed problem; it ignites curiosity and forces innovation. Since I am nowhere near the level of Erdős or Hilbert, today, we embrace that spirit with a maybe less well-posed but deceptively simple yet intriguing geometric puzzle on a disordered surface.
To this end, we present a somewhat geometric-combinatorial problem that bridges aspects of computational geometry, bond percolation theory and graph theory.
Problem Construction
We begin with the hexagonal lattice in \(\mathbb{R}^2\) (the two-dimensional plane), specifically the regular hexagonal lattice (also known as the honeycomb lattice). For visualisation, a finite subregion of this lattice tessellation of the plane is illustrated below.
We then enrich the information of our space by constructing centroids associated with each hexagon in the lattice. The guiding idea is to represent each face of the lattice by its centroid, treating these points as abstract proxies for the faces themselves.
These centroids are connected precisely when their corresponding hexagons share a common edge in the original lattice. Due to the hexagonal tiling’s geometry, this adjacency pattern induces a regular network of connections between centroids, reflecting the staggered arrangement of the hexagons.
This process yields a new structure: the dual lattice. In this case, the resulting dual is the triangular lattice.This dual lattice encodes the connectivity of the original tiling’s faces through its vertices and edges.
As a brief preview of the questions to come, our goal is to identify triangles within this expansive lattice. We begin by requiring that the vertices of these triangles originate from the centroids of the hexagonal faces. To then encode such triangular structures, we leverage both the primal and dual lattices, combining them so that the edges of these triangles can exist on any of the black paths shown in the diagram.
What is particularly interesting here is that the current construction arises from 1-neighbor connections, which we interpret as close-range interactions. However, this 1-neighbor primal-dual frameworkrestricts the set of possible triangles to only equilateral ones. (Personally, I feel this limits the complexity of potential problems.)
On this grid, every triangle’s got equal sides, I guess this side of math is tired of drama.Trying to spot a scalene here is like trying to find a unicorn in a math textbook.
To make the question more engaging and challenging, we seek to incorporate more “medium-to-further-range interactions“. This can be accomplished by connecting every secondneighbor in an analogous fashion, thereby constructing a “triple space“. The resulting structure forms another dual lattice that captures these extended adjacency relations, allowing for a richer variety of triangular configurations beyond the equilateral case. For generality, I will coin the term for this as 2-close-range-interactions.
A lazy yet elegant approach to achieve this is by rotating the original dual lattice by \(90\) degrees, or, more generally, by anymultiple of \(30\) degrees (i.e., \(30 \times n\) degrees , we will use this generality in the final section to extend the problem scope even further). We then combine this rotated lattice with the original construction.
We will illustrate the process below.
The 2-close-range interaction:
We begin, as before, with the original primal and dual lattices.
We now rotate the blue dual lattice by \(90\) degrees, as described previously.
Combining the rotated dual with the original, as before, yields the following structure and, as the keen eyed among you may notice, both the dual constructions covers the entire original primal hexagonal lattice.
This finally yields us the following existence space for the triangles.
And now, we witness the emergence of a richer and more interestingvariety of triangle configurations.
Wow, so many triangles to choose from here! Great, just what I wanted more problems(to select from)… wait, hold up…
The Random Interface
To introduce an interesting stochastic element to our problem, we draw inspiration from percolation theory (a framework in statistical physics that examines how randomness influences the formation of connected clusters within a network). Specifically, we focus on the concept of disorder, exploring how the presence of randomness or irregularities in a system affects the formation of connected clusters. In our context, this translates to the formation of triangles within the lattice.
Building upon the original hexagonal lattice, we assign to each edge a probability \(p\) of being “open” or “existent”, and consequently, a probability \(1 – p\) of being “closed” or “nonexistent”. This approach mirrors the bond percolation model, where edges are randomly assigned to be open or closed, independent of other edges. The open edges allow for the traversal of triangle edges, akin to movement through a porous medium, facilitating the formation of triangles only through the connected open paths.
We illustrate using the figure a sample configuration when \(p = 0.5\), where the red “exit” edges represent “open” edges that allow triangles to traverse through the medium.
Rules regarding traversal of this random interface:
As mentioned earlier, every red “open” gate permits traversal. To define this traversal more clearly in our problem setting, we can visualise using the following.
