SGI Fellows: Amber Bajaj, Renan Bomtempo, Tiago Trindade, and Tinsae Tadesse
Project Mentors: Sainan Liu, Ilke Demir and Alexey Soupikov
Volunteer Assistant: Vivien van Veldhuizen
Introduction
What is Gaussian Splatting?
3D Gaussian Splatting (3DGS) is a new technique for scene reconstruction and rendering. Introduced in 2023 (Kerbl et al., 2023), it sits in the same family of methods as Neural Radiance Fields (NeRFs) and point clouds, but introduces key innovations that make it both faster and more visually compelling.
To better understand where Gaussian Splatting fits in, let’s take a quick look at how traditional 3D rendering works. For decades, the standard approach to building 3D scenes has relied on mesh modelling — a representation built from vertices, edges, and faces that form geometric surfaces. These meshes are incredibly flexible and are used in everything from video games to 3D printing. However, mesh-based pipelines can be computationally intensive to render and are not ideal for reconstructing scenes directly from real-world imagery, especially when the geometry is complex or partially occluded.
This is where Gaussian Splatting comes in. Instead of relying on rigid mesh geometry, it represents scenes using a cloud of 3D Gaussians — small, volumetric blobs that each carry position, color, opacity, and orientation. These Gaussians are optimized directly from multiple 2D images and then splatted (projected) onto the image plane during rendering. The result is a smooth, continuous representation that can be rendered extremely fast and often looks more natural than mesh reconstructions. It’s particularly well-suited for real-time applications, free-viewpoint rendering, and artistic manipulation, which makes it a perfect match for style transfer, as we’ll see next.
What is Style Transfer?
Style transfer is a technique in computer vision and graphics that allows us to reimagine a given image (or in our case, a 3D scene) by applying the visual characteristics of another image, known as the style reference. In its most familiar form, style transfer is used to turn photos into “paintings” in the style of artists like Van Gogh or Picasso, as seen in Figure 1. This is typically done by separating the content and style components of an image using deep neural networks, and then recombining them into a new, stylized output.
Traditionally, style transfer has been limited to 2D images, where convolutional neural networks (CNNs) learn to encode texture, color, and brushstroke patterns. But extending this to 3D representations — especially ones that support free-viewpoint rendering — has remained a challenge. How do you preserve spatial consistency, depth, and lighting, while also injecting artistic style?
This is exactly the challenge we’re exploring in our project: applying style transfer to 3D scenes represented with Gaussian Splatting. Unlike meshes or voxels, Gaussians are inherently fuzzy, continuous, and rich in appearance attributes, making them a surprisingly flexible canvas for artistic manipulation. By modifying their colors, densities, or even shapes based on style references, we aim for new forms of stylized 3D content — imagine dreamy impressionist cityscapes or comic-book-like architectural walkthroughs. While achieving consistent and efficient rendering in all cases remains an open challenge, Gaussian Splatting offers a promising foundation for exploring artistic control in 3D.
We present a brief comparison of StyleGaussian and ABC-GS baselines, aiming to extend to style transfer for dynamic patterns, 4D scenes, and localized regions of 3DGS.
Style Gaussian Method
The StyleGaussian pipeline (Liu et al., 2024) achieves stylized rendering of Gaussians with real-time rendering and multi-view consistency through three key steps for style transfer: embedding, transfer, and decoding.
Step 1: Feature Embedding
Given a Gaussian Splat and camera positions, the first stage of stylization is embedding deep visual features into the Gaussians. To do this, StyleGaussian uses VGG, a classical CNN architecture trained for image classification. Specifically, features are extracted from the ReLU3_1 layer, which captures mid-level textures like edges and contours that are useful for stylization. These are called VGG features, and they act like high-level visual descriptors of the content of an image. However, VGG features are high-dimensional (256 channels or more), and trying to render them directly through Gaussian Splatting might overwhelm the GPU.
