Introduction and Motivation
One of the biggest bottlenecks in the modern model training pipelines for neuroimaging is diverse, well-labeled data. Real clinical MRI scans that could have been used, are under constraints of privacy, scarce annotations, and chaotic protocols. Because open-source MRI data comes from many scanners with different setups, the data varies a lot. This variation causes domain shifts and makes generalization much harder. All of these problems reinforce us to look for other solutions. Synthetic data directly handles these bottlenecks, once we have a robust pipeline that can generate unlimited, labelled data, we can expose models to the full range of scans (contrasts, noise levels, artifacts, orientations). With synthetic data, we are taking a step forward of solving the biggest bottlenecks in model training.
Nevertheless, another important thing is resolution. Most MRI scans are relatively low-resolution. At this scale, thin brain structures blur and different tissues can get mixed in a single voxel, so edges look soft and details disappear. This especially hurts areas like the cortical ribbon, ventricle borders, and small nuclei.
When models are trained only on these blurry data, they learn what they see: oversmoothed segmentations and weak boundary localization. Even with strong architectures and losses, you can’t recover details that simply don’t exist in the initial data that was fed to the model.
We are tackling this problem by generating higher-resolution synthetic data from clean geometric surfaces. Training with these high-resolution, label-accurate volumes gives models a much clearer understanding of what boundaries look like.
From MRI images to Meshes
The generation of synthetic data begins by using an already available brain MRI scan and replicating it into a collection of MRI data such that all the files in this collection represent the same MRI scan. However, each file uses a different set of contrasts to represent different regions of the brain. This ensures that our data collection is representative of the different models of MRI scanning devices available as each device can use a specific set of contrasts different from the ones used by other devices. Furthermore, we can make the orientation of the brain random to allow the data to mimic the randomness of how a person may position their head inside the MRI device. This process can be done easily using the already implemented python tool SynthSeg.
Using SynthSeg
By running the SynthSeg Brain Generator using an available MRI scan, we can get random synthesized MRI data. For illustration, we can generate 3 samples that have different contrasts but the same orientation by setting the number of channels to 3. Here is a cross section of the output of these samples.
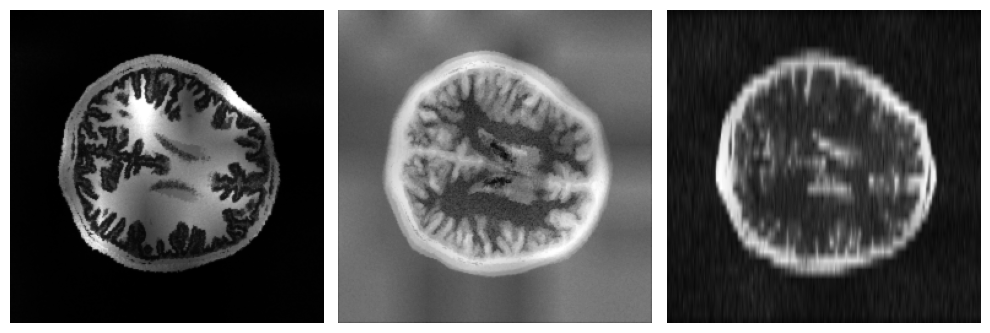
The output of the Brain Generator for each instance are two files: an image file and a label file. The image file is an MRI data file that contains all of the scan’s details. On the other hand, the label file is a file that only indicates the boundaries of different structures indicated in the image file.
Mesh Generation
The label files can be useful as they only contain data describing the boundaries of each different region in the MRI data. This makes them more suitable for brain surface mesh generation. Using the SimNIBS package, different meshes can be generated via a label file. Each mesh represents a different region as dictated by the label file. After that, these meshes can be combined together to get a full mesh of the surface of the brain. Here are two meshes generated from the same label file.
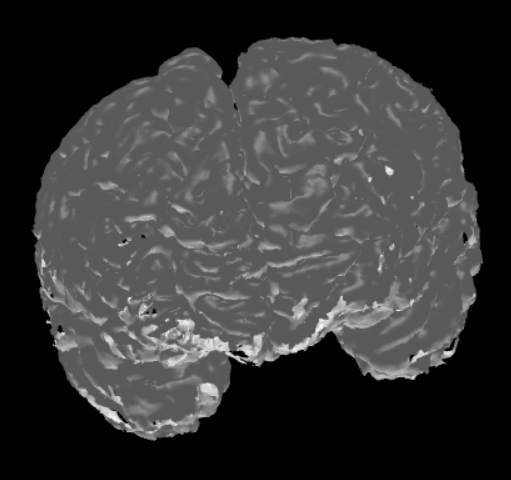
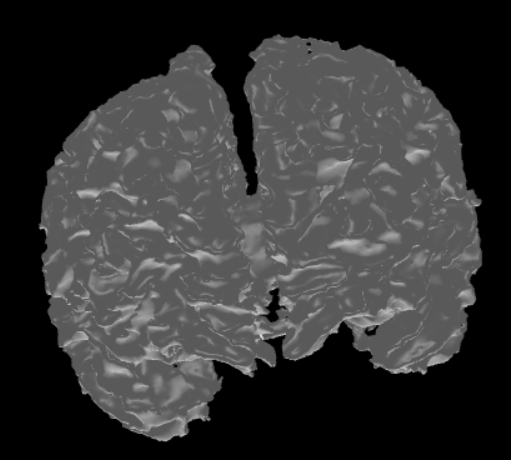
From Meshes to MRI Data
Once the MRI scans are transformed into meshes, the next step is to convert these geometric representations back into volumetric data. This process, called voxelization, allows us to represent the mesh on a regular 3D grid (voxels), which closely resembles the structure of MRI images.