In the 2-close-range interaction case, this traversal is either in the tangential direction
Apologies for the somewhat messy hand-drawn centroids and wonky arrows…
or in the normal direction.
Once again ignore the horribly hand-drawn centroids please… Also note that in both cases, the arrows (specifically the arrowheads) are included purely for illustrative purposes. The traversal can be considered bidirectional, depending on the context; that is, each triangle may be treated either as an undirected or a directed graph, depending on the construction method being employed by the problem solver (i.e you 😉 ).
An aside on Interaction Modeling
This model assumes that long-range interactions emerge from specified short-range interactions. We can see this in our construction of the 2-close explicitly excluding any secondary dual lattice edges (2-close interactions) that can be generated from first-neighbor edges (1-close interactions). This ensures that the secondary dual lattice contains only truly second-neighbor interactions not implied by (or that goes through) the first-neighbor structure, preserving a clear hierarchical interaction scheme.
The Problems
An “Easy” starting question :
Given some finite subsection of this random interface, construct an algorithm to find the largest triangle (in terms of perimeter or area, your choice of definition for the problem depending on which variant of the problem you want to solve) .
Attempt at formalising this
1) Definition of Lattices
Hexagon Lattice
Let the hexagonal lattice be denoted by: $$ H = (C, E_h) $$
where:
\(C = { c_i } \subset \mathbb{R}^2\) is the set of convex hexagonal cells that partition the Euclidean plane \(\mathbb{R}^2\),
\(E_h = { (c_i, c_j) \in C \times C \mid c_i \text{ and } c_j \text{ share a common edge} }\) is the adjacency relation between hexagons.
Each hexagon edge \(e_h \in E_h\) is activated independently with probability \(p \in [0,1]\): $$ \Pr(\sigma_h(e_h) = 1) = p, \quad \Pr(\sigma_h(e_h) = 0) = 1-p $$
Primary Dual Lattice \(T_1 = (V, E_t^{(1)})\)
The primary dual lattice connects centroids of adjacent hexagons: $$ E_t^{(1)} = \left \{ (v_i, v_j) \in V \times V \,\middle|\, (c_i, c_j) \in E_h \right \} $$
Secondary Dual Lattice \(T_2 = (V, E_t^{(2)})\)
The secondary dual lattice captures 2-close interactions. An edge \((v_i, v_j) \in E_t^{(2)}\) exists if and only if:
\(c_i \neq c_j\) and \((v_i, v_j) \notin E_t^{(1)}\) (i.e., not first neighbors),
There exists a common neighboring cell \(c_k \in C\) such that: $$ (c_i, c_k) \in E_h \quad \text{and} \quad (c_j, c_k) \in E_h $$
The straight-line segment \(\overline{v_i v_j}\) does not lie entirely within \(c_i \cup c_j \cup c_k\): $$ \overline{v_i v_j} \not\subseteq c_i \cup c_j \cup c_k $$
In other words, a dual edge is activated only if it corresponds spatially to a hexagon edge that is itself activated, either by lying exactly on it or intersecting it at right angles.
3) Interaction Constraints
Local Traversal: Paths across the lattice are constrained to activated edges: $$ P(v_a \rightarrow v_b) = { e_1, e_2, \dots, e_k \mid \sigma(e_i) = 1,\ e_i \in E_t } $$
Cardinality: $$ \deg_{T_1}(v_i) \leq 6, \quad \deg_{T_2}(v_i) \leq 6 $$ Each vertex connects to at most 6 first neighbors (in \(T_1\)) and at most 6 geometrically valid second neighbors (in \(T_2\)).
4) Triangle Definition
A valid triangle \(\Delta_{abc} = (v_a, v_b, v_c)\) must satisfy:
Connectivity: All three edges are activated: $$ \sigma(v_a v_b) = \sigma(v_b v_c) = \sigma(v_c v_a) = 1 $$
Embedding: The vertices \((v_a, v_b, v_c)\) form a non-degenerate triangle in \(\mathbb{R}^2\), preserving local lattice geometry.
Perimeter: Defined as the total edge length: $$ P(\Delta_{abc}) = |v_a – v_b| + |v_b – v_c| + |v_c – v_a| $$
Area: Using the standard formula for triangle area from vertices: $$ A(\Delta_{abc}) = \frac{1}{2} \left| (v_b – v_a) \times (v_c – v_a) \right| $$ where \(\times\) denotes the 2D scalar cross product (i.e., determinant).
