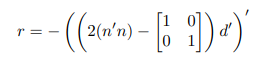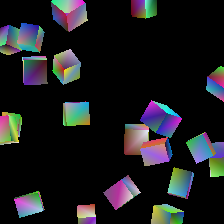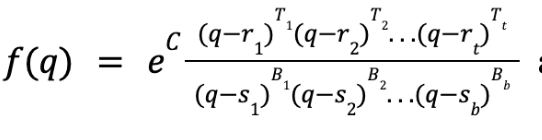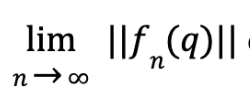During the last week of SGI, Tiago De Souza Fernandes, Miles Silberling-Cook, and I studied computing all pairs of geodesic distances on a manifold mentored by Nicholas Sharp, a former postdoc at the University of Toronto and a senior research scientist at NVIDIA. These distances are stored in a matrix A, with each row and column corresponding to a point on the manifold and each entry Ai,j representing the distance between the points i and j. This matrix is often very large and its memory usage grows quadratically with the addition of points–A manifold with 1,000 points of interest would need a matrix with 1,000,000 entries to store all geodesic distances.
The issue of memory use is accompanied by the issue of computation time. The most common algorithm for computing an all-pairs geodesics distance matrix consists of running the algorithm to compute single-source geodesic distances once for each point. To address these difficulties, we developed a method to estimate the all-pairs geodesics matrix using stochastic descent, taking advantage of the fact that the matrix is real and symmetric.
Every real symmetric matrix has real eigenvalues and real orthogonal eigenvectors. This means we can decompose an n × n symmetric matrix A into the product A = QΛQT where Q is the matrix whose columns are eigenvectors of A, is the matrix whose diagonal entries are the eigenvalues of A and all other entries are 0, and QT denotes the transpose of Q. Larger eigenvalues have a greater influence on the product QΛQT, so we can choose a positive integer k and store only the k largest eigenvalues and their corresponding eigenvectors to approximate the all-pairs matrix. Storing the matrix this way, memory usage increases linearly in k and n as opposed to quadratically in n.
Rather than first computing the full matrix A and then decomposing it, we can instead compute only a subset of A and attempt to construct the truncated decomposition of the full matrix from only that subset. In particular, computing the single-source geodesic distance from marked points of interest to all other points yields a subset of the rows and columns of A. Each iteration of the single-source geodesic algorithm provides less information than the last, so it seemed reasonable to end this process early and try to estimate the matrix using this information. The proposed algorithm to do this is as follows:
Compute the single-source geodesic distances for a subset X of the points of interest and store them as in an all-pairs matrix A.
Randomly initialize an n × n matrix Q (where n is the number of points of interest) and a set λ of size n. Λ will be the matrix whose only nonzero entries are the elements of λ along the diagonal. (If we save memory as described above, the last n – k columns of Q and the corresponding diagonal entries of Λ are set to 0. In this case, the elements of λ must be in descending order of magnitude.)
Until convergence:
Randomly sample m entries Ai,j from X and the diagonal of A (these entries are known to be 0).
For each sampled entry, compute the error |Ai,j – Σl QiλlQjT| where Qi denotes the ith column of Q and λl denotes the lth element of λ.
Take a gradient step to update Q and λ.
The hope is that this will converge to a reasonable approximation of the all-pairs matrix. I enjoyed studying this problem and look forward to implementing and testing this algorithm on some of the meshes we have been using throughout SGI.
By: Caroline Huber, Natalie Patten, and Xinyi Zhang
On August 1st we began working on a project titled: “Tight Isoperimetric Profiles” mentored by Richard Barnes of the Lawrence Berkeley National Lab and Michigan State University PhD student Erik Amezquita.
We began the first week by looking at “Medial Axis Isoperimetric Profiles” (Zhang, DeFord, & Solomon, 2020). We read this alongside excerpts from provided materials, such as: Skiena’s “The Algorithm Design Manual” and Garey and Johnson’s “Computers and Intractability.”
Initial code was used to replicate the findings of “Medial Axis Isoperimetric Profiles” and to use this to extrapolate our own algorithm. The figure below shows the computation of the medial axis of a shape from the aforementioned code.
Figure 1: Medial Axis Computation
The isoperimetric ratio (\(\frac{4\pi*A}{p^2}\)) of a shape with perimeter \(p\) and area \(A\) measures the compactness of said shape. To maximize the area and limit the perimeter of a shape, one would look for a shape with a high isoperimetric profile (the highest being a circle with a score of 1.0). However, for shapes with boundary perturbation, the ratio is unstable; hence the isoperimetric profile is used instead: \(IP_{\Omega}(t):=min\{length({\partial}F): F\subseteq\Omega \& area(F)=t\}\).
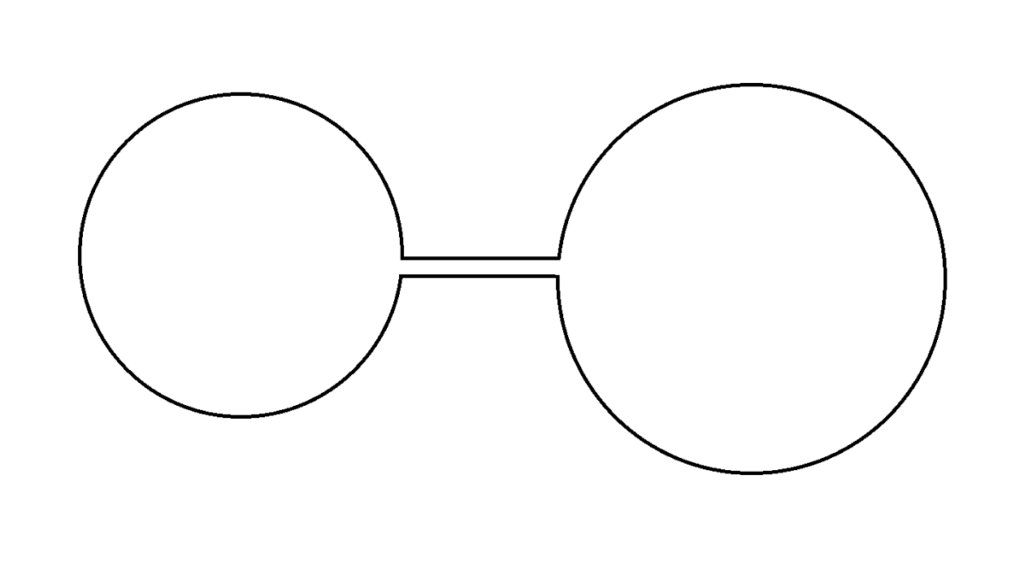
Currently, only brute-force methods exist for calculating isoperimetric profiles (IPs) of shapes with thin necks. Recent research, published in “Medial Axis Isoperimetric Profiles” has created a less expensive algorithm for computing IPs of shapes with thick necks, utilizing the concept of medial axes and graph nodes. By applying a greedy traversal along the medial axis of 2D shapes, this algorithm provides a tight bound for IPs of shapes with thick necks. However, the greedy traversal of adjacent nodes fails to provide a tight bound for IPs of shapes with thin necks. For example, Figure 2 is a clear illustration of the failure of the greedy traversal of adjacent nodes. In this case, the greedy traversal fails to capture the information of the large circle on the other side of the dumbbell due to the existence of a thin neck.
Figure 2: Shape with Thin Neck
Thus, we have expanded on this research and revised the algorithm to formulate our proposed algorithm for shapes with thin necks. An overview of the algorithm-along with germane nomenclature-can be viewed below:
To solve the problems created by the thin necks, we will partition the whole shape into different components according to its thin necks and define this new set of points as the set of centers of the largest circles in each component as \(L\). We will now apply the greedy algorithm not only to the adjacent points but also to the points in \(L\). In this way, we can solve the problems that cannot be solved by the original algorithm in cases like Figure 2 by capturing and encoding the information of the large circles on the other side of the thin necks in this \(L\) set.
