By SGI Fellows Hector Chahuara, Anna Krokhine, and Elshadai Tegegn
During the fourth week of SGI, we continued our work with Professor Paul Kry on Revisiting Computational Caustics. See the “Flat Land Reflection” blog post for a summary of work during week 3, wherein we wrote a flatland program that simulates light reflecting off a surface.
While the flatland program that we wrote did a good job of visualizing the reflection from the source onto the target geometry, the initial code was quite inefficient. It looped over each individual light ray, calculating the reflected direction and intersection with the target one by one. In order to optimize the code, Professor Kry suggested that we try and vectorize the main functions in the program. Vectorizing code means eliminating loops and instead using operations on full vectors and matrices containing the necessary information. In the case of this program, this meant writing a function that simultaneously calculates the intersections of all the reflected rays with the target surface, and then combines them into the resulting image at once (rather than looping over each individual ray’s contribution).
The most challenging part of this task was creating a matrix containing all the reflected directions, rather than just calculating one for a given ray. The equation for the reflected direction from a given normal n is
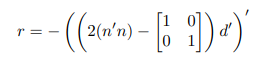
where d is the direction of the light ray from the source.
We needed to adapt this equation to input a 2xk matrix N containing k normals and get a 2xk matrix R. Because of the n’*n term, this is quadratic in each of the individual columns of N, making vectorization more difficult. One trick we used to resolve this was sparse matrices; that is, matrices with mostly zeros. The idea was that we could calculate and store all the resulting 2×2 matrices from each column in the same large sparse matrix, rather than calculating one at a time. The advantages of this approach is that the sparseness of the matrix makes it less expensive to store, and because other entries are zero, multiplication operations that act on each 2×2 block alone are easy to formulate.
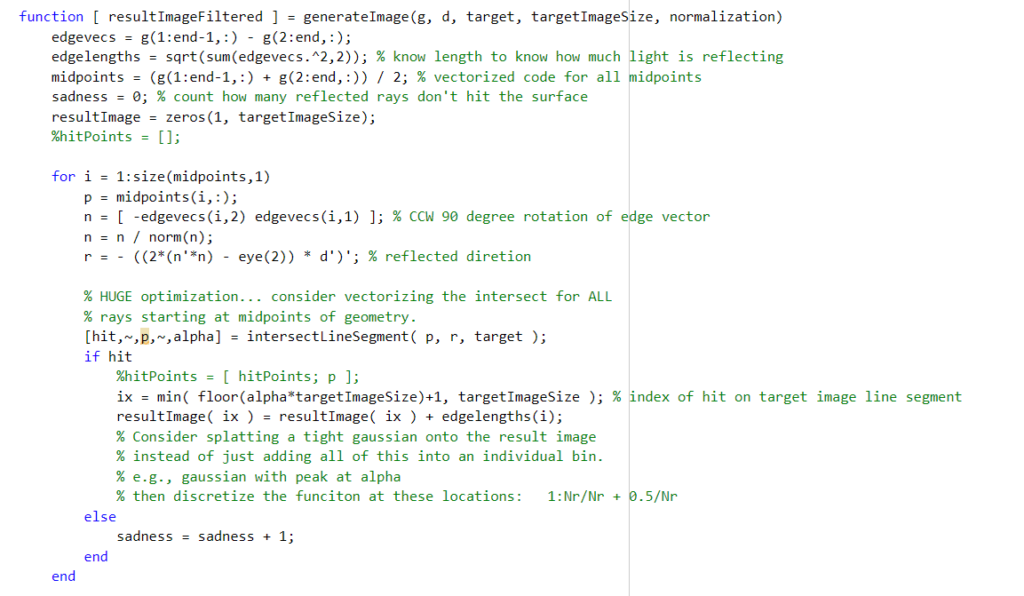
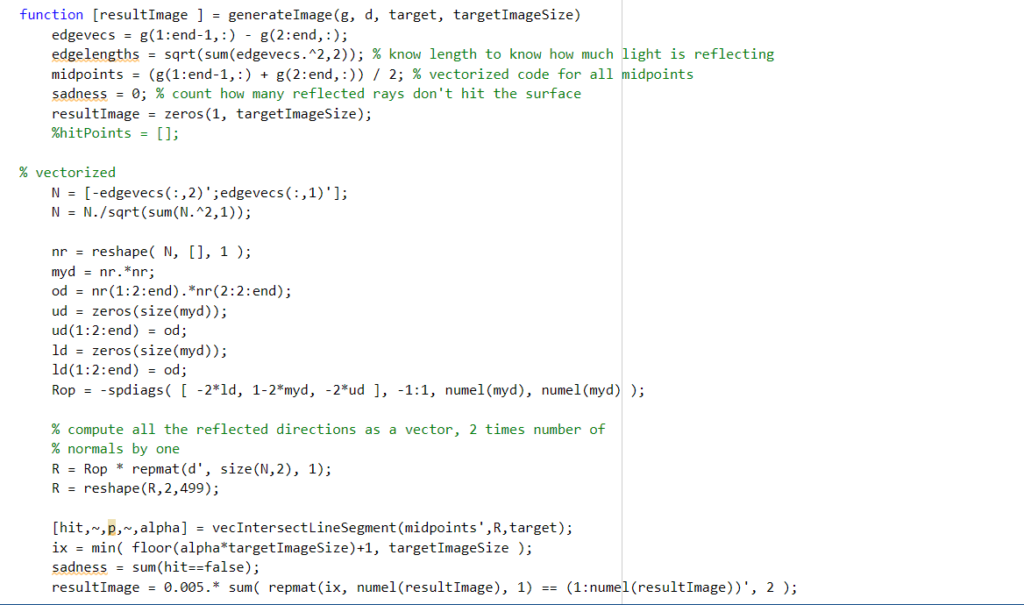
Overall, vectorizing the code was a very fun challenge and good learning opportunity. This project pushed us to apply vectorization to situations with involved and creative solutions.