Triangles may include edges from either \(E_t^{(1)}\) or \(E_t^{(2)}\) as long as they meet the activation condition.
5) Optimization Objective
Given the dual lattice \(T = (V, E_t)\) and activation function \(\sigma: E_t \rightarrow \{0,1\}\), the goal is to find the valid triangle maximizing either:
subject to \(\Delta_{abc}\) being a valid triangle.
Example of a triangle we can find in this sample of random interface.
Harder Open Questions:
1) What are the scaling limit behaviors of the triangle structures that emerge as the lattice size grows?
In other words: As we consider larger and larger domains, does the global geometry of triangle configurations converge to some limiting structure or distribution?
Ideas to explore:
Do typical triangle shapes concentrate around certain forms?
Are there limiting ratios of triangle types (e.g., equilateral vs. non-equilateral)?
Does a macroscopic geometric object emerge (in the spirit of scaling limits in percolation, e.g., SLE curves on critical lattices)?
An attempt to formalise this would be as follows :
Let’s denote by \(T_p(L)\) the set of all triangles that can be formed inside a finite region of side length \(L\) on our probabilistic lattice, where each edge exists independently with probability \(p\).
Conjecture: As \(L\) becomes very large (tends to infinity), the distribution of triangle types (e.g. equilateral, isosceles, scalene, acute, obtuse, right-angled) converges to a well-defined limiting distribution that depends only on \(p\). (i.e converges in law to some limiting distribution \(\mu_p\). )
Interpretation of expected behaviours:
For high \(p\) (near 1), most triangles are close to equilateral.
For low \(p\) (near 0), triangles become rare or highly irregular.
This limiting distribution, \(\mu_p\) , tells us the “global shape profile” of triangles formed under randomness.
2) How does the distribution of triangle types (e.g., equilateral, isosceles, scalene; or acute, right, obtuse) vary with the probability parameter \(p\)?
Why this matters: At low \(p\), triangle formation is rare, and any triangle that does form may be highly irregular. As \(p\) increases, more symmetric (or complete) structures may become common.
Possible observations:
Are equilateral triangles more likely to survive at higher \(p\) due to more consistent connectivity?
Do scalene or right-angled triangles dominate at intermediate values of \(p\) due to partial disorder?
Is there a characteristic “signature” of triangle types at criticality?
3) Can we define an interesting phase transition in this setting, marking a shift in the global geometry of the triangle space?
In other words: As we gradually increase the edge probability $p$, at what point does the typical shape of the triangles we find change sharply?
An attempt to formalise this would be as follows :
There exist two critical probability values \(p_1\) and \(p_2\) (where \(0 < p_1 < p_2 < 1\)) that mark qualitative transitions in the kinds of triangles we typically observe.
Conjecture:
When \(p < p_1\), most triangles that do form are highly irregular (i.e scalene).
When \(p_1 < p < p_2\), the system exhibits a diverse mix of triangle types (now we have more equilateral, isosceles with less domination of scalene; and variations of acute, right-angled, and obtuse).
When \(p > p_2\), the triangles become increasingly regular, and equilateral triangles dominate.
This suggests a “geometric phase transition” in the distribution of triangle shapes, driven purely by the underlying connectivity probability.
4) Is there a percolation threshold at which large-scale triangle connectivity suddenly emerges?
Let’s define a triangle cluster as a set of triangles that are connected via shared edges or vertices (depending on your construction). We’re interested in whether such triangle clusters can become macroscopically large.
Conjecture: There exists a critical probability \(p_c\) such that:
If \(p < p_c\), then all triangle clusters are finite (they don’t span the system).
If \(p > p_c\), then with high probability (as the system size grows), a giant triangle cluster emerges that spans the entire domain.
This is analogous to the standard percolation transition, but now with triangles instead of edge or site clusters.
(The first attempt setting up this was whether a single giant triangle can engulf the whole space but in retrospect, this would not be possible and is not such an interesting question.)
5) Results on Triangle Density
As we grow the system larger and larger, does the number of triangles per unit area settles down to a predictable average, but this average depends heavily on the edge probability $p$.
Let \(N_p(L)\) denote the total number of triangles formed within a square region of side length \(L\).
We define the triangle density as
$$ \rho_p(L) := \frac{N_p(L)}{L^2}, $$
which is the average number of triangles per unit area.