Some problems we anticipate this algorithm may encounter include:
Shapes with many thin necks
Shapes with different size “openings” on either side of its thin neck(s)
We enjoyed working on this project and learning about isoperimetric profiles and the current research being done in this area. We also enjoyed learning about the different potential applications of this research–for example, to examine possible gerrymandering.
By SGI Fellows Hector Chahuara, Anna Krokhine, and Elshadai Tegegn
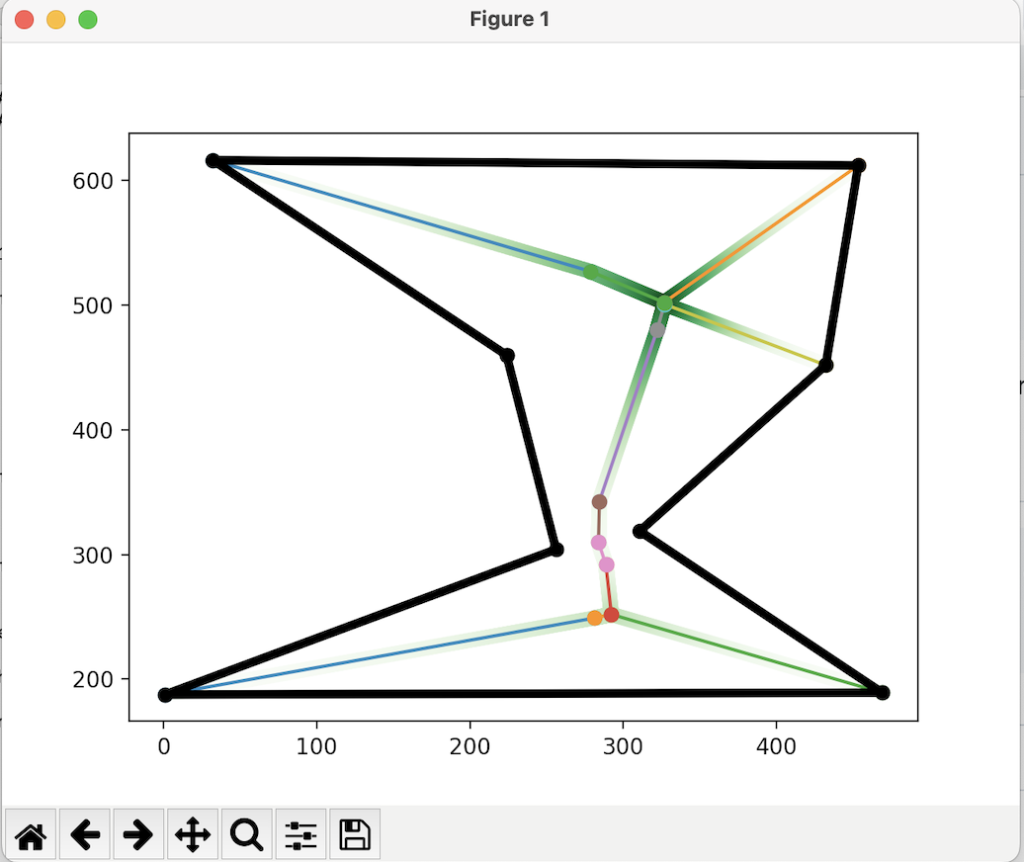
During the fourth week of SGI, we continued our work with Professor Paul Kry on Revisiting Computational Caustics. See the “Flat Land Reflection” blog post for a summary of work during week 3, wherein we wrote a flatland program that simulates light reflecting off a surface.
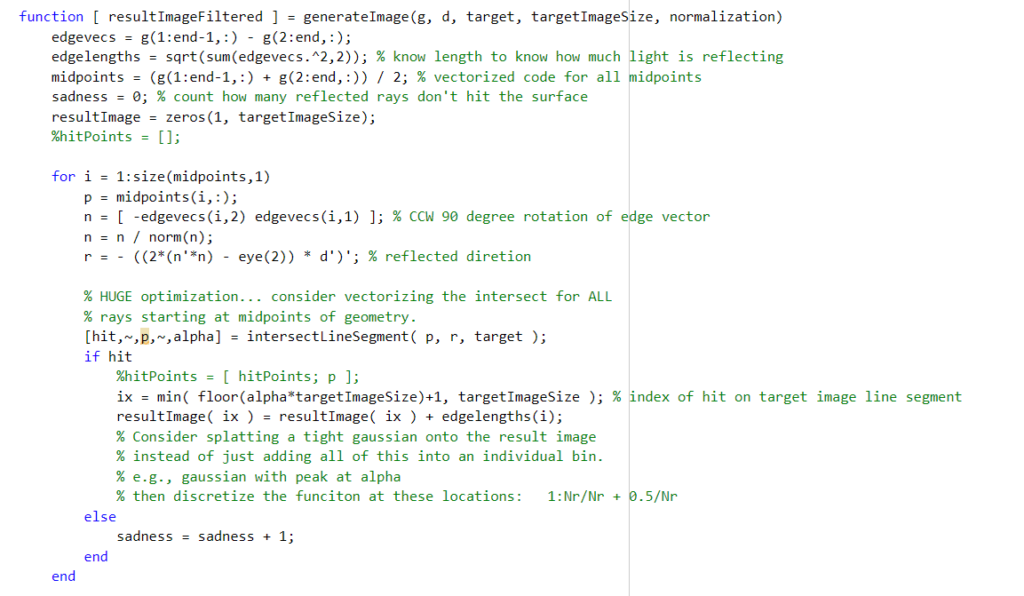
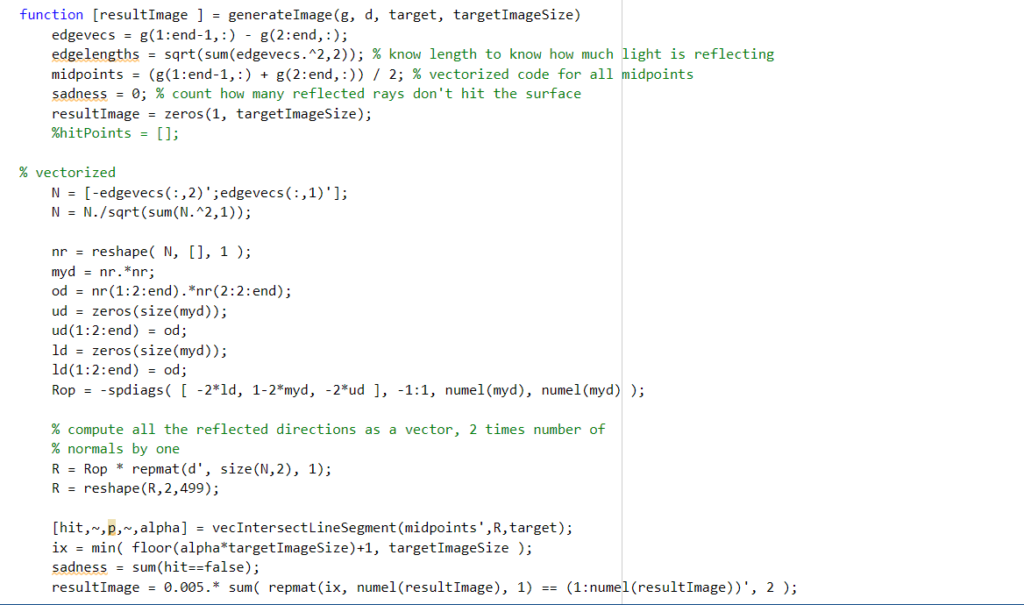
While the flatland program that we wrote did a good job of visualizing the reflection from the source onto the target geometry, the initial code was quite inefficient. It looped over each individual light ray, calculating the reflected direction and intersection with the target one by one. In order to optimize the code, Professor Kry suggested that we try and vectorize the main functions in the program. Vectorizing code means eliminating loops and instead using operations on full vectors and matrices containing the necessary information. In the case of this program, this meant writing a function that simultaneously calculates the intersections of all the reflected rays with the target surface, and then combines them into the resulting image at once (rather than looping over each individual ray’s contribution).