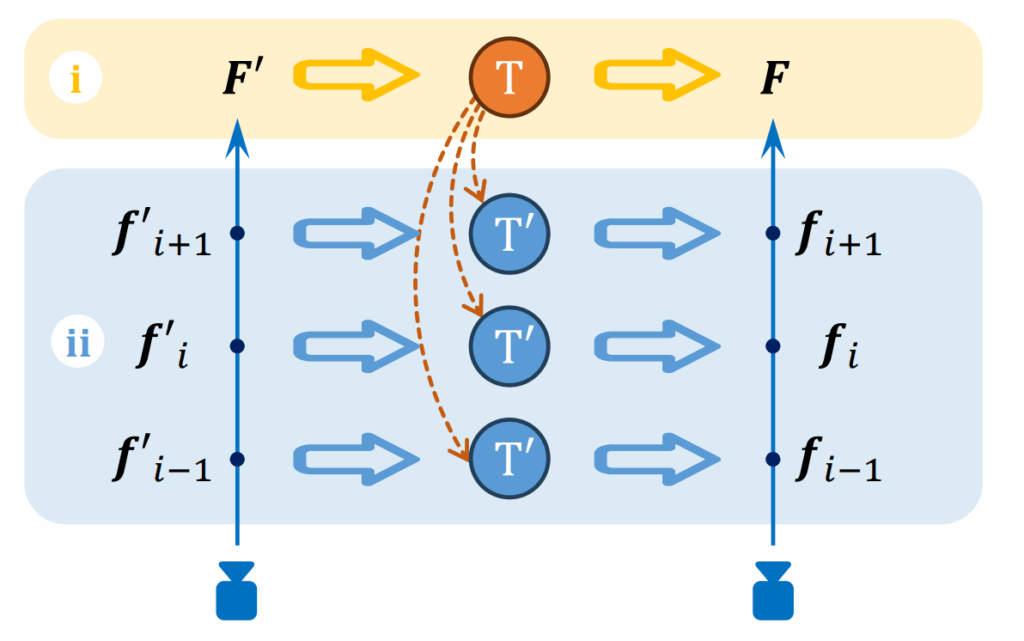
To solve this, StyleGaussian uses a clever two-step trick illustrated in Figure 2. Instead of rendering all 256 dimensions at once, the program first renders a compressed 32-dimensional feature representation, shown as F’ in the diagram. Then, it applies an affine transformation T to map those low-dimensional features back up to full VGG features F. This transformation can either be done at the level of pixels (i) or at the level of individual Gaussians (ii) — in either case, we recover high-quality feature embeddings for each Gaussian using much less memory.
During training, the system aims to minimize the difference between predicted and true VGG features, so that each Gaussian carries a compact and style-aware feature representation, ready for stylization in the next step.
Step 2: Style Transfer
With VGG features embedded, the next step is to apply the style reference. This is done using a fast, training-free method called AdaIN (Adaptive Instance Normalization). AdaIN works by shifting the mean and variance of the feature vectors for each Gaussian so that they match those of the reference image, “repainting” the features without changing their structure. Since this step is training-free, StyleGaussian can apply any new style in real time.

Step 3: RGB Decoding
After the style is applied, each Gaussian now carries a modified feature vector — a set of abstract values the neural network uses to describe patterns like brightness, curvature, textures, etc. To render the image, this feature vector needs to be converted into RGB colors for each Gaussian. StyleGaussian does this via a 3D CNN that operates across neighboring Gaussians. This network is trained using a small subset of the style reference images. By comparing a rendered view of the style-transfer to the reference, the network learns how to color the entire scene in a way that reflects the chosen artistic style.
ABC-GS Method
While StyleGaussian offers impressive real-time stylization using feature embeddings and AdaIN, it has a major limitation: it treats the entire scene as a single unit. That means the style is applied uniformly across the whole 3D reconstruction, with no understanding of different objects or regions within the scene.
This is where ABC-GS (Alignment-Based Controllable Style Transfer for 3D Gaussian Splatting) brings something new to the table.
Rather than applying style globally, ABC-GS (Liu et al., 2025) introduces controllability and region-specific styling, enabling three distinct modes of operation:
- Single-image style transfer: Apply the visual style of a single image uniformly across the 3D scene, similar to traditional style transfer.
- Compositional style transfer: Blend multiple style images, each assigned to a different region of the scene. These regions are defined by manual or automatic masks on the content images (e.g., using SAM or custom annotation). For example, one style image can be applied to the sky, another to buildings, and a third to the ground — each with independent control.
- Semantic-aware style transfer: Use a single style image that contains multiple internal styles or textures. You extract distinct regions from this style image (e.g., clouds, grass, brushstrokes) and assign them to matching parts of the scene (e.g., sky, ground) via semantic masks of the content. These masks can be generated automatically (with SAM) or refined manually. This allows for highly detailed region-to-region alignment even within one image.

