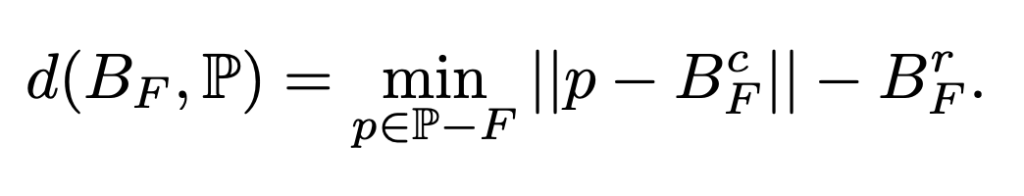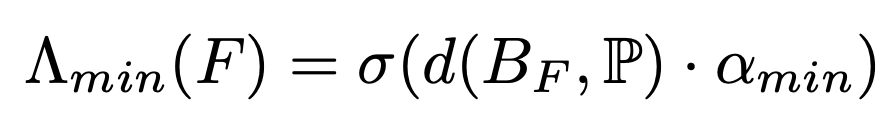Our work was carried out under the mentorship of Yi Zhuo from Adobe Research, whose guidance was instrumental and very much appreciated. We also thank Sanghyun Son , the first author of the original DMesh and DMesh++ , for generously sharing his insights and providing invaluable input.
Article Composed By: Gabriel Isaac Alonso Serrato in collaboration with Amruth Srivathsan
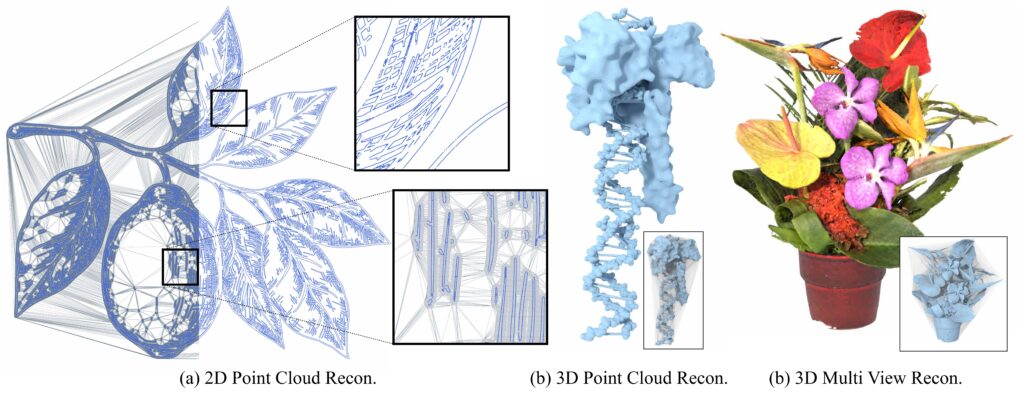
This article introduces Differentiable Mesh++ (DMesh++), exploring what a mesh is, why discrete mesh connectivity blocks gradient flow, how probabilistic faces restore differentiability, and how a local, GPU-friendly tessellation rule replaces a global weighted Delaunay step. We close with a practical optimization workflow and representative applications.
WHAT IS A MESH?
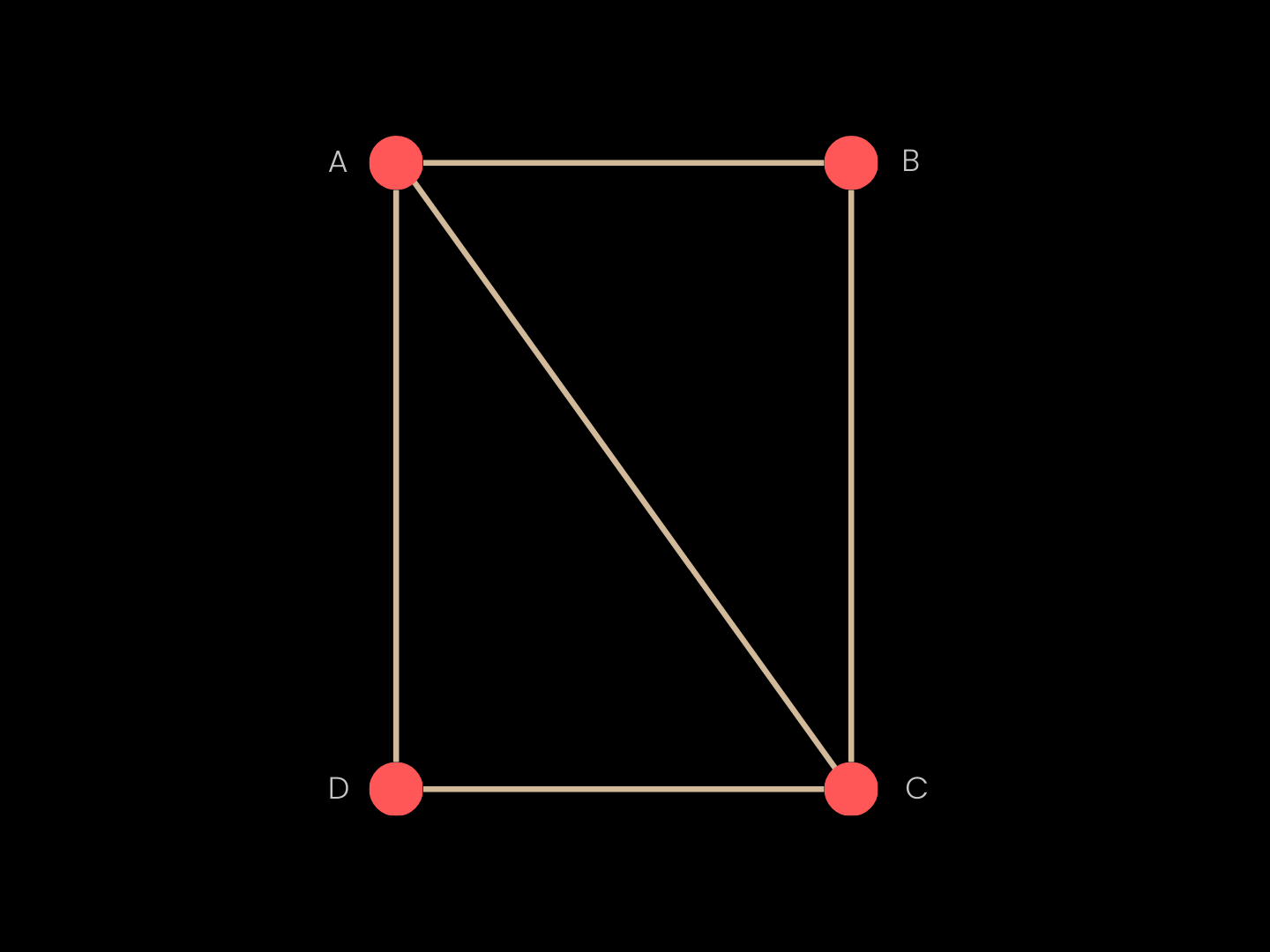
A triangle mesh combines geometry and topology. Geometry is given by vertex coordinates (named points in space such as A, B, C, and D) while topology specifies which vertices are connected by edges and which triplets form triangular faces (e.g., ABC, ACD). Together, these define shape and structure in a compact representation suitable for rendering and computation on complex surfaces.