The most challenging part of this task was creating a matrix containing all the reflected directions, rather than just calculating one for a given ray. The equation for the reflected direction from a given normal n is
where d is the direction of the light ray from the source.
We needed to adapt this equation to input a 2xk matrix N containing k normals and get a 2xk matrix R. Because of the n’*n term, this is quadratic in each of the individual columns of N, making vectorization more difficult. One trick we used to resolve this was sparse matrices; that is, matrices with mostly zeros. The idea was that we could calculate and store all the resulting 2×2 matrices from each column in the same large sparse matrix, rather than calculating one at a time. The advantages of this approach is that the sparseness of the matrix makes it less expensive to store, and because other entries are zero, multiplication operations that act on each 2×2 block alone are easy to formulate.
Overall, vectorizing the code was a very fun challenge and good learning opportunity. This project pushed us to apply vectorization to situations with involved and creative solutions.
This blog post was inspired by the talk given by Prof. Yusu Wang during SGI. We use Topological Data Analysis to showcase its feature characterization principles and how it can be used for point cloud surface reconstruction. The code used to generate the different results below are stored on SGI’s GitHub, so give it a try. Let’s go!
Brief Introduction into Persistent Homology
Persistent homology is formed of two words: persistent and homology. Homology comes from homology groups, an intersection between group theory and topology. On a high-level, two objects are homotopic if they can be continuously deformed into one another. As such, they belong to the same group or class because they share the same properties. These homotopy properties can be commonly referred to in examples as the number of holes that an object possesses.
Homology is then used to describe more complex objects such as Simplicial Complexes and Functions.
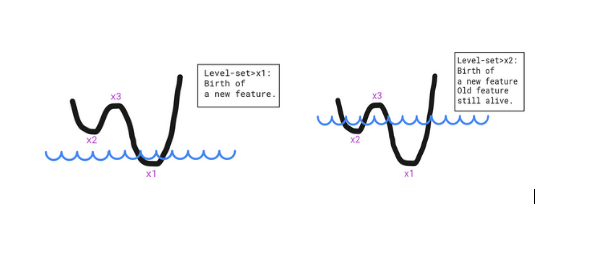
If we take functions, we can map every set level to a property that describes this function. This can best be seen as features induced by local extrema. Local minima tell us that a new feature was born (similar to the hole concept) and the local maxima tell us that some features have been merged and as a result no longer exist. The function below showcases two minima, which means two features are alive at some point simultaneously and disjointly (two separate holes filled water), but will disappear and be merged once the level-set reaches the local maximum.
Features can be seen as local minima that are covered with a level-set.
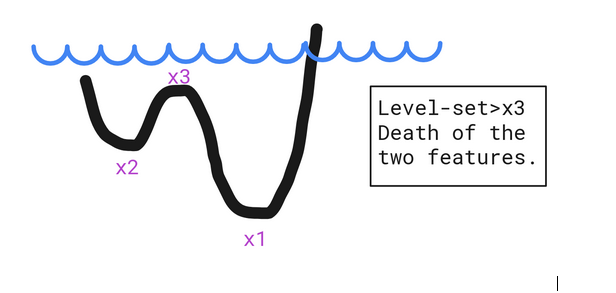
The death of the features happens when they get merged at a local maximum.
For a set of points, the characterization happens by first constructing a Simplicial Complex (Vietoris-Rips Complex, Čech Complex,…). This follows a logic which connects the points whose circles with radius r centered around them intersect. This is how k-simplices (such as points, edges,triangles, etc. where k is the number of mutually intersecting circles) are built. What happens afterwards is that, in order to find the characteristics of a set of points, the radius r is increased and as we go, the features are detected from the resulting Simplicial Complex.
Now that we have our features, we need to measure their importance and this is what persistence is meant to do. Persistence, is then the act of quantifying the difference between the death and birth of these features, i.e how long a specific feature existed. which helps in assessing the importance of a feature.
For this reason, Persistent Homology can serve as a de-noising tool or can simply act as an object descriptor.
GUDHI: Library for Topological Data Analysis (TDA)
Now, let’s see all of the concepts we have explained in practice. For that, we will use the GUDHI library for Topological Data Analysis.
We present the following examples to showcase the persistence diagrams obtained for different set of points.
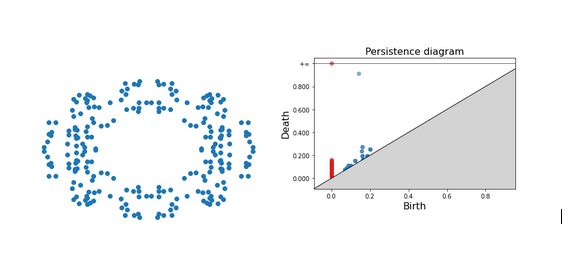
Persistence diagrams have these properties: 1) The red points are the 0-simplices, which are dots, points or disks. 2) The blue points are the 1-simplices characterized by a hole. 3) The points that are far off the diagonal live longer, which means that they are more prominent/important.
For the first example, we can see for instance that one blue dot is very far from the diagonal, which means that this is one of the most important features of our set. The other blue dots which stem from the gap between our points but disappear quickly.
Persistence Diagram of a set of points forming a ring.
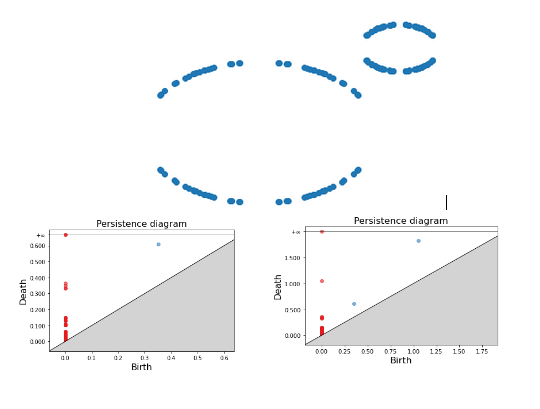
For the second example, we present two persistence diagrams based on two maximum radius thresholds. For a small threshold, we only have one blue dot; the smaller ring is detected because a small threshold matches its small radius. As this threshold gets bigger, we are then able to detect the second bigger ring. Increasing the threshold even further merges these two circles into one component as the different vertices get connected in an indiscernible way.
1) (Left) Persistence Diagram of a set of points forming two rings with a small maximum threshold. 2) (Right) Persistence Diagram of a set of points forming two rings with a big maximum threshold.
Surface Reconstruction with TDA
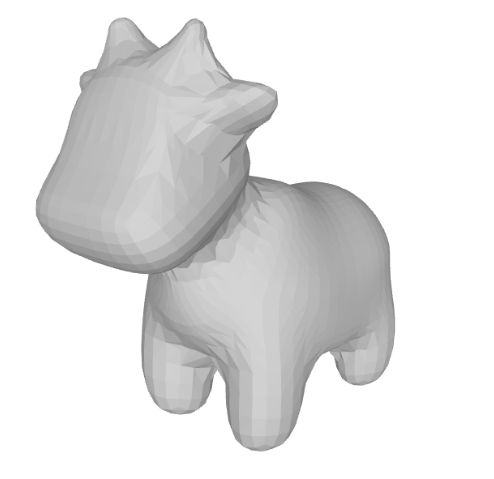
Now that we have used the different elements from the Topological Data Analysis, we will adopt the Simplicial Complex concept and use it to create the surface of a known mesh: spot.
The original mesh.
We only consider the point cloud from the mesh and try to estimate the surface by creating the connections between three vertices at once. Once these connections are made, we save a new mesh with these faces connections. Depending on the threshold set to connect the vertices we obtain different levels of precision:
Reconstruction based on the faces from Vietoris-Rips Complex with a low maximum threshold.