The Two-Stage Stylization Pipeline
ABC-GS achieves stylization using a two-stage pipeline:
Stage 1: Controllable Matching Stage (used in modes 2 and 3 only)
In compositional and semantic-aware modes, this stage prepares the scene for region-based style transfer. It includes:
- Mask projection: Content and style masks are projected onto the 3D Gaussians.
- Style isolation: Each region of the style image is isolated to avoid texture leakage.
- Color matching: A linear color transform aligns the base colors of each content region with its assigned style region.
This stage is not used in the single-image mode, since the entire scene is styled uniformly without regional separation.
Stage 2: Stylization Stage (used in all modes)
In all three modes, the scene undergoes optimization using the FAST loss (Feature Alignment Style Transfer). This loss improves upon older methods like NNFM by aligning entire distributions of features between the style image and the rendered scene. It captures global patterns such as brushstroke directions, color palette balance, and texture consistency – even in single-image style transfer, FAST consistently yields more coherent and faithful results.
To preserve geometry and content, the stylization is further regularized with:
- Content loss: Retains original image features.
- Depth loss: Maintains 3D structure.
- Regularization terms: Prevent artifacts like over-smoothed or needle-like Gaussians.
Together, these stages make ABC-GS uniquely capable of delivering stylized 3D scenes that are both artistically expressive and structurally accurate — with fine-grained control over what gets stylized and how.
Visual & Quantitative Comparison
Figure 5 illustrates style transfer applied to a truck composed of approximately 300k Gaussians by StyleGaussian (left) and ABC-GS (right). In choosing simple patterns like a checkerboard or curved lines, we hope to highlight how each method handles the key challenges of 3D style transfer, such as alignment with underlying geometry, multi-view consistency, and accurate pattern representation.
To evaluate these differences from a quantitative angle, Fréchet Inception Distance (FID) and Learned Perceptual Image Patch Similarity (LPIPS) metrics were used.
FID measures the distance between the feature distributions of two images sets, with lower scores indicating greater similarity. This metric is often used in generative adversarial network (GAN) and neural style transfer research to assess how well generated images match a target domain. Meanwhile, LPIPS measures perceptual similarity between image pairs by comparing deep features from a pre-trained network, with lower scores indicating better content preservation.
For our purposes, FID measures style fidelity (how well stylized images match the style reference), with scores generally between 0 and 200, and lower scores indicating strong style similarity. LPIPS measures geometry and content preservation (how well the original scene structure is retained) within a range [0, 1], with lower scores indicating better structural preservation.

There is a clear visual improvement in the geometric alignment of patterns in the ABC-GS style transfer, where patterns adhere more cleanly with the object boundaries. In contrast, StyleGaussian shows a more diffuse application, with some color-bleeding and areas with high pattern variance (e.g., the wooden panels on the truck). In terms of LPIPS and FID scores, ABC-GS generally outperforms StyleGaussian, but tends to apply a less stylistically-accurate transfer with regular patterns (i) compared to more “abstract” ones (iii).
This difference in performance may stem from how StyleGaussian and ABC-GS handle feature alignment and geometry preservation. StyleGaussian applies a zero-shot AdaIN shift to all Gaussians, matching only the mean and variance of features; since higher-order structure is ignored, patterns can drift onto the wrong parts of the geometry. In contrast, ABC-GS optimizes the scene via FAST loss, computing a transformation that aligns the entire feature distribution of the rendered scene to that of the style. Meanwhile, content loss keeps the scene recognizable, depth loss maintains 3D geometry, and Gaussian regularization prevents distortions, resulting in better LPIPS and FID scores overall. However, in a case like (ii) where there is a lot of white background, ABC-GS’s competing content, depth, and regularization losses prevent large areas to be overwritten with pure white. Instead, it will try to keep more of the original scene’s detail and contrast, especially around geometry edges, which causes a deviation from the style reference and higher FID score. This interplay between geometry and style preservation is a key tradeoff in style transfer.
Although FID and LPIPS metrics are well-established in 2D image synthesis and style transfer, it is important to recognize potential limitations of applying them directly to 3D style transfer. These metrics operate on individual rendered views, without considering multi-view consistency, depth alignment, or temporal coherence. Future works should aim to better understand these benchmarks for 3D scenes.