Conjecture: As \(L \to \infty\), the triangle density converges to a deterministic function \(\rho(p)\): $$ \lim_{L \to \infty} \rho_p(L) = \rho(p). $$ (Here, \(\rho(p)\) captures the asymptotic average density of triangles in the infinite lattice for edge probability \(p\).)
Furthermore, the variance of \(N_p(L)\) satisfies $$ \mathrm{Var}[N_p(L)] = o(L^4), $$ (i.e variance of the number of triangles grows more slowly than the square of the area)
which implies the relative fluctuations: $$ \frac{\sqrt{\mathrm{Var}[N_p(L)]}}{L^2} \to 0. $$ vanish as \(L \to \infty\).
The function \(\rho(p)\) is analogous to the percolation density in classical bond percolation, which measures the expected density of occupied edges or clusters. Just as percolation theory studies the emergence and scaling of connected clusters, here \(\rho(p)\) characterizes the density of geometric structures (triangles) emerging from random edge configurations.
The sublinear variance scaling reflects a law of large numbers effect in spatial random graphs: as the region grows, the relative randomness in triangle counts smooths out, enabling well-defined macroscopic statistics.
This parallels known results in random geometric graphs and continuum percolation, where densities of subgraph motifs stabilize in large limits. This behavior may also hint at connections to scaling exponents or universality classes from statistical physics. (With certain constraints, could classify the triangles or regions of connected triangles as interfaces and make connections with KPZ type problems too, possibly another conjecture but I think 5 problems to think about are more than enough for now.)
What are some applications?
While I approach this problem primarily from a theoretical lens, with an interest in its mathematical structure and the questions it naturally raises, I also recognize that others may find motivation in more tangible or applied outcomes. To speak to that perspective, I include two detailed examples that illustrate how ideas from this setting can extend into meaningful real-world contexts. The aim is not to restrict the problem’s scope to practical ends, but to show how the underlying tools and insights may resonate across domains and disciplines.
—–//—–
Application1
1) Retopology of a 3D Scan
Consider the setting of high-resolution 3D scanning, where millions of sample points capture the geometry of a complex surface. These points are typically distributed (or essentially clumped) within an \(\varepsilon\)-thick shell around the true surface geometry, often due to the scan exhibiting local noise, redundancy, or sampling irregularities. Within this context, our framework finds a natural interpretation.
One can view the scan as a point cloud embedded on a virtual, warped hexagonal lattice, where the underlying lattice geometry adapts to local sampling density. By introducing a probability field, governed by factors such as local curvature, scan confidence, or spatial regularity, we assign likelihoods to potential connections between neighboring points.
In this formulation, the task of finding large, connected configurations of triangles corresponds to the process of identifying coherent, semantically meaningful patches of the surface. These patches serve as candidates for retopologization (the construction of a low-resolution, structured mesh that preserves the essential geometric features of the scan while filtering out noise and redundancies). This resulting mesh is significantly more amenable to downstream applications such as animation, simulation, or interactive editing.
The nearest-neighbor locality constraint we impose reflects a real physical prior, i.e mesh edges should not “jump” across unconnected regions of the surface. This constraint promotes local continuity and geometric surface fidelity.
Application 2
2) Fault Line Prediction in Material Fracture
In materials science, understanding how fractures initiate and propagate through heterogeneous media is a central problem. At microscopic scales, materials often have grain boundaries, impurities, or irregular internal structures that influence where and how cracks form. This environment can be abstracted as a disordered graph or lattice, where connections (or lack thereof) between elements model structural integrity or weakness.
We can reinterpret such a material as a random geometric graph laid over a deformed hexagonal lattice, with each connection representing a potential atomic or molecular bond. Assign a probability field to each edge, governed by local stress, strain, or material heterogeneity, capturing the likelihood that a bond remains intact under tension.
Triangles in this setting can be thought of as minimal stable configurations. As stress increases or defects accumulate, connected triangle structures begin to break down. By tracking the largest connected triangle regions, one may identify zones of high local integrity, while their complement reveals emergent fault lines, regions where fracture is likely to nucleate.
Thus, searching for maximal triangle clusters under stochastic constraints becomes a method for predicting failure zones before actual crack propagation occurs. Moreover, one can study how the geometry and size distribution of these triangle clusters vary with external stress or material disorder, giving rise to scaling laws or percolation-like transitions.