Reconstruction based on the faces from Vietoris-Rips Complex with a big maximum threshold.
Conclusion
We have shown in this blog post how Topological Data Analysis and in particular Persistent Homology can be used to find structure in a set of points. This can lead to characterizing the set’s properties in addition to allowing the execution of known tasks in Geometry Processing such as Surface Reconstruction.
References
[1] Persistent Homology—a Survey, Herbert Edelsbrunner and John Harer.
By Tiago De Souza Fernandes, Bryan Dumond, Daniel Scrivener and Vivien van Veldhuizen
If you have been keeping up with some of the recent developments in artificial intelligence, you might have seen AI models that can generate images from a text-based description, such as CLIP or DALL·E. These models are able to generate completely new images from just a single text-prompt (see for example this twitter account). Models such as CLIP and DALL·E operate by embedding text and images in the same vector space, which makes it possible to frame the image synthesis as an optimization problem, ie: find an image that, when processed by a neural network, yields an embedding similar to a corresponding text embedding. A problem with this setup, however, is that it is severely underconstrained: there are many such images and some of them are not very interesting from the perspective of a human. To circumvent this issue, previous research has focused on incorporating priors into this optimization.
Over the last few weeks, our team, under the supervision of Matheus Gadelha from Adobe Research, looked into a specific instance of such constraints: namely, what would happen if the images could only be formed through a simple assembly of geometric primitives (spheres, cuboids, planes, etc)?
An Overview of the Optimization Problem
The ability to unite text and images in the same vector space through neural networks like CLIP lends itself to an intuitive formulation of the problem we’d like to solve: What image comprising a set of geometric primitives is most similar to a given text prompt?
We’ll represent CLIP’s mapping between images/text and vectors as a function, $\phi$. Since CLIP represents text and images alike as n-dimensional vectors, we can measure their similarity in terms of the angle between the two vectors. Assuming that the vectors it generates are normalized, the cosine of the angle between them is simply the dot product \(\langle \phi(Image), \phi(Text) \rangle\). Minimizing this quantity with respect to the image generated from our geometric primitive of choice should yield a locally optimal solution: something that more closely approximates the desired text prompt than its neighbors.
Two sample images — a golden retriever and a 2006 Toyota Camry — alongside their respective descriptions according to CLIP. The cosine similarity of the first image relative to the prompt “a golden retriever” is 0.2690, compared to 0.1586 for the second image.
In order to get a sense of where the solution might exist relative to our starting point, we’d like all operations involved in the process of computing this similarity score to be differentiable. That way, we’ll be able to follow the gradient of the function and use it to update our image at each step. To achieve our goals within a limited two-week timeframe, we desire rasterizers built on simple but powerful frameworks that would allow for as rapid iteration as possible. As such, PyTorch-based differentiable renderers like diffvg (2D) and Nvdiffrast (3D) provide the machinery to relate image embeddings with the parameters used to draw our primitives to the screen: we’ll be making extensive use of both throughout this project.
2D Shape Optimization
We started by looking at the 2D case, taking this paper as our basis. In this paper, the authors propose CLIPDraw: an algorithm that creates drawings from textual input. The authors use a pre-trained CLIP language-image encoder as a metric for maximizing the similarity between the given description and a generated drawing. This idea is similar to what our project hopes to accomplish, with the main difference being that CLIPDraw operates over vector strokes. We tried a couple of methods to make the algorithm more geometrically aware, the first of which is some data augmentations.
By default, the optimizer has too much creative leeway to interpret which images match our text prompt, leading to some borderline incomprehensible results. Here’s an example of a result that CLIP identifies as a “golden retriever” when left to its own devices:
Prompt = “a golden retriever” after 8400 iterations
Here, the optimizer gets the general color palette right while missing out completely on the geometric features of the image. Fortunately, we can force the optimizer to approach the problem in a more comprehensive manner by “augmenting” (transforming) the output at each step. In our case, we applied four random perspective & crop transformations (as do the authors of CLIPDraw) and a grayscale transformation at each step. This forces the optimizer to imitate human perception in the sense that it must identify the same object when viewed under different ambient conditions.
Fortunately, the introduction of data augmentations produced near-instant improvements in our results! Here is a taste of what the neural network can generate using triangles:
Prompt = “a Golden Retriever”Prompt = “a lighthouse”
Generating Meshes
In addition to manipulating individual shapes, we also tried to generate 2D triangular meshes using CLIP and diffvg. Since diffvg doesn’t provide automatic support for meshes, we circumvented this problem using our own implementation where individual triangles are connected to form a mesh. We started our algorithm with a simple uniform randomly-colored triangulation:
Initial mesh
Simply following each step in the gradient direction could change their positions individually, destroying the mesh structure. So, at each iteration, we merge together vertices that would have been pushed away from each other. We also prevent triangles from “flipping”, or changing orientation in such a way that would produce an intersection with another existing triangle. Two of the results can be seen below:
Prompt = “Monalisa”Prompt = “Batman”
Throughout this process, we introduce and subsequently undo a lot of changes, making the process inefficient and the convergence slow. Another nice approach is to modify only the colors of the triangles rather than their positions and shapes, allowing us to color the mesh structure like a pixel grid:
Prompt = “Balloon” without changing triangle positions
Non-differentiable Operations and the Evolutionary Approach
Up until this point, we’ve only considered gradient descent as a means of solving our central optimization problem. In reality, certain operations involved in this pipeline are not always guaranteed to be differentiable, especially when it comes to rendering. Furthermore, gradient descent optimization narrows the range of images that we’re able to explore. Once a locally optimal solution is found, the optimizer tends to “settle” on it without experimenting further — often to the detriment of the result.
On the other end of the “random-deterministic” spectrum are evolutionary models, which work by introducing random changes at each step. Changes that improve the result are preserved through future steps, whereas superfluous or detrimental changes are discarded. Unlike gradient descent optimization, evolutionary approaches are not guaranteed to improve the result at each step, which makes them considerably slower. However, by exploring a wider set of possible changes to the images, rather than just the changes introduced by gradient descent, we gain the ability to explore more images.
Though we did not tune our evolutionary model to the same extent as our gradient descent optimizer, we were able to produce a version of the program that performs simple tasks such as optimizing with respect to the overall image color.
Prompt = “red” after 0 and 60 iterations
3D Shape Optimization
Moving into the third dimension not only gives us a whole new set of geometric primitives to play with, but also introduces fascinating ideas for image augmentations, such as changing the position of the virtual camera. While Nvdiffrast provides a powerful interface for rendering in 3D with automatic differentiation, we quickly discovered that we’d need to implement our own geometric framework before we could test its capabilities.
Nvdiffrast’s renderer is very elegant in its design. It needs only a set of triangles and their indices in addition to a set of vertex colors in order to render a scene. Our first task was to define a set of geometric primitives, as Nvdiffrast doesn’t provide out-of-the-box support for anything but triangles. For anyone familiar with OpenGL, creating an elementary shape such as a sphere is very similar to setting up a VBO/EBO. We set to work creating classes for a sphere, a cylinder, and a cube.
Random configuration of geometric primitives — a cube, a cylinder, and a sphere — rendered with Nvdiffrast. One example of an input to our algorithm.
Because the input to Nvdiffrast is one contiguous set of triangles, we also had to design data structures to mark the boundaries between discrete shapes in our triangle list. We did not want the optimizer to operate erratically on individual triangles, potentially breaking up the connectivity of the underlying shape: to this end, we devised a system by which shapes could only be manipulated by a series of standard linear transformations. Specifically, we allowed the optimizer to rotate, scale, and translate shapes at will. We also optimized according to vertex colors as in our previous 2D implementation.
