By Abraham Kassahun, Dimitry Kachkovski, Hongcheng Song, Shaimaa Monem
Introduction
It has been two weeks of the projects phase in SGI and our team has been working under the guidance of David Levin and Rohan Sawhney on a very interesting approach to solving differential equations using Mixed Finite Element Method.
In the beginning we were looking at how general Finite Element Methods (FEM) are used to solve the 2D Screened Poisson Equation (and later on a 3D one). First and foremost, we need to understand what FEM is. It is a discretization method that allows us to accurately solve differential equations. It allows us to break up a large system into simpler finite parts (in our case – triangles), and to make certain assumptions over these finite elements that help find a feasible solution.
If we look into the very simple case of only one triangle mesh, then given 3 vertices \(v_1, v_2, v_3\) that form this triangle, we attach a value of a function \(u\) at each of them (that is \(u(\textbf{v}_1),u(\textbf{v}_2),u(\textbf{v}_3)\)are known). To get the value of \(u(\textbf{v})\), for a point \(\textbf{v}\) inside the triangle, we can use various ways of interpolating between the 3 given values. Linear interpolations are often very useful for simulation, and we can use for instance barycentric coordinates as a way to interpolate these values.
A variation of the FEM method that we are exploring is called Mixed FEM. Its main idea is the introduction of supplementary independent variables that create additional constraints on the system. Mixed finite element method can precisely solve some very complex PDEs, while the ultimate goal of utilizing it in our project is to provide another more flexible skinning strategy, which automatically tunes deformation parameters to triangles by artist specified controls, while paving the way to an optimized version of the solver via the Adjoint Method.
Screened Poisson Equation

(Credit: Abraham Kassahun Negash)
To understand how mixed FEM works, we first applied it to the heat equation. It turns out that it doesn’t have any advantages when applied to the heat equation, but it was a good pedagogical detour to understand how it works exactly. The heat equation is a type of Poisson equation described as:$$\Delta u = f$$ If solved as is, the resulting equation will not have a unique solution due to the absence of a Dirichlet boundary condition. Instead we modified the equation slightly by including an \(\alpha u\) term which allows the equation to be solved without explicitly giving any boundary conditions in MATLAB. $$\Delta u – \alpha u = f$$ This equation is also called the screened Poisson equation. We can solve for \(u\) by minimizing the following energy. $$E(u) = \frac{1}{2}\int_{\Omega}||\nabla u||^2 \,d\Omega + \frac{1}{2}\int_{\Omega} \alpha ||u||^2 \,d\Omega – \int_{\Omega} fu \,d\Omega$$ Where \(\Omega\) is our domain of interest. We can define \(u\) as a vector of values evaluated at the vertices of a triangle mesh. Then the equation can be discretized by writing \(u\) as the weighted average of vertex values. $$u(x) = \sum_{i=1}^3{\phi_i (x) u_i}$$ Where \(\phi_i (x)\) are the shape functions we use to interpolate \(u\) inside the triangle. We are going to let \(u\) be piecewise linear over our mesh by choosing linear shape functions. Thus the gradient of \(\phi\) is constant inside the triangle. Substituting into \(u\) and performing the integration we get the following expression. $$E(u) = \frac{1}{2}u^T G^T W G u + \frac{1}{2}\alpha u^T M u – u^T M f$$ Where:
- \(G\) is the gradient matrix defined over the mesh
- \(W\) is the weight matrix resulting from integrating \(\nabla u\) over faces
- \(M\) is the mass matrix resulting from integrating functions over vertices
\(G\) is the gradient operator over the mesh and only depends on the vertex positions. The mass and weight matrices can be taken as identity by assuming a uniform mesh of equal triangles. It can be seen that the term with an \(\alpha\) acts the potential energy of a spring penalizing deviation of \(u\) from 0, thus preventing the solution from blowing up. The solution therefore reduces to $$E(u) = \frac{1}{2}u^T G^T G u + \frac{1}{2}\alpha u^T u – u^T f$$
To solve for \(u\) we formulate an optimization problem in a discrete form over some finite cells of a given surface, that is we build a Finite Element system and find the minimizer as follows:
$$u^* = \arg \min_{u}(\frac{1}{2} u^T G^T G u + \frac{1}{2} \alpha u^T u – u^T f)$$
Finally, to minimize the above system with the standard FEM, we must take the derivative of the function w.r.t. \(u\), and since the system is quadratic, setting the result to zero and solving for \(u\) will yield the answer. That is if we define the energy as $$E(u)=\frac{1}{2}u^T G^T G u + \frac{1}{2}\alpha u^T u – u^T f)$$ then we compute the gradient $$\nabla_u{E}=G^T G u + \alpha u – f =0$$ and we get $$G^T G u + \alpha u = f\\
(G^T G + \alpha I)u=f\\
u=(G^T G + \alpha I)^{-1} f$$
This means that the discrete solution can be computed through a linear system solution.