Extensions & Experiments
Localized Style Transfer: Unsupervised Structural Decomposition of a LEGO Bulldozer via Gaussian Splat Clustering
We explore a novel technique for structural decomposition of complex 3D objects using the latent feature space of Gaussian Splatting. Rather than relying on pre-defined semantic labels or handcrafted segmentation heuristics, we directly use the parameters of a trained Gaussian Splat model as a feature embedding for clustering.
Motivation
The aim was twofold:
- Discovery – to see whether clustering Gaussians reveals structural groupings that are not immediately obvious from the visual appearance.
- Applicability – to explore whether these groupings could be useful for style transfer workflows, where distinct regions of a 3D object might be stylized differently based on structural identity.
Method
We trained a Gaussian Splatting model on a multi-view dataset of a LEGO bulldozer. The model was optimized to reconstruct the object from multiple angles, producing a 3D representation composed of thousands of oriented Gaussians.
From this representation, we extracted the following features per Gaussian:
- 3D Position
(x, y, z)(weighted for stronger spatial influence) - Color
(r, g, b) - Scale
(scale_0, scale_1, scale_2)(downweighted to avoid overemphasis) - Opacity (if available)
- Normal Vector
(nx, ny, nz)(surface orientation)
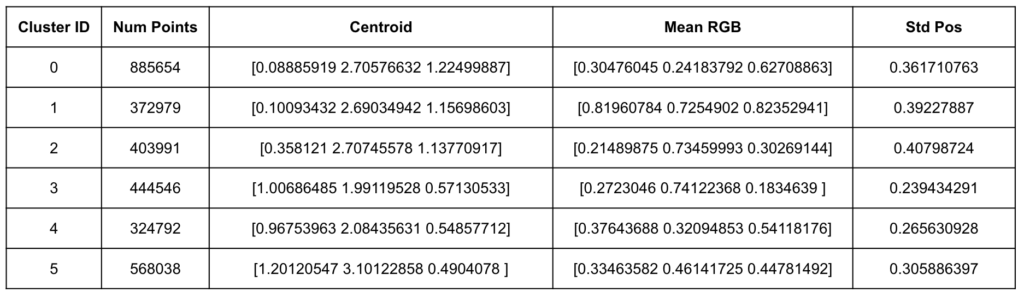
These features were concatenated into a single vector per Gaussian, weighted appropriately, and standardized. We applied KMeans clustering to segment the Gaussian set into six groups.
Results
The clustering revealed six distinct regions within the bulldozer’s Gaussian representation, each with unique spatial, chromatic, and geometric signatures.

Conclusion
The clustering was able to segment the bulldozer into regions that loosely align with intuitive sub-parts (e.g., the bucket, cabin, and rear assembly), but also revealed less obvious groupings—particularly in areas with subtle differences in surface orientation and scale that are hard to distinguish visually. This suggests that Gaussian-parameter-based clustering could serve as a powerful tool for automated part segmentation without requiring labeled data.
Future Work
- Cluster Refinement – Experiment with different weighting schemes and feature subsets (e.g., excluding normals or opacity) to evaluate their effect on segmentation granularity.
- Hierarchical Clustering – Apply multi-level clustering to capture both coarse and fine structural groupings.
- Style Transfer Applications – Use cluster assignments to drive localized style transformations, such as recoloring or geometric exaggeration, to test their value in content creation workflows.
- Cross-Object Comparison – Compare clustering patterns across different models to see if similar structural motifs emerge.
Dynamic Texture Style Transfer
Next, given StyleGaussian’s ability to apply new style references at runtime, a natural extension is style transfer of dynamic patterns. Below are some initial results of this approach, created by cycling through the frames of a gif or video in predetermined time intervals.
There is a key tradeoff between flexibility and quality: while zero-shot transfer enables dynamic patterns, the features are relatively muddled, making it difficult to project detailed media. Meanwhile, in the case of ABC-GS, this improved stylization is a result of optimization, which cannot occur at runtime as with StyleGaussian, making it difficult to render dynamic patterns.
Dynamic Scene Style Transfer
So far we’ve shown how incredibly powerful 3D Gaussian Splatting (3DGS) is for generating 3D static scene representations with remarkable detail and efficiency. The parallel to the dawn of photography is a compelling one: just as early cameras first captured the world on a static 2D canvas, 3DGS excels at creating photorealistic representations of real world scenes on a static 3D canvas. A logical next step is to leverage this technology to capture dynamic scenes.