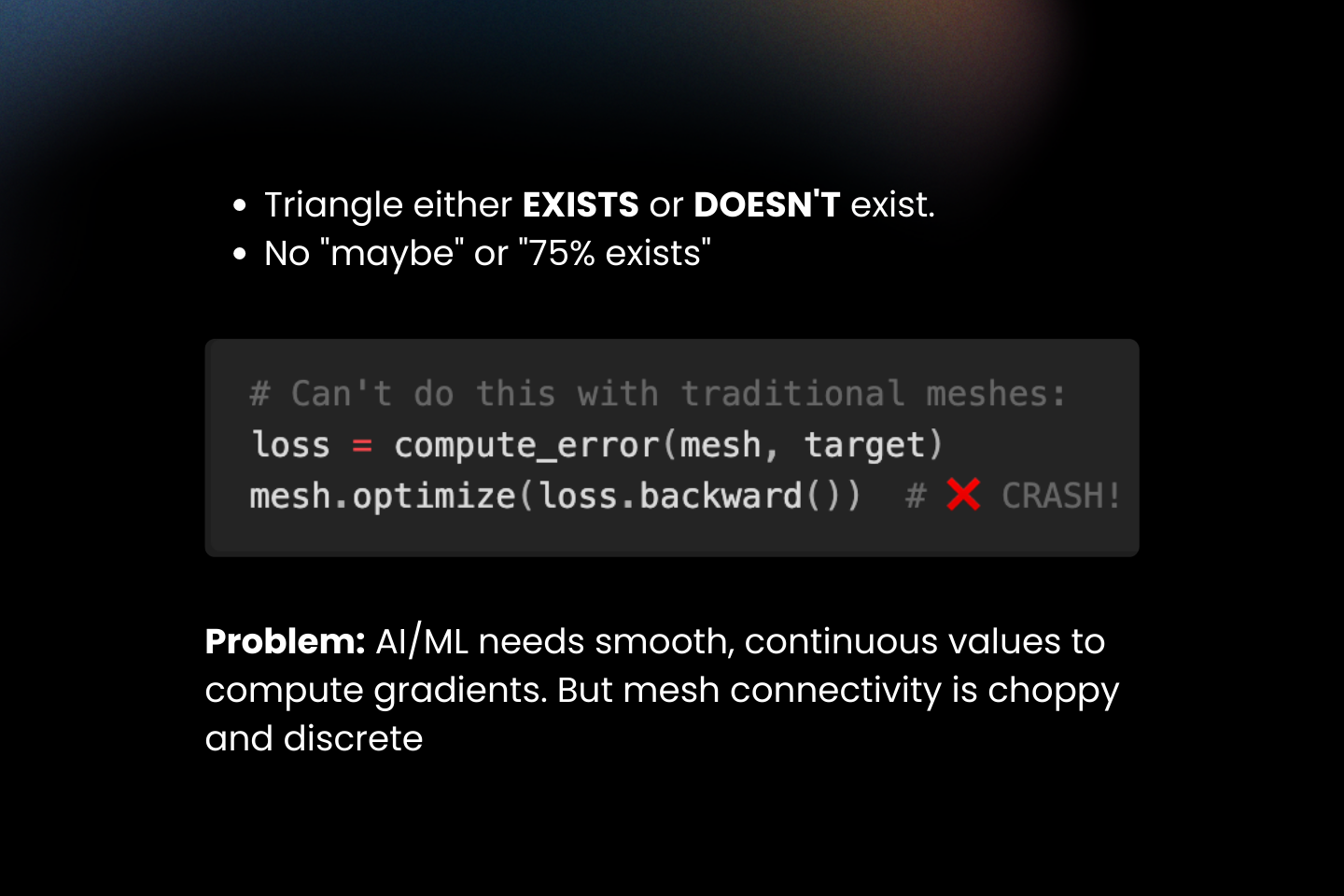
Why Traditional Meshes Fight Gradients?
Classical connectivity is discrete: a triangle either exists or it does not. Gradient-based learning, however, requires smooth changes. When connectivity flips on or off, derivatives vanish or become undefined through those choices, preventing gradients from flowing across topology changes and limiting end-to-end optimization
Differentiable Meshes
Gradients are essential for learning-based pipelines, where losses may be defined in image space, perceptual space, or 3D metric space.
Differentiable formulations make it possible to propagate error signals from rendered observations or physical constraints back to vertex positions, enabling tasks such as inverse rendering, shape optimization, and end-to-end 3D reconstruction. This bridges the conceptual gap between discrete geometry and continuous optimization, allowing mesh-based representations to function as both modeling primitives and trainable structures.
How DMesh++ Works
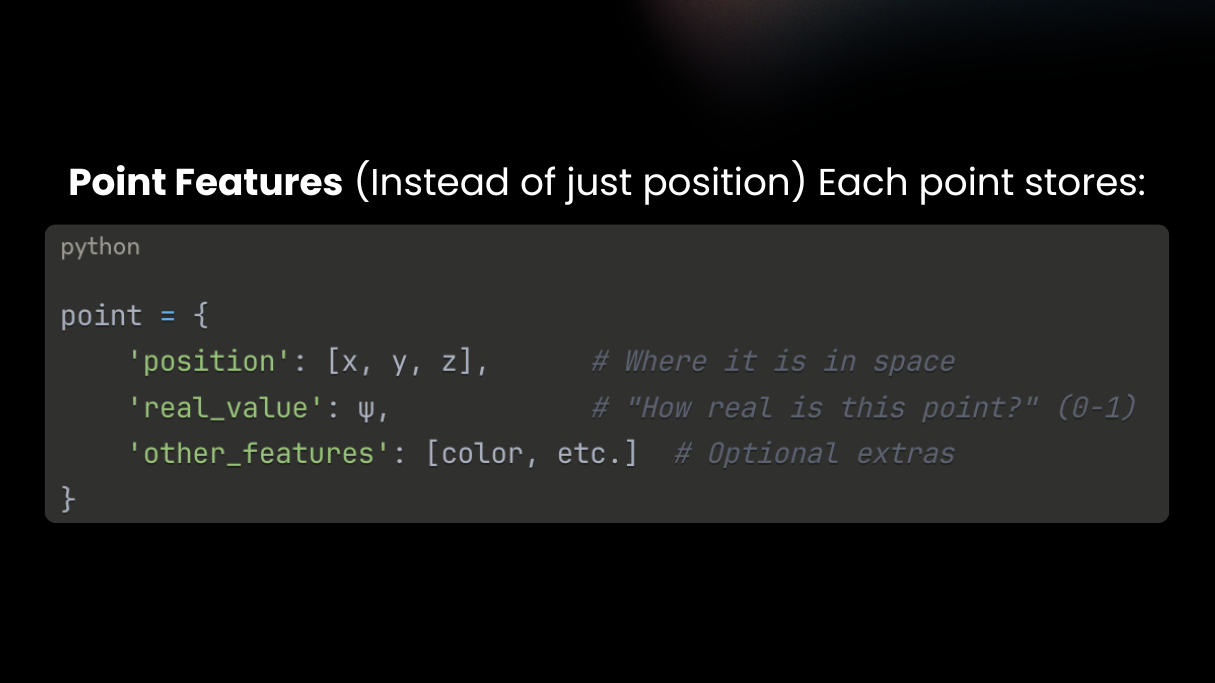
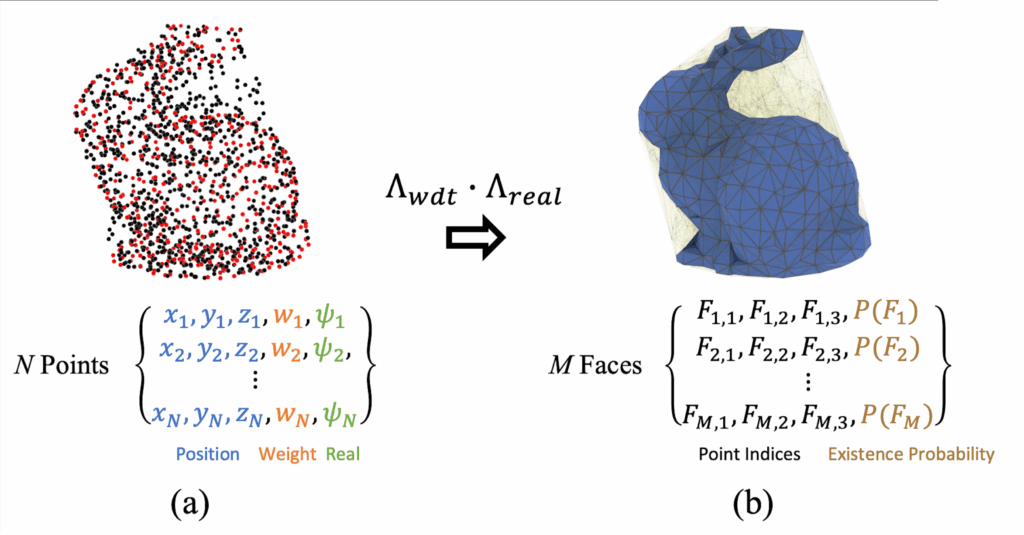
DMesh++ makes meshing a differentiable, GPU-native step. Each point carries learnable features (position, a “realness” score ψ, and optional channels).