Voxelization Process
Voxelization works by sampling the 3D mesh into a uniform grid, where each voxel stores whether it lies inside or outside the mesh surface. This results in a binary (or occupancy) grid that can later be enriched with additional attributes such as intensity or material properties.
Input: A mesh (constructed from MRI segmentation or surface extraction).
Output: A voxel grid representing the same anatomical structure.
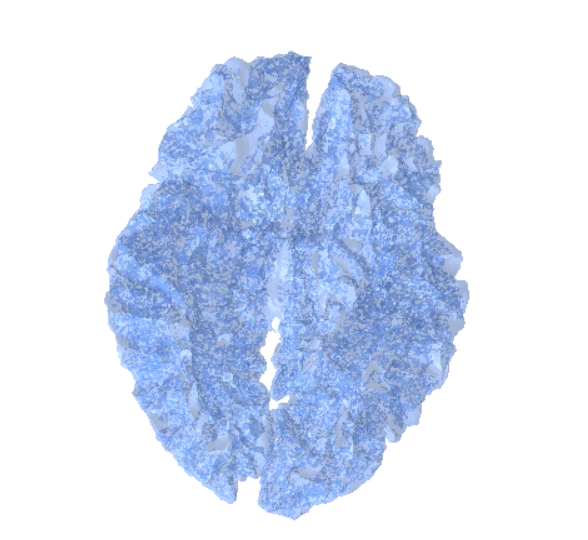
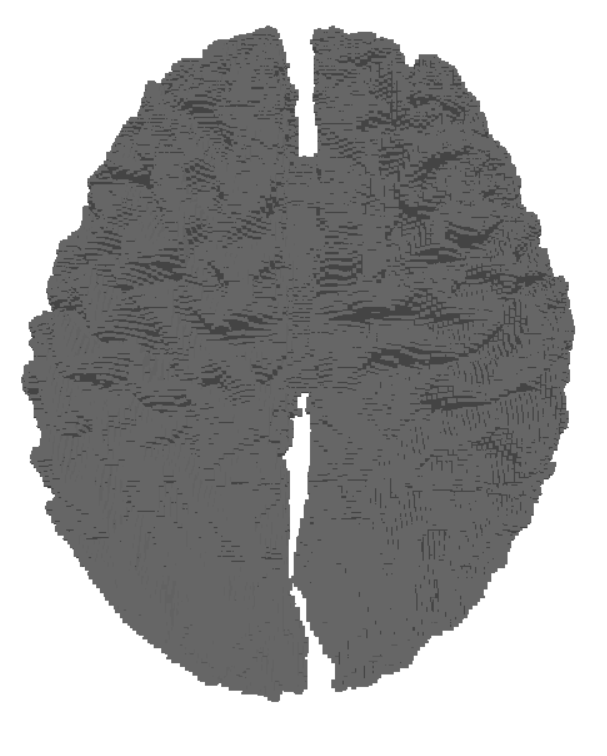
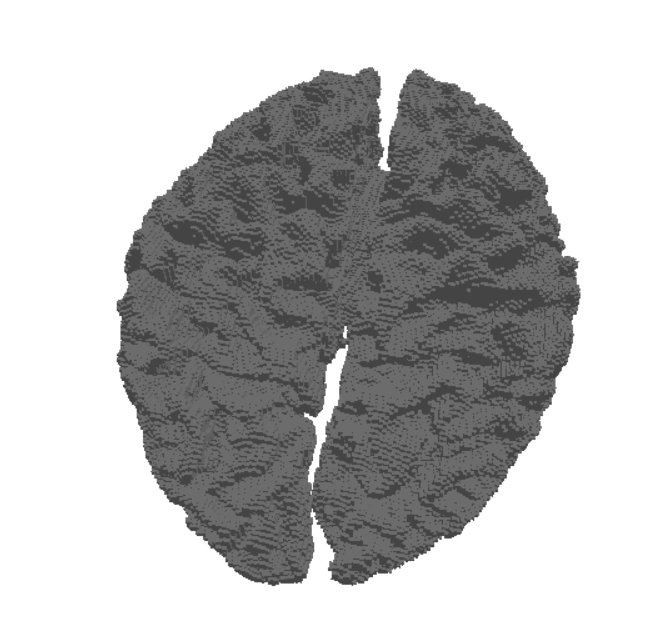
Resolution and Grid Density
The quality of the voxelized data is heavily dependent on the resolution of the grid:
- Low-resolution grids are computationally cheaper but may lose fine structural details.
- High-resolution grids capture detailed geometry, making them particularly valuable for training machine learning models that require precise anatomical features.

Bridging Mesh and MRI Data
By voxelizing the meshes at higher resolutions than the original MRI scans, we can synthesize volumetric data that goes beyond the limitations of the original acquisition device. This synthetic MRI-like data can then be fed into training pipelines, augmenting the available dataset with enhanced spatial fidelity.
Conclusion
In conclusion, this pipeline can produce high resolution synthetic brain MRI data that can be used for various purposes. The results obtained from this process are representative as the contrasts of the produced MRI data are randomized to mimic the different types of MRI machines. Due to this, the pipeline has the potential to sustain large amounts of data suitable for the training of various models.
Written By
- Youssef Ayman
- Ualibyek Nurgulan
- Daryna Hrybchuk
Special thanks to Dr. Karthik Gopinath for guiding us through this project!