With more time, it would have been great to experiment with new augmentations and learning rates for these parameters: however, setting up a complex environment like Nvdiffrast takes more time than one might expect, and so we have only begun to explore different results at the writing of this blog post. Some features that show promising outcomes are color gradient optimization, as well as the general positioning of shapes:
Prompt = “red”Prompt = “rainbow”prompt = “a centered red square” (before and after optimization)
Conclusion
Working on this project over the last few weeks, we saw that it is possible to achieve a lot with neural networks in a relatively short amount of time. Through our exploration of 2D and 3D cases, we were able to generate some early but promising results. More experiments are needed to test the limits of our model, especially with respect to the assembly of complex 3D scenes. Nonetheless, this method of using geometric primitives to synthesize images seems to have great potential, with a number of artistic applications making themselves evident through the results of our work
By Caroline Huber, Alan Goldfarb, and Denisse Garnica
In the first project of SGI, for us, Julia Sets – where we (in simple terms) attempt to approximate 2D and 3D shapes with a Julia Set – much interesting work was done. The official problem statement is: Can we train a neural network to predict the corresponding filled Julia set approximation for any given input shape? With daily collaborative meetings and independent coding work we first attempted to understand how to construct these sets with code. We worked our way through several established papers on the subject both independently as well as in several collaborative zooms (see pdfs below).
Then, we worked on experimenting with some base code that one of our mentors, Richard Liu, provided. By experimenting, we mean that we altered various attributes of the presented function and observed the effects on the fractal output. We changed the values of the roots, their multiplicities, the number of roots, and we added scalar multiples and so on. For reference, Figure 1 is the original fractal. Multiplying by a scalar less than one resulted in less separation between the affected roots (closer together). This is shown in the following figures: multiplying the whole function by a scalar of 0.5 resulted in figure 2 and multiplying just the second and fourth roots by a scalar multiple of 0.5 resulted in figure 3.
Figure 1Figure 2Figure 3
Conversely, multiplying by a scalar larger than 1 resulted in increased separation between the affected roots (farther apart). The result of multiplying by a scalar of 1.3 resulted in figure 4.
Figure 4Figure 5Figure 6
Further experimentation included scalar multiple and changing all roots to be double (multiplicity 2), as seen in figure 5, and scalar multiple with only changing the multiplicity of a single root (to be double), as seen in figure 6.
We created a function to add color to the non-Julia Set points. Defining the color with the “escape velocity”. The Julia set -explained in a very ambiguous way- is a set of points that stays in some certain region after many iterations of a function. The “escape velocity” is how long it takes to a point to go outside the region. According to that number we change the color of the point. And we obtain images like this one.
Here all the black points represent the Julia set. The dark-green points are the ones that have a minor escape velocity and the brightest are the ones that took longer to go outside.
We decided that it would be helpful to be able to zoom into these fractals and see what they look like up close (especially with the alterations). So, we added code that zoomed in on a point slightly off-center. Then, we combined several of those images into a gif that runs through them all. (see attachment 1)
Attachment 1
We collaborated to create another gif that runs through frames where the root location is altered, and the picture zooms in on this change. We provided the code to identify and alter the roots and then combined the frames. (see attachment 2 for altered root multiplicities and attachment 3 for a zoom of altered roots).
Attachment 2Attachment 3
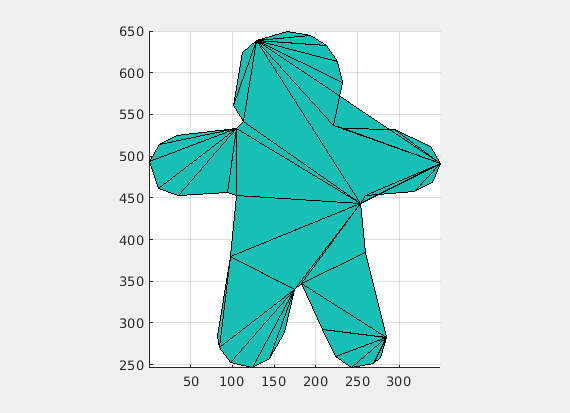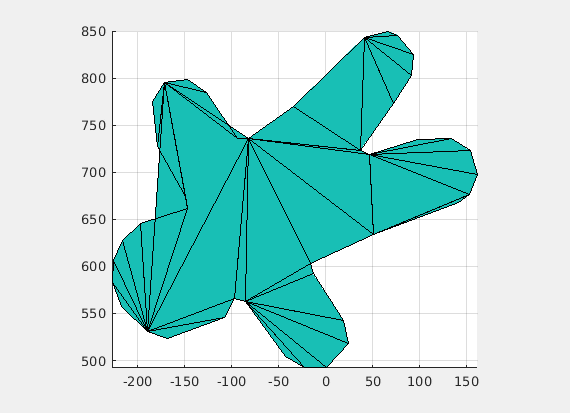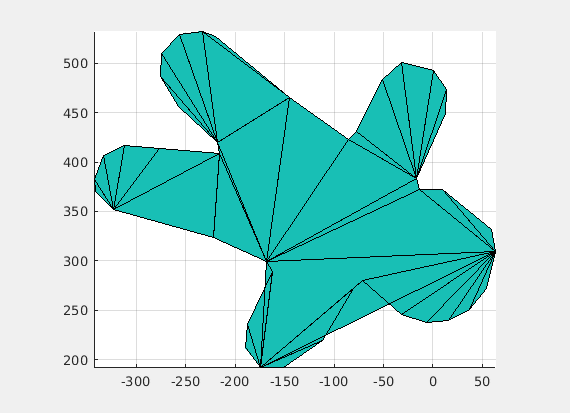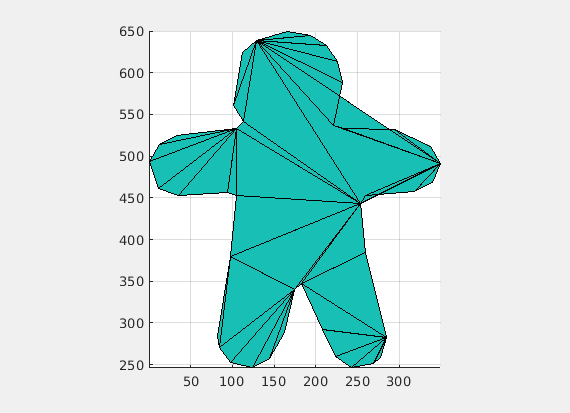
Now that Julia sets have been seen in an intuitive way, let’s see a little more formality. Julia sets of rational maps are determined as follows: Given a rational map (a function of the form f(q)) a complex number q is in the corresponding Julia set if the below limit does not diverge. Here, fn denotes the nth recursion of f. The constants r1,r2, . . ., rt and s1, s2 , . . .,sb are respectively called the top and bottom roots of f.
Equation 1Equation 2
In order to generate plots of these sets we approximated the set by iterating the function a fixed number of times and comparing the output against a threshold value. Only inputs which produced a value below the threshold were included in the Julia set. We then plotted the filled Julia set by plotting the interior of the Julia set.