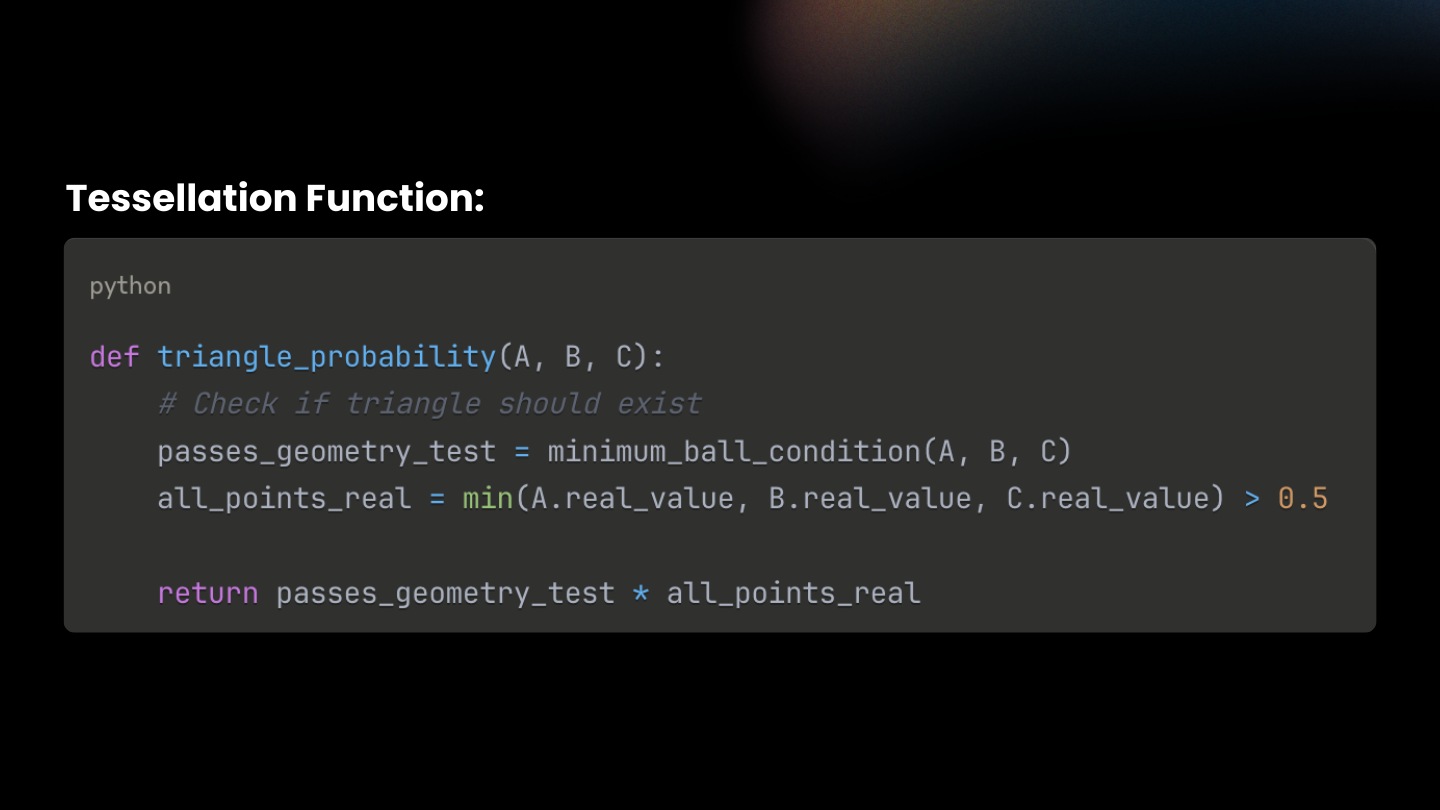
A soft tessellation function turns any triplet into a triangle weight rather than a hard on/off face.
During training, losses back-propagate to both positions and features, so connectivity can evolve smoothly.
The “One-Line” Idea in DMesh++
In DMesh++, we replace WDT (Λwdt )
with a local Minimum-Ball test ( Λmin ) when scoring each candidate face. Instead of rebuilding a global structure, we only check the smallest ball touching the face’s vertices and see if any other point lies inside it. This can be done quickly with k-nearest neighbor search on the GPU. The face probability is now:
Λ(F) = Λmin(F) × Λreal(F)
Λmin(F)says, “Is this face even eligible as part of a good tessellation?” (now via the Minimum-Ball test)
Λreal(F) says, “Is this face on the real surface?” (a differentiable min over the per-point realness ψ)
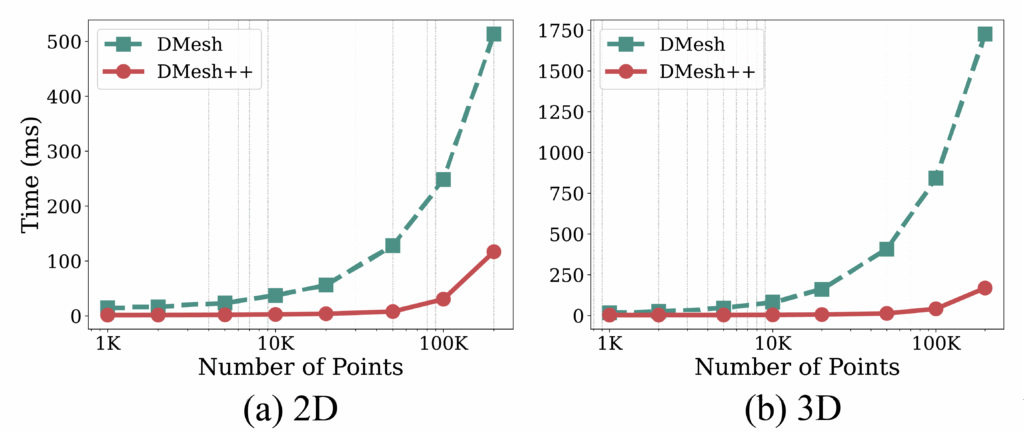
This swap reduces the effective evaluation cost from O(N) (WDT) to O(log N) with k-NN and parallelization, in practice, achieving speeds up to 16× faster in 2D and 32× faster in 3D, with significant memory savings.