Videos represent dynamic 2D scenes by capturing a series of static images that, when shown in rapid succession, let us perceive subtle changes as motion. In a similar fashion, one may attempt to capture dynamic 3D scenes as a sequence of static 3D scene representations. However, the curse of dimensionality plagues any naive approach to bring this idea to reality.
Lessons from Video Compression
In the digital age of motion picture, storing a video naively as a sequence of individual images (imitating a physical film strip) is possible but hugely inefficient. A digital image is nothing more than a 2D grid of small elements called pixels. In most image formats, each pixel usually stores about 3 bytes of color data, and a good quality Full HD image contains around 1920 x 1080 ≈ 2 million pixels. This amounts to around 6 million bytes (6 MB) of memory needed to store a single uncompressed Full HD image. Now, a reasonably good video should capture 1 second of a dynamic scene using 24 individual images (24 fps), which yields 144 MB of data to capture just a single second of uncompressed video (using uncompressed images). This means that a quick 30-second video would require a whopping 5 GB of memory.
So although possible, this naive approach to capturing dynamic 2D scenes quickly becomes impractical. To address this problem, researchers and engineers developed compression algorithms for both images and videos in an attempt to reduce memory requirements. The JPEG image format, for example, achieves an average of 10:1 compression ratio, shrinking a Full HD image to only 0.6 MB (600 KB) of storage. However, even if we store a 30-second video as a sequence of compressed JPEG frames, we would still be looking at a 500 MB video file.
The JPEG format compresses images by removing unnecessary and redundant information on the spatial domain, identifying patterns in different parts of the image. Following this same principle, video formats like MP4 identify patterns in the time domain and use them to construct a motion vector field to shift parts of the image from one frame to another. By storing only what changes, these video formats often achieve around 100:1 compression — depending on the contents of the scene — which takes our original 30-second 5 GB video to only 50 MB.
We will now see how this problem of scalability gets even worse when dealing with 3D Gaussian Splatting scenes.
The Curse of Dimensionality
Previously, we have discussed that while 2D grids are made up of pixels storing 3 bytes of color information, 3DGS Gaussians store position, orientation, scale, opacity, and color data. Thus, it is important to note that an image represents a scene from a single viewpoint, so its lighting information is static and can be easily stored using simple RGB colors. In contrast, since GS must represent a 3D scene from various viewpoints, we must have a way to store this dynamic lighting and change Gaussians’ colors depending on where the scene is viewed from. To achieve this, a technique called Spherical Harmonics is used to encode both color and lighting information for each Gaussian.
To store this information we need:
- 3 floats for position,
- 3 floats for scale,
- 4 floats for orientation (using quaternions),
- 1 float for opacity,
- 16 floats for color/lighting (using spherical harmonics*).
Using single-precision floats, that is 236 bytes per Gaussian. In a crude comparison, we can see that the building blocks of a 3DGS scene representation must store 78x more data than a pixel in a 2D image. While the next section shows that good 3DGS scenes require much fewer Gaussians than a good image requires pixels, moving to the 3rd dimension already poses a significant memory challenge.
For example, Figure 8 contains around 200.000 Gaussians, which amounts to about 23 MB of data for a single static scene.
If we were to follow the same naive idea for 2D videos and store a full static scene for each frame of a dynamic scene, we would need 24 static 3DGSs to represent 1 second of the dynamic scene (at 24 FPS), which would require 550 MB. A 30-second clip would then require a whopping 15 GB of storage. For more complex or detailed scenes, this problem only gets worse. And that’s just storage; generating and rendering all of this information would require a lot of computation and memory bandwidth, especially if we aim for real-time performance.
One notable approach to this problem was presented by Luiten et al. (2023), where the authors take a canonical set of Gaussians and keep intrinsic properties like color, size and opacity constant in time, storing only the position and orientation of Gaussians at each timestep. While less data is needed for each frame, this approach still scales linearly with frame count.
A Solution: Learn How the Scene Changes
So, instead of representing dynamic scenes as sequences of static 3DGS frames, a compelling research direction is to employ a strategy similar to video compression algorithms: focus on encoding how the scene changes between frames.
This is the idea behind 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering (Wu et al., 2024). Their solution comes in the form of a Gaussian Deformation Field Network, a compact neural network that implicitly learns the function that dictates motion for the entire scene. This improves scalability, as the memory footprint depends mainly on the network’s size rather than video length.