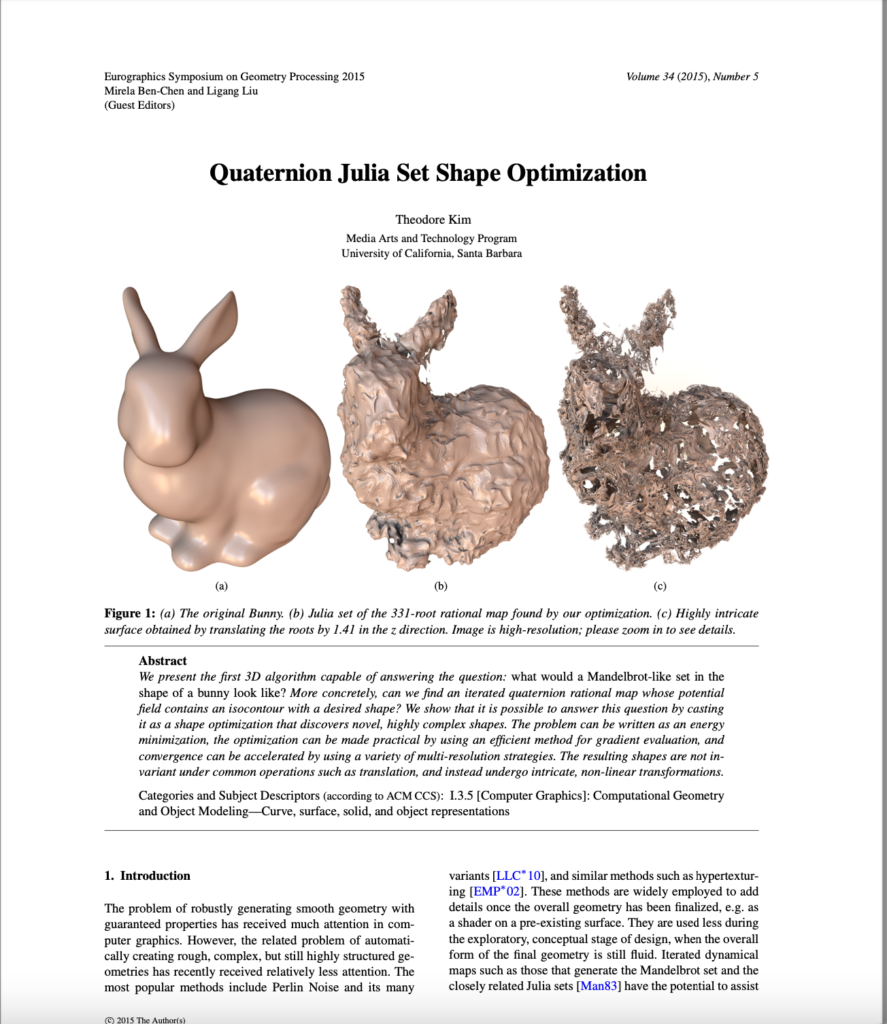
Some of the filled Julia sets we generated behaved in ways which differed from our initial expectations. According to a paper by Dr. Theodore Kim, points close enough to top roots would be included in the filled Julia set and points close enough to bottom roots would not. Dr. Kim stated that to approximate a given curve with a Julia set one should use a rational function with roots along that curve. However, we realized that symmetric placement of the roots can generate asymmetric Julia sets and that placing roots along the boundary of a shape did not always produce a filled Julia set corresponding to that shape.
In order to get a better understanding of why this might be occurring, we read a few papers describing the mathematical structure of Julia sets of rational functions. We delved deeper into these papers and explained some strange properties about Julia sets. For instance, a Julia set of a polynomial cannot have any mirror symmetries which are not also rotational symmetries. This is the case even if the placement of the roots is symmetric. This led us to the realization that adding roots to a function can have global consequences on the shape of the function’s Julia set which makes the problem of approximating even simple shapes with Julia sets seem more difficult than initially anticipated.
This project has been very interesting for the three of us and we are looking forward to see what we can achieve in the future. We will continue exploring Julia sets, and hopefully we will be able to approximate interesting figures!
By Abraham Kassahun, Dimitry Kachkovski, Hongcheng Song, Shaimaa Monem
Introduction
It has been two weeks of the projects phase in SGI and our team has been working under the guidance of David Levin and Rohan Sawhney on a very interesting approach to solving differential equations using Mixed Finite Element Method.
In the beginning we were looking at how general Finite Element Methods (FEM) are used to solve the 2D Screened Poisson Equation (and later on a 3D one). First and foremost, we need to understand what FEM is. It is a discretization method that allows us to accurately solve differential equations. It allows us to break up a large system into simpler finite parts (in our case – triangles), and to make certain assumptions over these finite elements that help find a feasible solution.
If we look into the very simple case of only one triangle mesh, then given 3 vertices \(v_1, v_2, v_3\) that form this triangle, we attach a value of a function \(u\) at each of them (that is \(u(\textbf{v}_1),u(\textbf{v}_2),u(\textbf{v}_3)\)are known). To get the value of \(u(\textbf{v})\), for a point \(\textbf{v}\) inside the triangle, we can use various ways of interpolating between the 3 given values. Linear interpolations are often very useful for simulation, and we can use for instance barycentric coordinates as a way to interpolate these values.
A variation of the FEM method that we are exploring is called Mixed FEM. Its main idea is the introduction of supplementary independent variables that create additional constraints on the system. Mixed finite element method can precisely solve some very complex PDEs, while the ultimate goal of utilizing it in our project is to provide another more flexible skinning strategy, which automatically tunes deformation parameters to triangles by artist specified controls, while paving the way to an optimized version of the solver via the Adjoint Method.
Screened Poisson Equation
Figure 1. Screened Poisson equation solve over a 2D mesh with animated alpha parameter. (Credit: Abraham Kassahun Negash)
To understand how mixed FEM works, we first applied it to the heat equation. It turns out that it doesn’t have any advantages when applied to the heat equation, but it was a good pedagogical detour to understand how it works exactly. The heat equation is a type of Poisson equation described as:$$\Delta u = f$$ If solved as is, the resulting equation will not have a unique solution due to the absence of a Dirichlet boundary condition. Instead we modified the equation slightly by including an \(\alpha u\) term which allows the equation to be solved without explicitly giving any boundary conditions in MATLAB. $$\Delta u – \alpha u = f$$ This equation is also called the screened Poisson equation. We can solve for \(u\) by minimizing the following energy. $$E(u) = \frac{1}{2}\int_{\Omega}||\nabla u||^2 \,d\Omega + \frac{1}{2}\int_{\Omega} \alpha ||u||^2 \,d\Omega – \int_{\Omega} fu \,d\Omega$$ Where \(\Omega\) is our domain of interest. We can define \(u\) as a vector of values evaluated at the vertices of a triangle mesh. Then the equation can be discretized by writing \(u\) as the weighted average of vertex values. $$u(x) = \sum_{i=1}^3{\phi_i (x) u_i}$$ Where \(\phi_i (x)\) are the shape functions we use to interpolate \(u\) inside the triangle. We are going to let \(u\) be piecewise linear over our mesh by choosing linear shape functions. Thus the gradient of \(\phi\) is constant inside the triangle. Substituting into \(u\) and performing the integration we get the following expression. $$E(u) = \frac{1}{2}u^T G^T W G u + \frac{1}{2}\alpha u^T M u – u^T M f$$ Where:
\(G\) is the gradient matrix defined over the mesh
\(W\) is the weight matrix resulting from integrating \(\nabla u\) over faces
\(M\) is the mass matrix resulting from integrating functions over vertices
\(G\) is the gradient operator over the mesh and only depends on the vertex positions. The mass and weight matrices can be taken as identity by assuming a uniform mesh of equal triangles. It can be seen that the term with an \(\alpha\) acts the potential energy of a spring penalizing deviation of \(u\) from 0, thus preventing the solution from blowing up. The solution therefore reduces to $$E(u) = \frac{1}{2}u^T G^T G u + \frac{1}{2}\alpha u^T u – u^T f$$
To solve for \(u\) we formulate an optimization problem in a discrete form over some finite cells of a given surface, that is we build a Finite Element system and find the minimizer as follows:
$$u^* = \arg \min_{u}(\frac{1}{2} u^T G^T G u + \frac{1}{2} \alpha u^T u – u^T f)$$
Finally, to minimize the above system with the standard FEM, we must take the derivative of the function w.r.t. \(u\), and since the system is quadratic, setting the result to zero and solving for \(u\) will yield the answer. That is if we define the energy as $$E(u)=\frac{1}{2}u^T G^T G u + \frac{1}{2}\alpha u^T u – u^T f)$$ then we compute the gradient $$\nabla_u{E}=G^T G u + \alpha u – f =0$$ and we get $$G^T G u + \alpha u = f\\ (G^T G + \alpha I)u=f\\ u=(G^T G + \alpha I)^{-1} f$$
This means that the discrete solution can be computed through a linear system solution.