Minimum-Ball, Explained
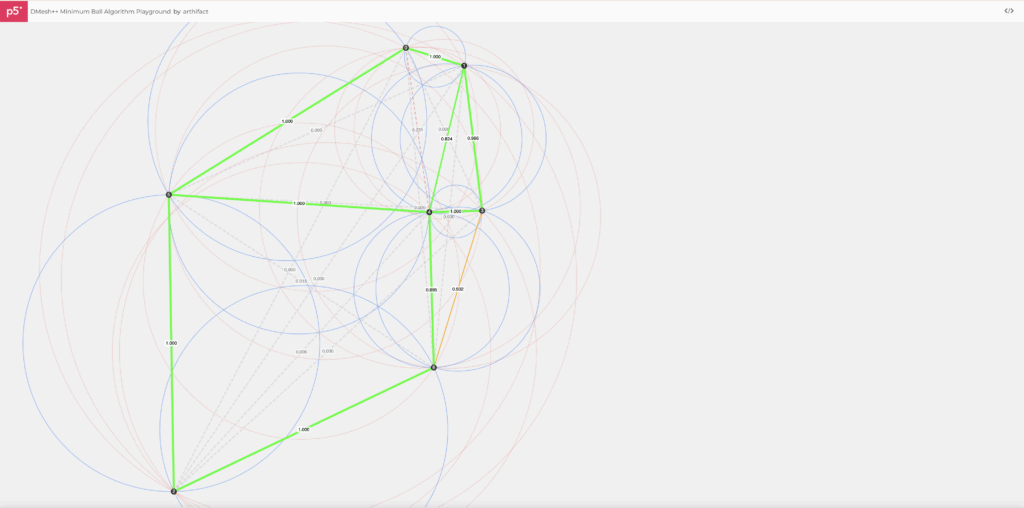
Pick a candidate face F (segment in 2D, triangle in 3D). Compute its minimum bounding ballBF : the smallest ball that touches all vertices of F.
Now check: is any other point strictly inside that ball? If no, F passes. If yes, reject. That’s the Minimum-Ball condition. (It’s a subset of Delaunay, so you inherit good triangle quality and avoid self-intersections.)
DMesh++ makes this soft and differentiable. It computes a signed distance between BF and the nearest other Point and runs it through a sigmoid to get Λmin :
Click on the canvas to drop points. Every pair of points becomes a candidate edge F. We draw the minimum ballBF (the smallest circle touching the two endpoints) and compute a soft eligibility via a sigmoid of its clearance to the nearest third point:
Because faces are probabilistic, the topology can change cleanly during optimization. You don’t hand-edit connectivity; it emerges from the features.
Recap: A Practical Optimization Workflow
Start: Begin with points (positions + realness ψ)
Candidates: Form nearby faces (via k-NN)
Minimum-Ball: For each face, find the smallest ball touching its vertices (if no point is inside, it’s valid) → gives Λₘᵢₙ
Weight by Realness: Multiply by vertex ψ to get final probability Λ = Λₘᵢₙ × Λᵣₑₐₗ
Optimize: Compute the loss (e.g., Chamfer), and backpropagate to update the points and ψ
Output: Keep high-Λ faces → final differentiable mesh
Some Applications of DMesh++
DMesh++ demonstrates how differentiable meshes can power real applications. Here are some ideas:
Generative Design: Train models that evolve shapes and topology for creative or engineering tasks without manual remeshing.
Adaptive Level of Detail: Automatically refine or simplify geometry based on learning signals or rendering needs.
Feature-Aware Reconstruction: Learn geometric structure, merge fragments, or fill missing regions directly through optimization.
Neural Simulation: Enable physics or visual simulations where mesh shape and motion are optimized end-to-end with gradients.
Future Directions
Looking ahead, future work on DMesh++ could focus on improving usability and scalability, for example, by developing more accessible APIs, real-time visualization tools, and integration with common 3D software. On the algorithmic side, enhancing the tessellation functions for higher precision and stability, expanding support for non-manifold and hybrid volumetric surfaces, and further optimizing GPU kernels for large-scale datasets could make differentiable meshing faster, more robust, and easier to adopt across geometry processing, simulation, and machine learning workflows.
SGI Fellows: Haojun Qiu, Nhu Tran, Renan Bomtempo, Shree Singhi and Tiago Trindade Mentors: Sina Nabizadeh and Ishit Mehta SGI Volunteer: Sara Samy
Introduction
The field of Computational Fluid Dynamics (CFD) has long been a cornerstone of both stunning visual effects in movies and video games, and also a critical tool in modern engineering, for designing more efficient cars and aircrafts for example. At the heart of any CFD application there exists a solver that essentially predicts how a fluid moves in space at discrete time intervals. The dynamic behavior of a fluid is governed by a famous set of partial differential equations, called the Navier-Stokes equations, here presented in vector form:
where \(t\) is time, \(\mathbf{u}\) is the varying velocity vector field, \(\rho\) is the fluids density, \(p\) is the pressure field, \(\nu\) is the kinematic viscosity coefficient and \(\mathbf{f}\) represents any external body forces (e.g. gravity, electromagnetic, etc.). Let’s quickly break down what each term means in the first equation, which describes the conservation of momentum:
\(\dfrac{\partial \mathbf{u}}{\partial t}\) is the local acceleration, describing how the velocity of the fluid changes at a fixed point in space.
\((\mathbf{u} \cdot \nabla) \mathbf{u}\) is the advection (or convection) term. It describes how the fluid’s momentum is carried along by its own flow. This non-linear term is the source of most of the complexity and chaotic behavior in fluids, like turbulence.
\(\frac{1}{\rho}\nabla p\) is the pressure gradient. It’s the force that causes fluid to move from areas of high pressure to areas of low pressure.
\(\nu \nabla^{2} \mathbf{u}\) is the viscosity or diffusion term. It accounts for the frictional forces within the fluid that resist flow and tend to smooth out sharp velocity changes. For the “Gaussian Fluids” paper, this term is ignored (\(\nu=0\)) to model an idealized inviscid fluid.
The second equation, \(\nabla \cdot \mathbf{u} = 0\), is the incompressibility constraint. It mathematically states that the fluid is divergence-free, meaning it cannot be compressed or expanded.
The first step to numerically solving these equations on some spatial domain \(\Omega\) using classical solvers is to discretize this domain. To do that, two main approaches have dominated the field from its very beginning:
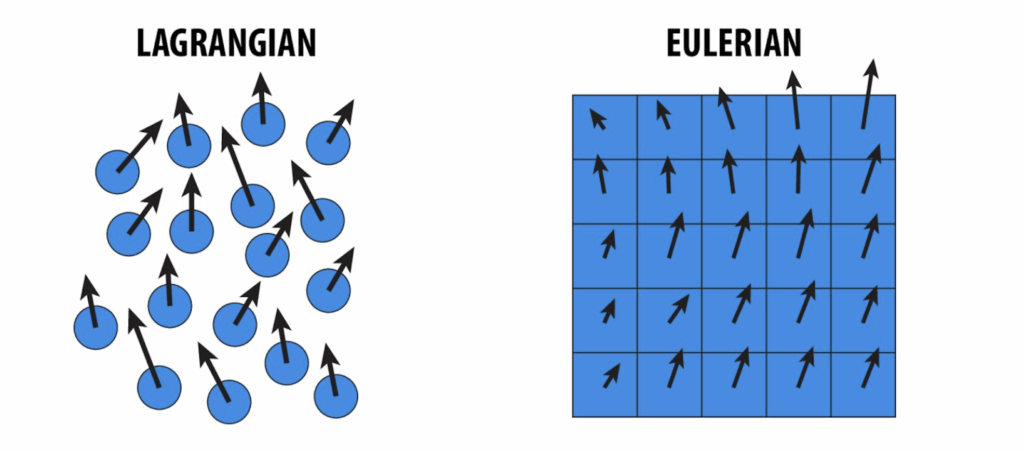
Eulerian methods: which use fixed grids that partition the spatial domain into a (un)structured collection of cells on which the solution is approximated. However, these methods often suffer from “numerical viscosity,” an artificial damping that smooths away fine details;
Lagrangian methods: which use particles to sample the solution at certain points in space and that move with the fluid flow. However, these methods can struggle with accuracy and capturing delicate solution structures.