Instead of redundantly storing scene information, 4DGS establishes a single canonical set of 3D Gaussians, denoted by \( \mathscr{G} \), that serves as the master model for the scene’s geometry. From there, the Gaussian Deformation Field Network \( \mathscr{F}\) learns the temporal evolution of Gaussians. For each timestamp \(t\), the network predicts the deformation \(\Delta \mathscr{G}\) for the entire set of canonical Gaussians. The final state of the scene for that frame, \(\mathscr{G}’\), is then computed by applying the learned transformation:
$$
\mathscr{G}’ = \mathscr{F}(\mathscr{G},t) + \mathscr{G}
$$
The network’s encoder is designed with separate heads to predict the components of this transformation: a change in position (\(\Delta \mathscr {X}\)), orientation (\(\Delta r\)), and scale (\(\Delta s\)).
By encoding a scene as fixed geometry (the canonical Gaussian set) plus a learned function of its dynamics, 4DGS offers an efficient and compact model of the dynamic 3D world. Additionally, because the model is a true 4D representation, it enables rendering the dynamic scene from any novel viewpoint in real-time, thereby transforming a simple recording into a fully immersive and interactive experience.
The output is a canonical Gaussian Splatting scene stored as a .ply file together with a set of .pth files (the standard PyTorch model files) that encode the Gaussian Deformation Field Network. From there, the scene may be rendered from any viewpoint at any timestamp of the video.
To demonstrate, we use a scene from the HyperNerf dataset. Figure 9 compares the original video (left), the resulting trained-view 4DGS (center), and the resulting test-view 4DGS (right). The right video is rendered from a different viewpoint and is used to verify that the GS indeed generalized the scene geometry in 3D space.
The 4DGS pipeline
Before explaining the 4DGS pipeline, we must first understand its input. We aim to generate a 4D scene — that is a 3D scene that changes over time (+1D). This requires a set of videos that capture the same scene simultaneously. In synthetic datasets, researchers use multiple cameras (e.g., 27 cameras in the Panoptic dataset) to film from multiple viewpoints at the same time. However, in real world setups, this is impractical, and usually a stereo setup (i.e. 2 cameras) is more common, as in the HyperNerf dataset.
With the input defined, the pipeline can be split into 3 main steps:
- Initialization: Before anything can move, the model needs a 3D “puppet” to animate. The quality of this initial puppet depends heavily on the camera setup used to film the video.
- Case A: The ideal multi-camera setup
- Scenario: This applies to lab-grade datasets like the Panoptic Studio dataset, which uses a dome of many cameras (e.g., 27) all recording simultaneously.
- Process: The model looks at the images from all cameras at the very first moment in time (t=0). Because it has so many different viewpoints of the scene frozen in that instant, it can use Structure-from-Motion (SfM) to create a highly accurate and dense 3D point cloud.
- Result: This point cloud is turned into a high-fidelity canonical set of Gaussians that perfectly represents the scene at the start of the video. It’s a clean, sharp, and well-defined starting point.
- Case B: The Challenging real-world scenario
- Scenario: This applies to more common videos filmed with only one or two cameras, like those in the HyperNeRF dataset.
- Process: With too few viewpoints at any single moment, SfM needs the camera to move over time to build a 3D model. Therefore, the algorithm must analyze a collection of frames (e.g., 200 random frames) from the video.
- Result: The static background is reconstructed well, but the moving objects are represented by a more scattered, averaged point cloud. This initial canonical scene doesn’t perfectly match any single frame but instead captures the general space the object moved through. This makes the network’s job much harder.
- Case A: The ideal multi-camera setup
- Static Warm-up: With the initial puppet created, the model spends a “warm-up” period (the first 3,000 iterations in the paper’s experiments) optimizing it as if it were a static, unmoving scene. This step is crucial in both cases. For the multi-camera setup, it fine-tunes an already great model. For the single-camera setup, it’s even more important, as it helps the network pull the averaged points into a more coherent shape before it tries to learn any complex motion.
- Dynamic Training: Now for the main step, the model goes through the video frame by frame and trains the Gaussian Deformation Field Network.
- Pick a Frame: The training process selects a specific frame (a timestamp, t) from the video.