This formulation connects naturally with known models of fracture networks, but adds a new geometric lens: triangulated regions become proxies for mechanical stability, and their disintegration offers a pathway to understand crack emergence.
—–//—–
Again these are just two specific lenses. At its core, the problem, finding large-scale, connected substructures under local stochastic constraints, arises across many domains. It is easy to reformulate and adjust the constraints to use the tools developed here in other problems.
Auxiliary Insights
When constructing triangles, one can consider the set of paths accessible from a single vertex. To aid visualization, refer to the diagram below.
The blue paths are from the 1-close connections, while the pink paths correspond to 2-close connections. Together, they provide each vertex with a total of \(6 + 6 = 12\) possible directions or “degrees of freedom” along which it may propagate to form triangle edges.
Notably, the system exhibits a high degree of rotational symmetry, both the 1-close and 2-close path structures are invariant under rotations by \(60^\circ\). This symmetry can potentially be leveraged to design efficient search algorithms or classification schemes for triangle types within the lattice.
Extension to the n-close case
So far, we’ve been using triangles as a proxy for a special class of simple closed-loop interaction pathways (i.e structures formed by chaining together local movements across the lattice). Specifically we restricted ourselves to the 1- and 2-close interaction setting.
Naturally, a question arises: can we generalize this further? Specifically, what sort of angular adjustment or geometric rule would be needed to define an n-close interaction, beyond the 1- and 2-close cases we’ve explored? (When looking above at the auxillery and the construction of the 2-close, we can see that we use the \(30\) degree rotation offset at the basis.)
This leads to a broader and richer family of questions. In my other blog post (will be linked soon after it is posted) , I’ll pose precisely this: “How can we extend the 2-close interaction to a general n-close interaction?” . There, I’ll also provide a closed-form formula for generating any term in the sequence of such $n$-close interactions.
As always, I encourage you to attempt the question yourself before reading the solution, it may seem straightforward at first, but the correct sequence or geometric structure is not always immediately obvious.
Final Thoughts
Crafting this problem, presenting some drawings and formalising certain aspects was an interesting challenge for me. As always, I welcome any feedback on how to improve the presentation or to formalise certain sections more rigorously if you have any ideas. I’m especially looking forward to seeing and reading about any progress made on the questions posed here, attempts at their variations, or even presentation of potential applications.
Cheers and have an hex-traordinary day ahead!
Srivathsan Amruth i.e The writer of this masterpiece chaotic word salad, who apologizes for your lost minutes Hey, why are you still reading? … Shouldn’t you be pretending to work? ; – )
Recall (from post 1/2) that while DeepSDFs are a powerful shape representation, they are not inherently topology-preserving. By “preserving topology,” we mean maintaining a specific topological invariant throughout shape deformation. In low-dimensional latent spaces \(z_{\text{dim}} = 2\), linear interpolation between two topologically similar shapes can easily stray into regions with a different genus, breaking that invariant.
Visualizing genera count in 2D latent space
Higher-dimensional latent spaces may offer more flexibility—potentially containing topology-preserving paths—but these are rarely straight lines. This points to a broader goal: designing interpolation strategies that remain within the manifold of valid shapes. Instead of naive linear paths, we focus on discovering homotopic trajectories—routes that stay on the learned shape manifold while preserving both geometry and topology. In this view, interpolation becomes a trajectory-planning problem: navigating from one latent point to another without crossing into regions of invalid or unstable topology.
Pathfinding in Latent Space
Suppose you are a hiker hoping to a reach a point \(A\) from a point \(B\) amidst a chaotic mountain range. Now your goal is to plan your journey so that there will be minimal height change in your trajectory, i.e., you are a hiker that hates going up and down much! Fortunately, an oracle gives us a magical device, let us call it \(f\), that can give us the exact height of any point we choose. In other words, we can query \(f(x)\) for any position \(x\), and this device is differentiable, \(f'(x)\) exists!
Metaphors aside, the problem of planning a path from a particular latent vector \(A\) to another \(B\) in the learned latent space would greatly benefit from another auxiliary network that learns the mapping from the latent vectors to the desired topological or geometric features. We will introduce a few ways to use this magical device – a simple neural network.
Gradient as the Compass
Now the best case scenario would be to stay at the same height for the whole of the journey, no? This greedy approach puts a hard constraint on the problem, but it also greatly reduces the possible space of paths to take. For our case, we would love to move toward the direction that does not change our height, and this set of directions precisely forms the nullspace of the gradient.