The core problem has always been a trade-off. Achieving high detail with traditional solvers often requires a massive increase in memory and computational power, hitting the “curse of dimensionality”. Hybrid Lagrangian-Eulerian methods that try to combine the best of both worlds can introduce their own errors when transferring data between grids and particles. The quest has been for a representation that is expressive enough to capture the rich, chaotic nature of fluids without being computationally prohibitive.
A Novel Solution: Gaussian Spatial Representation
By now you have probably come across an emerging technology in the field of 3D rendering called 3D Gaussian Splatting (3DGS). It attempts to represent a 3D scene using, not traditional polygonal meshes or volumetric voxels, but in a manner similar to an artist using paint brush strokes to approximate a colored picture, Gaussian Splatting uses 3D gaussians to “paint” a 3D scene. These gaussians are nothing more than a ellipsoid with a color value and opacity associated.
Think of each Gaussian not as a solid, hard-edged ellipsoid, but as a soft, semi-transparent cloud (Fig.2). It’s most opaque and dense at its center and it smoothly fades to become more transparent as you move away from the center. The specific shape, size, and orientation of this “cloud” are controlled by its parameters. By blending thousands or even millions of these colored, transparent splats together, Gaussian Splatting can represent incredibly detailed and complex 3D scenes.
Fig.1 Example 3DGS of a Lego build (left) and a zoomed in view of the gaussians that make it up (right).
Drawing from this incredible effectiveness of using gaussians to encode complex geometry and lighting of 3D scenes, a new paper presented at SIGGRAPH 2025 titled “Gaussian Fluids: A Grid-Free Fluid Solver based on Gaussian Spatial Representation” by Jingrui Xing et al. introduces a fascinating new approach to computational domain representation for CFD applications.
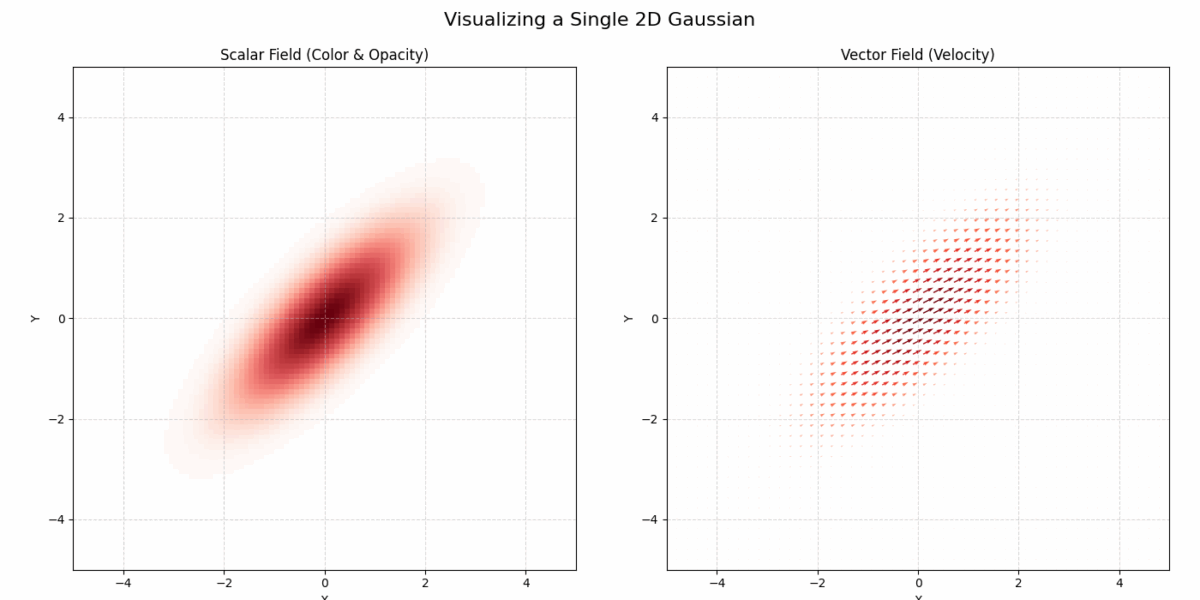
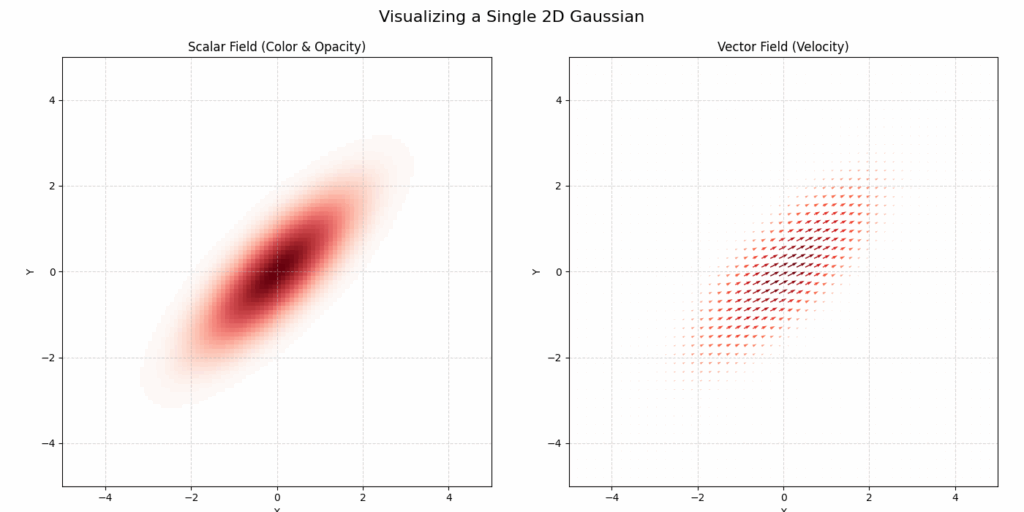
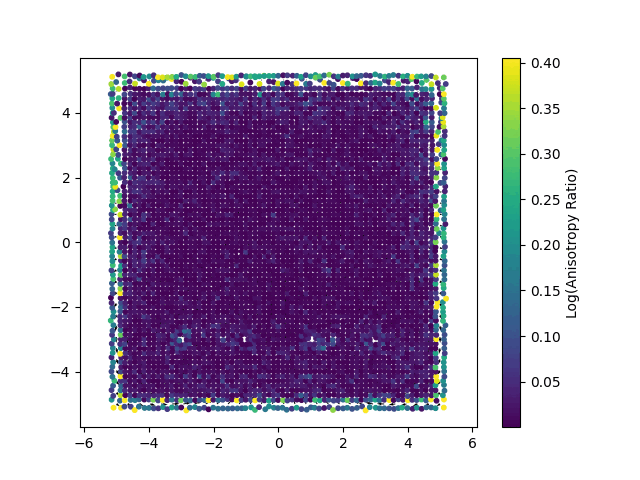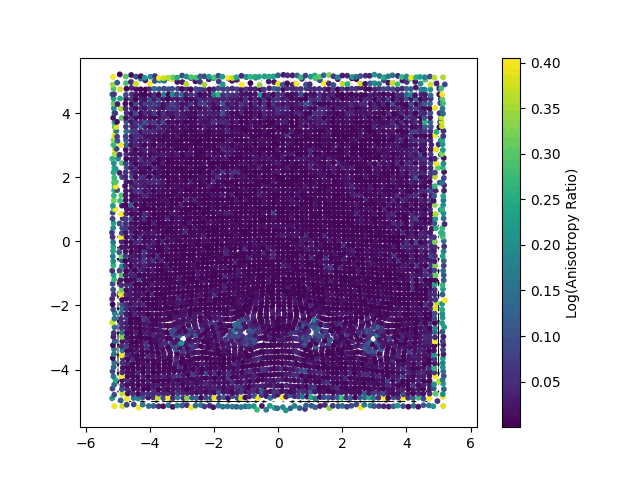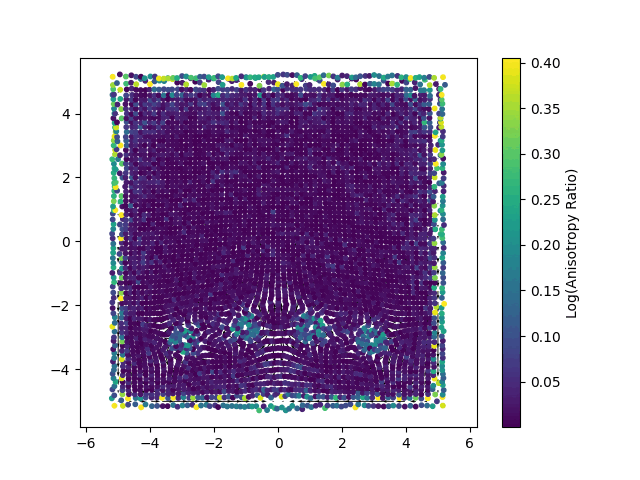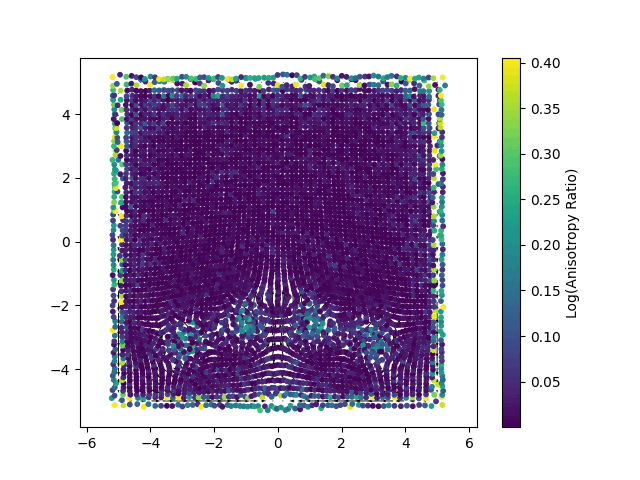
The new method, named Gaussian Spatial Representation (GSR), uses gaussians to essentially “paint” vector fields. While 3DGS encodes local color information into each gaussian, GSR encodes local vector fields. In this way each gaussian stores a vector that defines a local direction of the velocity field, where the magnitude of the vectors is greater closer the gaussian’s center, and quickly gets smaller when moving farther from it. In Fig.2 we can see an example of 2D gaussian viewed with color data (left), as well as with a vector field (right).
Fig.2 Example plot of a 2D Gaussian with scalar data (left) and vector data (right)
By splatting a lot of these gaussians and adding the vectors we can then define a continuously differentiable vector field around a given domain, which allows us to solve the complex Navier-Stokes equations not through traditional discretization, but as a physics-based optimization problem at each time step. A custom loss function ensures the simulation adheres to physical laws like incompressibility (zero-divergence) and, crucially, preserves the swirling motion (vorticity) that gives fluids their character.
Each point represents a Gaussian splat, with its color mapped to the logarithm of its anisotropy ratio. This visualization highlights how individual Gaussians are stretched or compressed in different regions of the domain.
Enforcing Physics Through Optimization: The Loss Functions