Mixed FEM
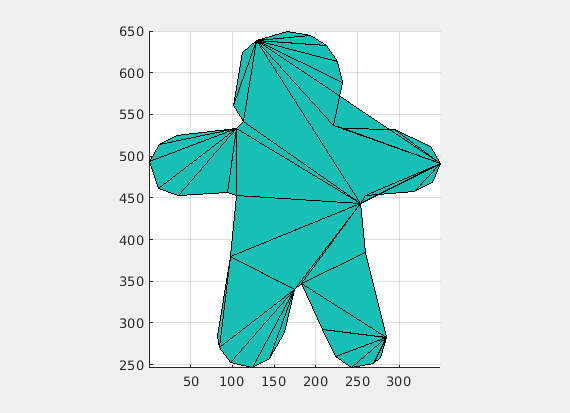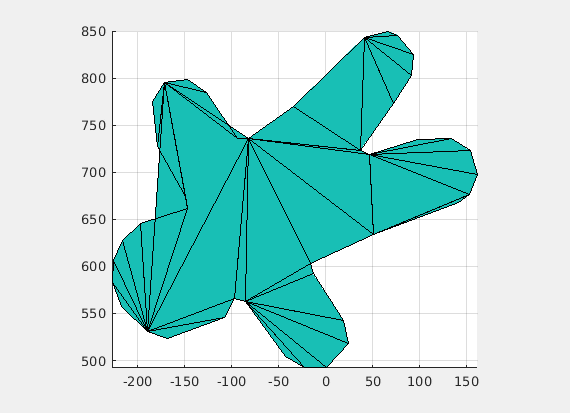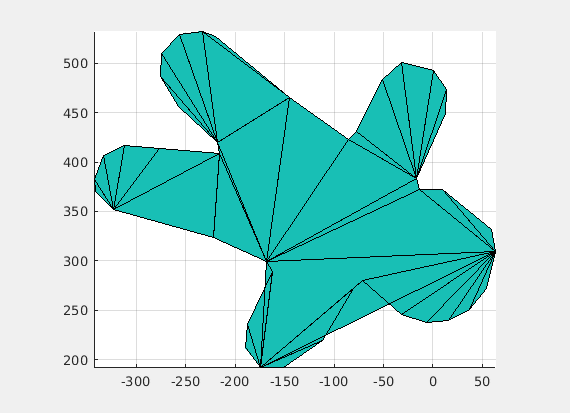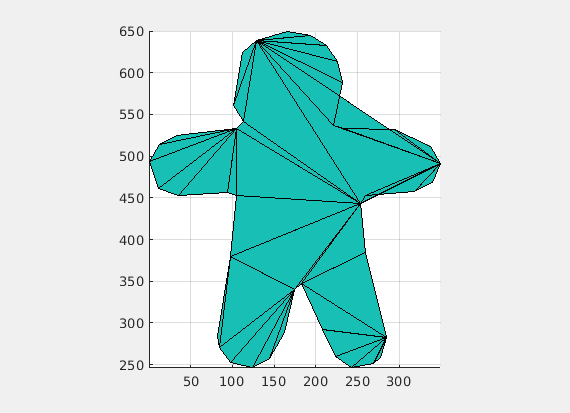
(Credit: Shaimaa Monem)
As mentioned in the introduction, the main idea behind Mixed FEM is to introduce an additional independent variable that we solve for to allow us to optimize the search for the full solution to our system. That is, we will make everything much more complicated so as to make it easier later on! Yay!
We introduce such a variable by taking a part of the original energy equation \(E(u)\), and setting a constraint. That is, we want to reformulate the original minimization as
$$g^*,u^* = \arg \min_{u,g}(\frac{1}{2} g^T g + \frac{1}{2} \alpha u^T u – u^T f)\\
s.t. \ Gu-g=0$$
The idea definitely feels awkward at first. But what we are looking to do is to define \(Gu\) as some variable that is independent of \(u\) itself, but that constrains the system for \(u\). Think of how the search for \(u\) was like turning some dials, and \(Gu\) was another dial that would turn as you try different settings for \(u\). Our goal is to separate that connection so that we can search for both independently, with that search governed by the established rule aka. our constraint.