Mixed FEM
Figure 2. Mixed FEM solution of the ARAP energy by rotating a single triangle. (Credit: Shaimaa Monem)
As mentioned in the introduction, the main idea behind Mixed FEM is to introduce an additional independent variable that we solve for to allow us to optimize the search for the full solution to our system. That is, we will make everything much more complicated so as to make it easier later on! Yay!
We introduce such a variable by taking a part of the original energy equation \(E(u)\), and setting a constraint. That is, we want to reformulate the original minimization as $$g^*,u^* = \arg \min_{u,g}(\frac{1}{2} g^T g + \frac{1}{2} \alpha u^T u – u^T f)\\ s.t. \ Gu-g=0$$
The idea definitely feels awkward at first. But what we are looking to do is to define \(Gu\) as some variable that is independent of \(u\) itself, but that constrains the system for \(u\). Think of how the search for \(u\) was like turning some dials, and \(Gu\) was another dial that would turn as you try different settings for \(u\). Our goal is to separate that connection so that we can search for both independently, with that search governed by the established rule aka. our constraint.
To solve the newly emergent constrained optimization we use the method of Lagrange Multipliers and formulate our system as: $$\mathcal{L}{g^*,u^*,\lambda}=\arg \max_{\lambda} \min_{g^*,u^*}E + \lambda^T(Gu-g)\\ \mathcal{L}{g^*,u^*,\lambda}=\arg \max_{\lambda} \min_{g^*,u^*} \frac{1}{2} g^T g + \frac{1}{2} \alpha u^T u – u^T f + \lambda^T(Gu-g) $$
Now, we just need to take the gradient w.r.t. each of the variables, set them as before to 0, and solve for our 3 variables! That gets us: $$ \nabla_g=g-\lambda=0\\ \nabla_u=\alpha u – f + G^T \lambda=0\\ \nabla_{\lambda}=Gu-g=0$$
These 3 conditions that we got are known as Karush-Kuhn-Tucker (KKT) conditions. Using them we formulate a larger system that we solve: $$\begin{bmatrix} I & 0 & -I \\ 0 & \alpha I & G^T \\ -I & G & 0 \end{bmatrix} \begin{bmatrix} g\\ x\\ \lambda \end{bmatrix} = \begin{bmatrix} 0\\ f\\ 0 \end{bmatrix}$$
Solving this system will give us the solution that we are after.
Now this alone is obviously not a way to speed our solution up. However, the Mixed FEM formulation allows us to combine it with a numerical method known as the Adjoint Method, which in turn will indeed speed up the whole system. It also allows us to leverage certain aspects of deformation energies and their formulations which avoids such heavy handed computations as SVDs.
But before we get there, let’s move away from the toy problem, and consider how our mesh will deform.
As-Rigid-As-Possible (ARAP) Energy
Figure 3. A sine-based animation using Automatic Skinning using Mixed FEM. (Credit: Dimitry Kachkovski)
Deformation of elastic objects can be described using various different models. The one we consider is known as the As-Rigid-As-Possible model (Sorkine and Alexa, 2007).
ARAP is a powerful energy term which is invariant to rigid transformations, and it is designed to measure deformation in our system setting clearly, which has the form: $$E(F) = \| S – I \|_{F}^2$$ Where \(F\) represents the total transformation while \(S\) is a parameter unrelated to rigid transformation, which can be generated from polar decomposition from \(F\) using the relation \(F = RS\), where \(R\) is a rigid transformation. Therefore, energy is only dependent on non-rigid transformation, which has a global minimum at Identity. In this case, \(E(R) = 0\) and \(E(RS) = E(S)\). Instead of finding \(S\) through decomposition every time, what Mixed FEM allows us to do is to let \(S\) be an independent variable and enforce the relation \(F = RS\) with a constraint. Therefore, \(E\) can now be written as:$$E(S) = \| S – I \|_{F}^2$$
Using second-order Taylor expansion, ARAP energy takes the following form: $$E(S) = \frac{1}{2}S^THS + G^TS$$Where \(H\) and \(G\) are Hessian and gradient matrices, respectively.
Any rigid transformation exerted on triangle mesh will result in zero ARAP energy, but for any non-rigid deformation on triangle mesh, ARAP will clearly generate the corresponding energy. For example, in our gingerBrad man example, we pin down a rotation for a triangle; hence, the only possible situation to keep ARAP energy be zero is forcing all rotations of other triangles to be the same as the pinned one. You can imagine that if one of those triangles does not conform to the same rotation, non-rigid deformation will be generated in that triangle, leading to the growth of ARAP energy. So, ARAP skinning energy is indeed measuring the difference of energy between the current system state and the As-Rigid-As-Possible state with two boundary conditions, and the current state will finally reach the As-Rigid-As-Possible state by the optimizer.
Yoga Performance with Adjoint Method
1.1 Motivation and task formulation
Assuming we have a physics-based animation scene that we would love to visualize, we always start from a the continuous setting, then we choose a discretization scheme that allows us to write a piece of code to simulate our animations, we then pick our favorite programming language and turn the discrete model into a script that our computers can understand and deal with. If we are animating a character, then we would like it to match a specific behavior that is visually appealing, for example a special yoga pose. Well, assuming our character is sportive and flexible, then our simulator might do a good job imitating the desired behavior, if we define flexibility and athletic ability as parameters and feed them to our model. And we can see that in order to achieve successful animation we required three ingredients:
Discrete model simulating our object’s animations,
Target behavior for the object,
Input parameters tuning the object’s properties.
Sounds simple enough! But it implies that we need to know everything beforehand, which is not the case with movie character animation. We might know our target behavior but we do not know the parameters values that take us to this specified behavior, for instance how do we tune flexibility for gingerBrad so that it can do yoga without breaking?
We can express this yoga pose as a desired deformation through a deformation energy which happens to be the well known and previously mentioned ARAP energy. Therefore, we can basically translate this into an optimization task to find, for instance, the threshold \(p^{\star}\) of the flexibility parameter that is enough to reach the yoga pose, $$p^{\star} = \arg \min_{p} \ E_{ARAP}(p)$$
If you have been to a yoga class, then you have heard your instructor say – “Keep your toes forward and your heels down to the floor, straight back…” – and so on! Well, this is one of the powers that comes with using skinning technique: we can easily pin gingerBrad’s feet to the ground using handles, as follows: $$p^{\star} , x^{\star} = \arg \min_{p,x} \ E_{ARAP}(p) + \frac{k}{2} \| P x – x_{pinned} \|^2 $$
This means that we can optimize not only over \(p\) but also over all vertex positions \(x\) of the gingerBrad mesh, and we get \(x^{\star}\) the optimal position that is as close as possible to the pose we want, with heals \(x_{pinned}\) pinned to the ground. In the equation above \(P\) is a pinning matrix that selects from \(x\) only the verts to which we assign boundary conditions (here simply pinning!).
So far so good. Now let us imagine a more complex scenario where it is hard to exactly define what that target pose would look like. To picture this situation, let us assume that the gingerBrad character actually got a job as a yoga instructor, and now many characters are standing behind copying the yoga moves! Well, realistic experience tells us that they will not all reach the same exact final yoga pose, as they have different body properties reflected through a wide range of flexibility parameter values, and for the sake of our health and sanity we want to avoid solving a separate problem for each participant, especially ifgingerBrad is a very beloved famous coach and his class is always full :-)
We know that we want all of them to go as close as they could to a specific yoga pose, so let us assume, for simplicity, that we want them to rotate their bodies while still standing on the ground We can represent this very special yoga pose with a rotation matrix \(R\). But we can clearly see that the way this rotation task goes for each of them depends on their shapes, i.e. positions \(x\), and properties, or, as we call it, parameters \(p\), which in turn depend on the assigned rotation, meaning we have \(x(R)\) and \(p(R)\).