The core of the “Gaussian Fluids” method is its departure from traditional time-stepping schemes. Instead of discretizing the Navier-Stokes equations directly, the authors reframe the temporal evolution of the fluid as an optimization problem. At each time step, the solver seeks to find the set of Gaussian parameters that best satisfies the governing physical laws. This is achieved by minimizing a composite loss function, which is a weighted sum of several terms, each designed to enforce a specific physical principle or ensure numerical stability.
Two of the main loss terms are:
Vorticity Loss (\(L_{vor}\)): For a two dimensional ideal (inviscid) fluid, vorticity, defined as the curl of the velocity field (\(\omega=\nabla \times u\)), is a conserved quantity that is transported with the flow. This loss function is designed to uphold this principle. It quantifies the error between the vorticity of the current velocity field and the target vorticity field, which has been advected from the previous time step. By minimizing this term, the solver actively preserves the rotational and swirling structures within the fluid. This is critical for preventing the numerical dissipation (an artificial smoothing of details) that often plagues grid-based methods and for capturing the fine, filament-like features of turbulent flows.
Divergence Loss (\(L_{div}\)): This term enforces the incompressibility constraint, \(\nabla \cdot u=0\). From a physical standpoint, this condition ensures that the fluid’s density remains constant; it cannot be locally created, destroyed, or compressed. The loss function achieves this by evaluating the divergence of the Gaussian-represented velocity field at numerous sample points and penalizing any non-zero values. Minimizing this term is essential for ensuring the conservation of mass and producing realistic fluid motion.
Beyond these two, to function as a practical solver, the system must also handle interactions with boundaries and maintain stability over long simulations. The following loss terms address these requirements:
Boundary Losses (\(L_{b1}\), \(L_{b2}\)): The behavior of a fluid is critically dependent on its interaction with solid boundaries. These loss terms enforce such conditions. By sampling points on the surfaces of geometries within the scene, the loss function penalizes any fluid velocity that violates the specified boundary conditions. This can include “no-slip” conditions (where the fluid velocity matches the surface velocity, typically zero) or “free-slip” conditions (where the fluid can move tangentially to the surface but not penetrate it). This sampling-based strategy provides an elegant way to handle complex geometries without the need for intricate grid-cutting or meshing procedures.
Regularization Losses (\(L_{pos}\), \(L_{aniso}\), \(L_{vol}\)): These terms are included to ensure the numerical stability and well-posedness of the optimization problem.
The Position Penalty (\(L_{pos}\)) constrains the centers of the Gaussians, preventing them from deviating excessively from the positions predicted by the initial advection step. This regularizes the optimization process, improves temporal coherence, and helps prevent particle clustering.
The Anisotropy (\(L_{aniso}\)) and Volume (\(L_{vol}\)) losses act as geometric constraints on the Gaussian basis functions themselves. They penalize Gaussians that become overly elongated, stretched, or distorted. This is crucial for maintaining a high-quality spatial representation and preventing the numerical instabilities that could arise from ill-conditioned Gaussian kernels.