- Ask the Network: It feeds the canonical set of Gaussians \(\mathscr G\) and the timestamp \(t\) into the deformation network \(\mathscr F\).
- Predict the motion: The network predicts the necessary transformations \(\Delta \mathscr G\) for every single Gaussian to move them from their canonical starting position to where they should be at a timestamp t. This includes changes in position, orientation and scale.
- Apply the motion: The predicted transformations are applied to the canonical Gaussians to create a new set of deformed Gaussians \(\mathscr G’\) for that specific frame.
- Render the image: The model then renders the ‘splats’ the deformed Gaussians onto an image, creating a synthetic view of what the scene should look like.
- Compare with original and calculate error: The rendered image is then compared with the actual video frame from the dataset. The difference between the two is used as the loss, which is calculated as simply the L1 color loss. It basically says how different each pixel of the splatted image is from the original video frame.
- Backpropagation: This is the learning step, where the error is sent backward through the network so it can adjust the position, orientation, and scale of the Gaussians to better approximate the scene.
This loop repeats for different frames and different camera views until the network becomes so good at predicting the deformations that it can generate a photorealistic moving sequence from the single canonical set of Gaussians.
4D Stylization
Now that we understand how 4D Gaussian Splatting works, we present here an idea for integrating the StyleGaussian method into the 4DGS pipeline. Unfortunately we were not able to fully implement this idea due to time limitations, however we will explain how and why this idea should work.
The fact that the 4DGS pipeline works by generating a canonical static representation of the scene makes it suitable for integrating with StyleGaussian. We may simply run it on the canonical scene representation that was generated, and the deformation would then move the stylized gaussians to the right places.
One potential problem with this approach, however, is that the canonical scene generated with real-world scenes captured using a stereo camera setup may not correctly represent moving objects on the scene. Due to the lack of images for the initial frame (only 2) when using these datasets, the 4DGS method utilizes random frames from the whole video to obtain the canonical set of Gaussians, which ends up being an average of the scene. Thus, moving objects will not be correctly captured and if we apply a stylization on this averaged scene, it could potentially lead to a less stable or visually inconsistent application of the style on dynamic elements within the final rendered video.
Overall Conclusions & Future Directions
Given the time and resource constraints of our project, we have shown a visual and quantitative comparison of the preservation of pattern features during style transfer with Style Gaussian and ABC-GS. Additionally, using these baselines, we have experimented with some initial results for style transfer with dynamic patterns, proposed a method for combining StyleGaussian with 4DGS, and developed an effective GS clustering strategy that can be used for localized style applications.
Future research might expand on these experiments by:
- Exploring better validation metrics for GS scenes that account for 3D components like multi-view consistency
- Developing alternatives to random frames for generating canonical set of Gaussians from stereo camera scenes, which will prevent visually inconsistent stylization
- Further refining clustering techniques and developing metrics to evaluate the effectiveness of local stylization
- Applications of dynamic textures onto individual local GS components via clustering, building on the global transition effect explored previously. This direction could produce interesting “special effects” such as displaying optical illusions or giving a “fire effect” to a 3DGS scene
References
Gatys, L. A., Ecker, A. S., & Bethge, M. (2015, August 26). A neural algorithm of artistic style. arXiv.org. https://arxiv.org/abs/1508.06576
Kerbl, B., Kopanas, G., Leimkuehler, T., & Drettakis, G. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Transactions on Graphics, 42(4), 1–14. https://doi.org/10.1145/3592433
Liu, K., Zhan, F., Xu, M., Theobalt, C., Shao, L., & Lu, S. (2024, March 12). StyleGaussian: Instant 3D Style Transfer with Gaussian Splatting. arXiv.org. https://arxiv.org/abs/2403.07807
Liu, W., Liu, Z., Yang, X., Sha, M., & Li, Y. (2025, March 28). ABC-GS: Alignment-Based Controllable Style Transfer for 3D Gaussian splatting. arXiv.org. https://arxiv.org/abs/2503.22218
Luiten, J., Kopanas, G., Leibe, B., & Ramanan, D. (2023, August 18). Dynamic 3D Gaussians: Tracking by persistent dynamic view synthesis. arXiv.org. https://arxiv.org/abs/2308.09713
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., & Wang, X. (2023, October 12). 4D Gaussian Splatting for Real-Time Dynamic Scene rendering. arXiv.org. https://arxiv.org/abs/2310.08528