No height change in mathematical terms means that we look for directions where the derivatives equal zero, as in
$$D_vf(x) = \nabla f(x)\cdot v = 0,$$
where the first equality is a fact of the calculus and the second shows that any desirable direction \(v\in \text{null}(\nabla f(x))\).
This does not give any definitive directions for a position \(x\) but a set of possible good directions. Then a greedy approach is to take the direction that aligns most with our relative position against the goal – the point \(B\).
Almost done, but the problem is that if we always take steps with the assumption that we are on the correct isopath, we would end up accumulating errors. So, we actually want to nudge ourselves a tiny bit along the gradient to land back on the isopath. Toward this, let \(x\) be the current position and \(\Delta x=\alpha \nabla f(x) + n\), where \(n\) is the projection of \(B-x\) to \(\text{null}(\nabla f(x))\). Then we want \(f(x+\Delta x) = f(B)\). Approximate
Now we just take \(\Delta x = \frac{f(B) – f(x)}{|\nabla f(x)|^2}\nabla f(x) + \text{proj}_{\text{null}(\nabla f(x))} (B- x)\) for each position \(x\) on the path.
Results. Latent to expected volume.
Optimizing Vertical Laziness
Sometimes it is impossible to hope for the best case scenario. Even when \(f(A)=f(B)\), it might happen that the latent space is structured such that \(A\) and \(B\) are in different components of the level set of the function \(f\). Then there is no hope for a smooth hike without ups and downs! But the situation is not completely hopeless if we are fine with taking detours as long as such undesirables are minimized. We frame the problem as
where \(L\) is the latent space and \({x_i}_{i=1}^n\) is the sequence defining the path such that \(x_1 = A\) and \(x_n=B\). The first term is to encourage consistency in the function values, while the second term discourages sudden changes in curvature, thereby ensuring smoothness. Once defined, various gradient-based optimization algorithms can be used on this problem, which is now imposed with a relatively soft constraint.
Results of pathfinding via optimization in different contexts.
Latent to expected volume.
Latent to expected genus.
A Geodesic Path
One alternative attempt of note to optimize pathfinding used the concept of geodesics, or the shortest, smoothest distance between two points on a Riemannian manifold. In the latent space, one is really working over a latent data manifold, so thinking geometrically, we experimented with a geodesic path algorithm. In writing this algorithm, we set our two latent endpoints and optimized the points in between by minimizing the energy of our path on the output manifold. This alternative method worked similarly well to the optimized pathfinding algorithm posed above!
Conclusion and Future Work
Our journey into DeepSDFs, gradient methods, and geodesic paths has shown both the promise and the pitfalls of blending multiple specialized components. The decoupled design gave us flexibility, but also revealed a fragility—every part must share the same initialized latent space, and retraining one element (like the DeepSDF) forces a retraining of its companions, the regressor and classifier. With each component carrying its own error, the final solution sometimes felt like navigating with a slightly crooked compass.
Yet, these challenges are also opportunities. Regularization strategies such as Lipschitz constraints, eikonal terms, and Laplacian smoothing may help “tame” topological features, while alternative frameworks like diffeomorphic flows and persistent homology could provide more robust topological guarantees. The full integration of these models remains a work in progress, but we hope that this exploration sparks new ideas and gives you, the reader, a sharper sense of how topology can be preserved—and perhaps even mastered—in complex geometric learning systems.
Genus is a commonly known and widely applied shape feature in 3D computer graphics, but there is also a whole mathematical menu of topological invariants to explore along with their preservation techniques! Throughout our research, we also considered:
Would topological accuracy benefit from a non-differentiable algorithm (e.g. RRT) that can directly encode genus as a discrete property? How would we go about certifying such an algorithm?
How can homotopy continuation be used for latent space pathfinding? How will this method complement continuous deformations of homotopic and even non-homotopic shapes?
What are some use cases to preserve topology, and what choice of topological invariant should we pair with those cases?
We invite all readers and researchers to take into account our struggles and successes in considering the questions posed.
Acknowledgements. We thank Professor Kry for his mentorship, Daria Nogina and Yuanyuan Tao for many helpful huddles, Professor Solomon for his organization of great mentors and projects, and the sponsors of SGI for making this summer possible.