To solve the newly emergent constrained optimization we use the method of Lagrange Multipliers and formulate our system as:
$$\mathcal{L}{g^*,u^*,\lambda}=\arg \max_{\lambda} \min_{g^*,u^*}E + \lambda^T(Gu-g)\\
\mathcal{L}{g^*,u^*,\lambda}=\arg \max_{\lambda} \min_{g^*,u^*} \frac{1}{2} g^T g + \frac{1}{2} \alpha u^T u – u^T f + \lambda^T(Gu-g)
$$
Now, we just need to take the gradient w.r.t. each of the variables, set them as before to 0, and solve for our 3 variables! That gets us:
$$
\nabla_g=g-\lambda=0\\
\nabla_u=\alpha u – f + G^T \lambda=0\\
\nabla_{\lambda}=Gu-g=0$$
These 3 conditions that we got are known as Karush-Kuhn-Tucker (KKT) conditions. Using them we formulate a larger system that we solve:
$$\begin{bmatrix} I & 0 & -I \\
0 & \alpha I & G^T \\
-I & G & 0 \end{bmatrix} \begin{bmatrix} g\\
x\\
\lambda \end{bmatrix} = \begin{bmatrix} 0\\
f\\
0 \end{bmatrix}$$
Solving this system will give us the solution that we are after.
Now this alone is obviously not a way to speed our solution up. However, the Mixed FEM formulation allows us to combine it with a numerical method known as the Adjoint Method, which in turn will indeed speed up the whole system. It also allows us to leverage certain aspects of deformation energies and their formulations which avoids such heavy handed computations as SVDs.
But before we get there, let’s move away from the toy problem, and consider how our mesh will deform.
As-Rigid-As-Possible (ARAP) Energy
(Credit: Dimitry Kachkovski)
Deformation of elastic objects can be described using various different models. The one we consider is known as the As-Rigid-As-Possible model (Sorkine and Alexa, 2007).
ARAP is a powerful energy term which is invariant to rigid transformations, and it is designed to measure deformation in our system setting clearly, which has the form:
$$E(F) = \| S – I \|_{F}^2$$ Where \(F\) represents the total transformation while \(S\) is a parameter unrelated to rigid transformation, which can be generated from polar decomposition from \(F\) using the relation \(F = RS\), where \(R\) is a rigid transformation. Therefore, energy is only dependent on non-rigid transformation, which has a global minimum at Identity. In this case, \(E(R) = 0\) and \(E(RS) = E(S)\). Instead of finding \(S\) through decomposition every time, what Mixed FEM allows us to do is to let \(S\) be an independent variable and enforce the relation \(F = RS\) with a constraint. Therefore, \(E\) can now be written as:$$E(S) = \| S – I \|_{F}^2$$
Using second-order Taylor expansion, ARAP energy takes the following form:
$$E(S) = \frac{1}{2}S^THS + G^TS$$Where \(H\) and \(G\) are Hessian and gradient matrices, respectively.
Any rigid transformation exerted on triangle mesh will result in zero ARAP energy, but for any non-rigid deformation on triangle mesh, ARAP will clearly generate the corresponding energy. For example, in our gingerBrad man example, we pin down a rotation for a triangle; hence, the only possible situation to keep ARAP energy be zero is forcing all rotations of other triangles to be the same as the pinned one. You can imagine that if one of those triangles does not conform to the same rotation, non-rigid deformation will be generated in that triangle, leading to the growth of ARAP energy. So, ARAP skinning energy is indeed measuring the difference of energy between the current system state and the As-Rigid-As-Possible state with two boundary conditions, and the current state will finally reach the As-Rigid-As-Possible state by the optimizer.
Yoga Performance with Adjoint Method
1.1 Motivation and task formulation
Assuming we have a physics-based animation scene that we would love to visualize, we always start from a the continuous setting, then we choose a discretization scheme that allows us to write a piece of code to simulate our animations, we then pick our favorite programming language and turn the discrete model into a script that our computers can understand and deal with. If we are animating a character, then we would like it to match a specific behavior that is visually appealing, for example a special yoga pose. Well, assuming our character is sportive and flexible, then our simulator might do a good job imitating the desired behavior, if we define flexibility and athletic ability as parameters and feed them to our model. And we can see that in order to achieve successful animation we required three ingredients:
- Discrete model simulating our object’s animations,
- Target behavior for the object,
- Input parameters tuning the object’s properties.