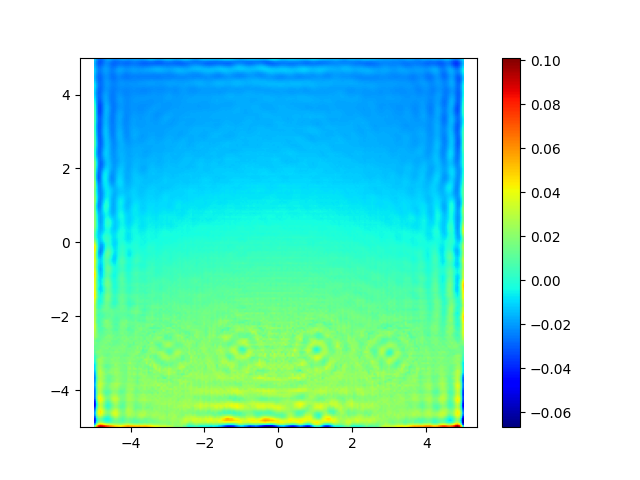
However, when formulating a fluid simulation as a Physics-Based optimization problem, one challenge that soon becomes apparent is that choosing good loss functions can be really tricky. The reliance on “soft constraints”, such as the divergence loss function, in the optimization process means that small errors can accumulate over time. Also, the handling of complex domains with holes (non-simply connected domains) is also a big challenge. When running the Leapfrog simulation we can see that the divergence of the solution, although relatively small, isn’t as close to zero as it should be (ideally it should be exactly zero).
This “Leapfrog” simulation highlights the challenge of “soft constraints.” The “Divergence” plot (bottom-left) shows the small, non-zero errors that can accumulate, while the “Vorticity” plot (bottom-right) shows the swirling structures the solver aims to preserve.
Divergence-free Gaussian Representation
Now we want to extend on this paper a bit. Let’s focus on the 2D case for now. The problem of regularizing divergence is that the velocity vector field won’t be exactly divergence free. I can perhaps help this with an extra step every iteration. Define \(\mathbf{J} \in \mathbb{R}^{2 \times 2}\) as a rotation matrix
This potential function can be constructed with the same gaussian mixture by carrying a \(\phi_{i} \in \mathbb{R}\) at every gaussian, and thus a continuous function having full support
similarly we can replace \(G_i(\mathbf{x})\) with the clamped gaussians \(\tilde{G}_i(\mathbf{x})\) for efficiency. Now we can construct a vector field that is unconditionally divergence-free
and we use the similar approach of Monte Carlo way of sampling \(\mathbf{x}\) uniformly in space.
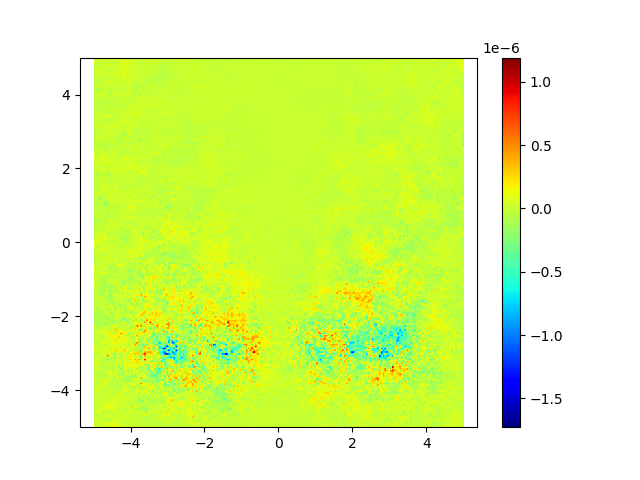
Doing this, we managed to achieve a divergence much closer to zero, as shown in the image below.
Before (left) and after (right)
References
Jingrui Xing, Bin Wang, Mengyu Chu, and Baoquan Chen. 2025. Gaussian Fluids: A Grid-Free Fluid Solver based on Gaussian Spatial Representation. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (SIGGRAPH Conference Papers ’25). Association for Computing Machinery, New York, NY, USA, Article 9, 1–11. https://doi.org/10.1145/3721238.3730620
One of the biggest bottlenecks in the modern model training pipelines for neuroimaging is diverse, well-labeled data. Real clinical MRI scans that could have been used, are under constraints of privacy, scarce annotations, and chaotic protocols. Because open-source MRI data comes from many scanners with different setups, the data varies a lot. This variation causes domain shifts and makes generalization much harder. All of these problems reinforce us to look for other solutions. Synthetic data directly handles these bottlenecks, once we have a robust pipeline that can generate unlimited, labelled data, we can expose models to the full range of scans (contrasts, noise levels, artifacts, orientations). With synthetic data, we are taking a step forward of solving the biggest bottlenecks in model training.
Nevertheless, another important thing is resolution. Most MRI scans are relatively low-resolution. At this scale, thin brain structures blur and different tissues can get mixed in a single voxel, so edges look soft and details disappear. This especially hurts areas like the cortical ribbon, ventricle borders, and small nuclei.
When models are trained only on these blurry data, they learn what they see: oversmoothed segmentations and weak boundary localization. Even with strong architectures and losses, you can’t recover details that simply don’t exist in the initial data that was fed to the model.
We are tackling this problem by generating higher-resolution synthetic data from clean geometric surfaces. Training with these high-resolution, label-accurate volumes gives models a much clearer understanding of what boundaries look like.
From MRI images to Meshes
The generation of synthetic data begins by using an already available brain MRI scan and replicating it into a collection of MRI data such that all the files in this collection represent the same MRI scan. However, each file uses a different set of contrasts to represent different regions of the brain. This ensures that our data collection is representative of the different models of MRI scanning devices available as each device can use a specific set of contrasts different from the ones used by other devices. Furthermore, we can make the orientation of the brain random to allow the data to mimic the randomness of how a person may position their head inside the MRI device. This process can be done easily using the already implemented python tool SynthSeg.
Using SynthSeg
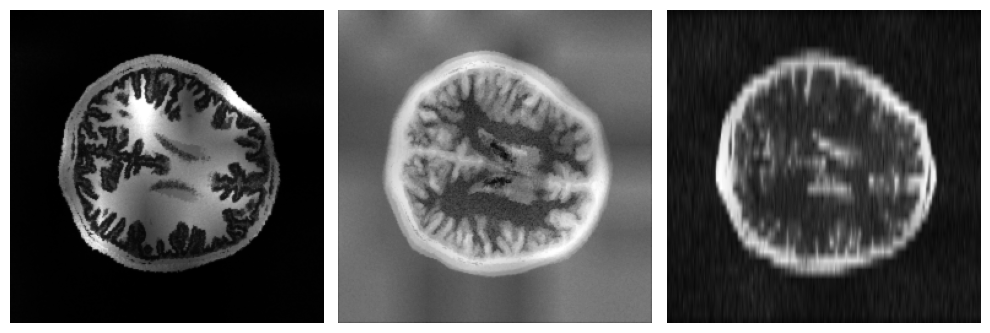
By running the SynthSeg Brain Generator using an available MRI scan, we can get random synthesized MRI data. For illustration, we can generate 3 samples that have different contrasts but the same orientation by setting the number of channels to 3. Here is a cross section of the output of these samples.
The output of the Brain Generator for each instance are two files: an image file and a label file. The image file is an MRI data file that contains all of the scan’s details. On the other hand, the label file is a file that only indicates the boundaries of different structures indicated in the image file.