To find the rotation that each of them can achieve, we must formulate another optimization task:
$$ R^{\star} = \arg \min_{R} \ E_{ARAP}(p) + \frac{k}{2} \| P x – x_{pinned} \|^2 + \| R – R_{pinned} \|^2$$
Where \(R_{pinned}\) makes sure that our animated characters perform rotation around their pinned vertices, for consistency.
Now arises a huge EXISTENTIAL QUESTION, if \(R\) depends on\(p\) and \(x\) which in return are functions of \(R\), how can we compute any of them??
1.2 Apply Adjoint Method
Well basically the adjoint method is the solution to this problem, and we will go through this step by step.
First, remember that finding \(R^{\star}\) is our ultimate goal, as we want to visualize the yoga poses for all our animated characters and visualize how they perform. We ask ourselves, what do we need to solve the second optimization to compute \(R^{\star}\)? And the simple answer is that we need to find the critical points to the gradient $$E(R)= E_{ARAP}(p)+ \frac{k}{2} \| P x – x_{pinned} \|^2 + \| R – R_{pinned} \|^2\\ \frac{d E(R)}{d R} = \frac{\partial x}{\partial R} \frac{\partial E(R)}{\partial x} + \frac{\partial p}{\partial R} \frac{\partial E(R)}{\partial p} + \frac{\partial E(R)}{\partial R} = 0$$ While computing this gradient requires \(\frac{\partial x}{\partial R}\) and \(\frac{\partial p}{\partial R}\) as \(x\) and \(p\) are functions of \(R\).
Second, we can actually exploit the first optimization problem to compute \(\frac{\partial x}{\partial R}\) and \(\frac{\partial p}{\partial R} \).
Let’s perform the steps for a special parameter and explain more. We want \(p\) to relate to the deformation \(F\) which expresses the deformed state. We can specifically use the polar decomposition and write \(F\) as a decomposition of a rotation matrix \(R\) and a symmetric matrix \(S\), i.e. \(F = R S\). Remember that we are optimizing \(R\), therefore we are left with \(S\) to pick as our parameter. Moreover, we can find a linear operator called deformation gradient \(B\) that represents this deformation and basically takes our character from its rest reference pose to the deformed yoga performance pose. This gives us a constraint \( B x = RS\) which leads to the following constrained optimization problem
$$ S^{\star} , x^{\star} = \arg \min_{S,x} \ E_{ARAP}(S) + \frac{k}{2} \| P x – x_{pinned} \|^2 $$
Such that \( B x = R S\) (note: I am skipping technical details for simplicity!)
Now the latest constrained optimization task can be happily solved through a Lagrangian energy, actually arising from a mixed FEM problem as explained previously.
$$L(S, x, \lambda) = E_{ARAP}(S) + \frac{k}{2} \| P x – x_{pinned} \|^2 + \lambda (Bx – RS)$$
And like we saw in the very beginning of the report we proceed with computing the gradients of \(L(S, x, \lambda)\) w.r.t. its three different variables and formulate a linear system to solve
$$\nabla_S L = HS + g^T – R^T \lambda = 0\\ \nabla_x L = \frac{k}{2} P^TP + B^T \lambda = 0\\ \nabla_{\lambda} L = B x- R S = 0$$
We rewrite this as \(A y = b \) , where \(A\) is the KKT matrix and \(y = (S^{\star}, x^{\star} , \lambda)^T\) is the solution for our first optimization problem.
Third, we can extract \(S^{\star}\) and \(x^{\star}\) from \(y\) and fix them in \(E(R)\), which leads to $$E(R)= E_{ARAP}(S^{\star})+ \frac{k}{2} \| P x^{\star} – x_{pinned} \|^2 + \| R – R_{pinned} \|^2$$
Fourth, now we can see that, actually, the derivatives that we require are \(\frac{\partial x^{\star}}{\partial R}\) and \(\frac{\partial S^{\star}}{\partial R}\) , which can be computed by differentiating \(y\) , i.e. \(\frac{\partial y}{\partial R} = (\frac{\partial S^{\star}}{\partial R} , \frac{\partial x^{\star}}{\partial R} , 0)^T\), given by $$\frac{\partial y}{\partial R} = \frac{\partial A^{-1}}{\partial R} \ b\\ \frac{\partial y}{\partial R} = – A^{-1 } \ \frac{\partial A}{\partial R} A^{-1 } \ b$$
Finally, now that we have \(\frac{\partial x^{\star}}{\partial R}\) and \(\frac{\partial S^{\star}}{\partial R}\), we can basically substitute them into the energy derivative \(\frac{d E(R)}{d R}\) and find \(R\) as the critical point, Woooh!
One more important aspect that we need to take care of is to make sure that \(R\) stays still as a rotation matrix along the optimization task, for this reason, we explicitly write \(R\) as an orthogonal 2D matrix $$R(\theta) = \begin{bmatrix} cos \theta & sin \theta \\ – sin \theta & cos \theta \end{bmatrix} $$ And express our energy in terms of \(\theta\) instead, as follows $$\frac{d E(\theta)}{d \theta} = \frac{\partial x}{\partial \theta} \frac{\partial E(x(\theta),p(\theta),\theta)}{\partial x} + \frac{\partial p}{\partial \theta} \frac{\partial E(x(\theta),p(\theta),\theta)}{\partial p} + \frac{\partial E(x(\theta),p(\theta),\theta)}{\partial \theta} = 0$$
All that is left is to give the solver of our choice an initial guess of the angle and let it run. And now we can find the yoga poses for all participants in the yoga class coached by gingerBread and render an animation if we want.
Figure 4. Manipulation of handles with Automatic Skinning using Mixed FEM. (Credit: Hongcheng Song)
Take away home: next time you go to Yoga class do not forget your Adjoint Method 🙂
1.3 Apply Adjoint Method to High Resolution Mesh
Even though the adjoint method is able to accelerate the optimization process of angles by analytical gradient, it is still an extremely expensive process to use for high resolution meshes. Therefore, we use average biharmonic weights and optimized angles of blue noise sample points to approximate the final result. This approximation propagates those optimal solutions to all triangles by introducing biharmonic weights, allowing a smooth angle interpolation across the surface and reducing enormous calculation expenses required for optimizing all triangles.
Where \(f\) is the number of triangle faces, \(h\) is the number of sample points. \(W_{i, j}\) is the biharmonic weights of a triangle with respect to each sample point, and \(\theta_j\) is the optimized solution of sample points.
References (APA style):
Sorkine, O., & Alexa, M. (2007, July). As-rigid-as-possible surface modeling. In Symposium on Geometry processing(Vol. 4, pp. 109-116).
By SGI Fellows Hector Chahuara, Anna Krokhine, and Elshadai Tegegn
During the third week of SGI, under the guidance of Associate Professor Paul Kry, we worked on Revisiting Computational Caustics. The team returned to this project by EPFL, exploring ideas in differentiable rendering and alternative solutions for optimal transport.
The shape of a mirror can be designed such that the reflection of sunlight on the surface forms a desired image on an adjacent wall.
The project’s starting point was designing a simple flat land that isn’t completely flat as a reflective surface. By changing the reflective land’s surface from flat to something that resembles a zigzag, by a little amount each time, we were able to notice it impacts the reflected rays a lot more and disperses them all around the surface.
We first designed the light source with the light rays (color red), and the reflective surface (color green), and the final surface (color light blue) we wanted to project our light rays. Then our simulation began by varying the reflective surface with the function by \(t\); for \(t\) from 0 to 0.005 with 100 line spaces.
\(f(x) = \sin(8x)\cdot t\), for \(x\): -1 to 1.3 with 100 linespaces
Since we multiply the function by \(t=0\) at the first iteration, the reflective surface is a flatland. But as t increases, through every iteration, the reflective becomes more like a \(\sin x\) function, giving us light rays that are spread across the final surface.