Sounds simple enough! But it implies that we need to know everything beforehand, which is not the case with movie character animation. We might know our target behavior but we do not know the parameters values that take us to this specified behavior, for instance how do we tune flexibility for gingerBrad so that it can do yoga without breaking?
We can express this yoga pose as a desired deformation through a deformation energy which happens to be the well known and previously mentioned ARAP energy. Therefore, we can basically translate this into an optimization task to find, for instance, the threshold \(p^{\star}\) of the flexibility parameter that is enough to reach the yoga pose,
$$p^{\star} = \arg \min_{p} \ E_{ARAP}(p)$$
If you have been to a yoga class, then you have heard your instructor say – “Keep your toes forward and your heels down to the floor, straight back…” – and so on! Well, this is one of the powers that comes with using skinning technique: we can easily pin gingerBrad’s feet to the ground using handles, as follows:
$$p^{\star} , x^{\star} = \arg \min_{p,x} \ E_{ARAP}(p) + \frac{k}{2} \| P x – x_{pinned} \|^2 $$
This means that we can optimize not only over \(p\) but also over all vertex positions \(x\) of the gingerBrad mesh, and we get \(x^{\star}\) the optimal position that is as close as possible to the pose we want, with heals \(x_{pinned}\) pinned to the ground. In the equation above \(P\) is a pinning matrix that selects from \(x\) only the verts to which we assign boundary conditions (here simply pinning!).
So far so good. Now let us imagine a more complex scenario where it is hard to exactly define what that target pose would look like. To picture this situation, let us assume that the gingerBrad character actually got a job as a yoga instructor, and now many characters are standing behind copying the yoga moves! Well, realistic experience tells us that they will not all reach the same exact final yoga pose, as they have different body properties reflected through a wide range of flexibility parameter values, and for the sake of our health and sanity we want to avoid solving a separate problem for each participant, especially if gingerBrad is a very beloved famous coach and his class is always full :-)
We know that we want all of them to go as close as they could to a specific yoga pose, so let us assume, for simplicity, that we want them to rotate their bodies while still standing on the ground We can represent this very special yoga pose with a rotation matrix \(R\). But we can clearly see that the way this rotation task goes for each of them depends on their shapes, i.e. positions \(x\), and properties, or, as we call it, parameters \(p\), which in turn depend on the assigned rotation, meaning we have \(x(R)\) and \(p(R)\).
To find the rotation that each of them can achieve, we must formulate another optimization task:
$$ R^{\star} = \arg \min_{R} \ E_{ARAP}(p) + \frac{k}{2} \| P x – x_{pinned} \|^2 + \| R – R_{pinned} \|^2$$
Where \(R_{pinned}\) makes sure that our animated characters perform rotation around their pinned vertices, for consistency.
Now arises a huge EXISTENTIAL QUESTION, if \(R\) depends on\(p\) and \(x\) which in return are functions of \(R\), how can we compute any of them??
1.2 Apply Adjoint Method
Well basically the adjoint method is the solution to this problem, and we will go through this step by step.
- First, remember that finding \(R^{\star}\) is our ultimate goal, as we want to visualize the yoga poses for all our animated characters and visualize how they perform. We ask ourselves, what do we need to solve the second optimization to compute \(R^{\star}\)? And the simple answer is that we need to find the critical points to the gradient $$E(R)= E_{ARAP}(p)+ \frac{k}{2} \| P x – x_{pinned} \|^2 + \| R – R_{pinned} \|^2\\
\frac{d E(R)}{d R} = \frac{\partial x}{\partial R} \frac{\partial E(R)}{\partial x} + \frac{\partial p}{\partial R} \frac{\partial E(R)}{\partial p} + \frac{\partial E(R)}{\partial R} = 0$$ While computing this gradient requires \(\frac{\partial x}{\partial R}\) and \(\frac{\partial p}{\partial R}\) as \(x\) and \(p\) are functions of \(R\).
- Second, we can actually exploit the first optimization problem to compute \(\frac{\partial x}{\partial R}\) and \(\frac{\partial p}{\partial R} \).