Mesh Generation
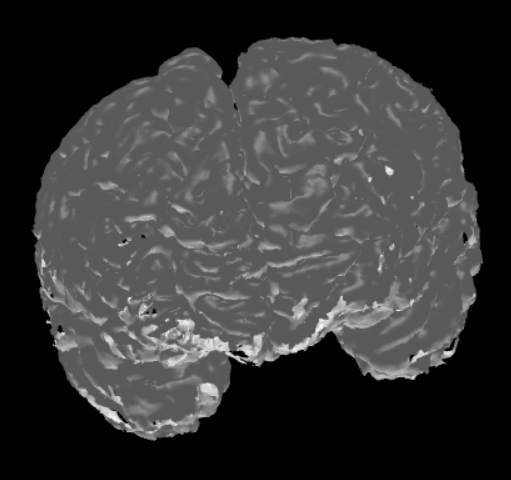
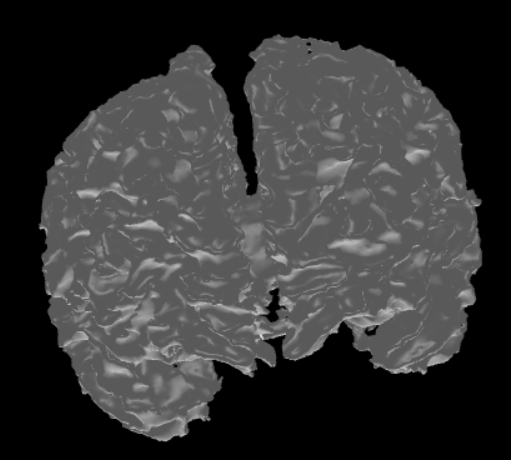
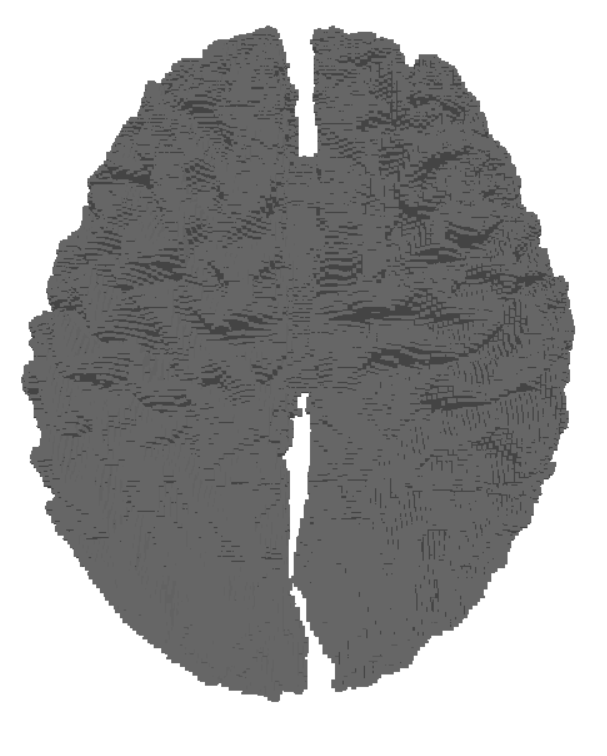
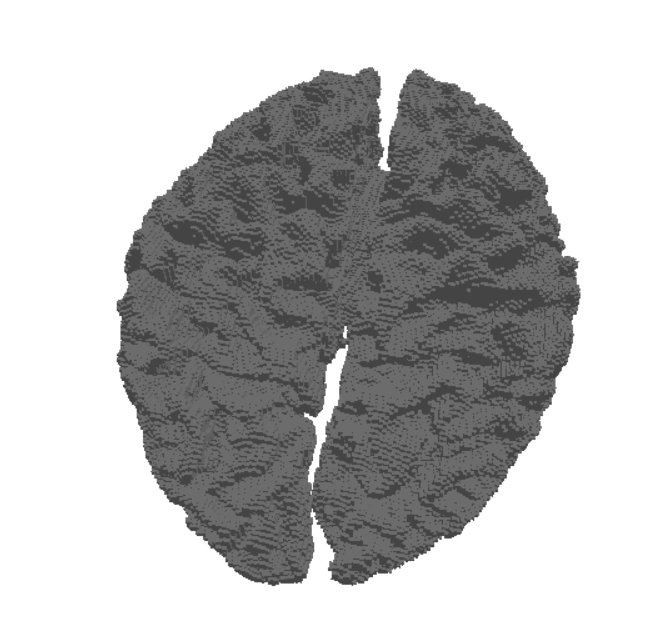
The label files can be useful as they only contain data describing the boundaries of each different region in the MRI data. This makes them more suitable for brain surface mesh generation. Using the SimNIBS package, different meshes can be generated via a label file. Each mesh represents a different region as dictated by the label file. After that, these meshes can be combined together to get a full mesh of the surface of the brain. Here are two meshes generated from the same label file.
From Meshes to MRI Data
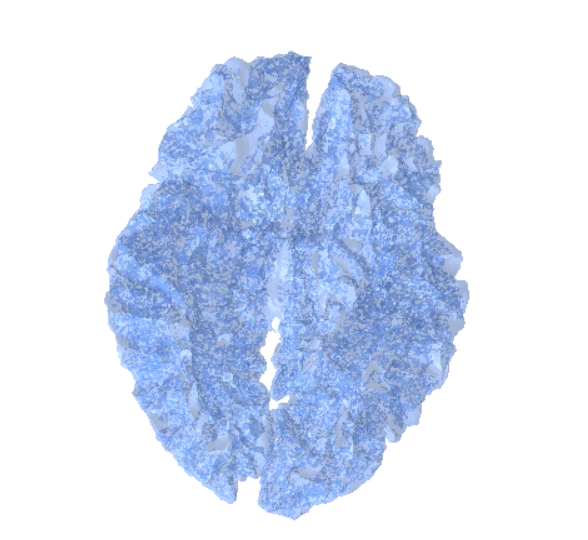
Once the MRI scans are transformed into meshes, the next step is to convert these geometric representations back into volumetric data. This process, called voxelization, allows us to represent the mesh on a regular 3D grid (voxels), which closely resembles the structure of MRI images.
Voxelization Process
Voxelization works by sampling the 3D mesh into a uniform grid, where each voxel stores whether it lies inside or outside the mesh surface. This results in a binary (or occupancy) grid that can later be enriched with additional attributes such as intensity or material properties.
Input: A mesh (constructed from MRI segmentation or surface extraction).
Output: A voxel grid representing the same anatomical structure.
Resolution and Grid Density
The quality of the voxelized data is heavily dependent on the resolution of the grid:
Low-resolution grids are computationally cheaper but may lose fine structural details.
High-resolution grids capture detailed geometry, making them particularly valuable for training machine learning models that require precise anatomical features.
Bridging Mesh and MRI Data
By voxelizing the meshes at higher resolutions than the original MRI scans, we can synthesize volumetric data that goes beyond the limitations of the original acquisition device. This synthetic MRI-like data can then be fed into training pipelines, augmenting the available dataset with enhanced spatial fidelity.
Conclusion
In conclusion, this pipeline can produce high resolution synthetic brain MRI data that can be used for various purposes. The results obtained from this process are representative as the contrasts of the produced MRI data are randomized to mimic the different types of MRI machines. Due to this, the pipeline has the potential to sustain large amounts of data suitable for the training of various models.
Written By
Youssef Ayman
Ualibyek Nurgulan
Daryna Hrybchuk
Special thanks to Dr. Karthik Gopinath for guiding us through this project!