Let’s perform the steps for a special parameter and explain more. We want \(p\) to relate to the deformation \(F\) which expresses the deformed state. We can specifically use the polar decomposition and write \(F\) as a decomposition of a rotation matrix \(R\) and a symmetric matrix \(S\), i.e. \(F = R S\). Remember that we are optimizing \(R\), therefore we are left with \(S\) to pick as our parameter. Moreover, we can find a linear operator called deformation gradient \(B\) that represents this deformation and basically takes our character from its rest reference pose to the deformed yoga performance pose. This gives us a constraint \( B x = RS\) which leads to the following constrained optimization problem
$$ S^{\star} , x^{\star} = \arg \min_{S,x} \ E_{ARAP}(S) + \frac{k}{2} \| P x – x_{pinned} \|^2 $$
Such that \( B x = R S\) (note: I am skipping technical details for simplicity!)
Now the latest constrained optimization task can be happily solved through a Lagrangian energy, actually arising from a mixed FEM problem as explained previously.
$$L(S, x, \lambda) = E_{ARAP}(S) + \frac{k}{2} \| P x – x_{pinned} \|^2 + \lambda (Bx – RS)$$
And like we saw in the very beginning of the report we proceed with computing the gradients of \(L(S, x, \lambda)\) w.r.t. its three different variables and formulate a linear system to solve
$$\nabla_S L = HS + g^T – R^T \lambda = 0\\
\nabla_x L = \frac{k}{2} P^TP + B^T \lambda = 0\\
\nabla_{\lambda} L = B x- R S = 0$$
We rewrite this as \(A y = b \) , where \(A\) is the KKT matrix and \(y = (S^{\star}, x^{\star} , \lambda)^T\) is the solution for our first optimization problem.
- Third, we can extract \(S^{\star}\) and \(x^{\star}\) from \(y\) and fix them in \(E(R)\), which leads to
$$E(R)= E_{ARAP}(S^{\star})+ \frac{k}{2} \| P x^{\star} – x_{pinned} \|^2 + \| R – R_{pinned} \|^2$$
- Fourth, now we can see that, actually, the derivatives that we require are \(\frac{\partial x^{\star}}{\partial R}\) and \(\frac{\partial S^{\star}}{\partial R}\) , which can be computed by differentiating \(y\) , i.e. \(\frac{\partial y}{\partial R} = (\frac{\partial S^{\star}}{\partial R} , \frac{\partial x^{\star}}{\partial R} , 0)^T\), given by
$$\frac{\partial y}{\partial R} = \frac{\partial A^{-1}}{\partial R} \ b\\
\frac{\partial y}{\partial R} = – A^{-1 } \ \frac{\partial A}{\partial R} A^{-1 } \ b$$ - Finally, now that we have \(\frac{\partial x^{\star}}{\partial R}\) and \(\frac{\partial S^{\star}}{\partial R}\), we can basically substitute them into the energy derivative \(\frac{d E(R)}{d R}\) and find \(R\) as the critical point, Woooh!
One more important aspect that we need to take care of is to make sure that \(R\) stays still as a rotation matrix along the optimization task, for this reason, we explicitly write \(R\) as an orthogonal 2D matrix $$R(\theta) = \begin{bmatrix} cos \theta & sin \theta \\
– sin \theta & cos \theta \end{bmatrix} $$ And express our energy in terms of \(\theta\) instead, as follows $$\frac{d E(\theta)}{d \theta} = \frac{\partial x}{\partial \theta} \frac{\partial E(x(\theta),p(\theta),\theta)}{\partial x} + \frac{\partial p}{\partial \theta} \frac{\partial E(x(\theta),p(\theta),\theta)}{\partial p} + \frac{\partial E(x(\theta),p(\theta),\theta)}{\partial \theta} = 0$$
All that is left is to give the solver of our choice an initial guess of the angle and let it run. And now we can find the yoga poses for all participants in the yoga class coached by gingerBread and render an animation if we want.
(Credit: Hongcheng Song)
Take away home: next time you go to Yoga class do not forget your Adjoint Method 🙂
1.3 Apply Adjoint Method to High Resolution Mesh
Even though the adjoint method is able to accelerate the optimization process of angles by analytical gradient, it is still an extremely expensive process to use for high resolution meshes. Therefore, we use average biharmonic weights and optimized angles of blue noise sample points to approximate the final result. This approximation propagates those optimal solutions to all triangles by introducing biharmonic weights, allowing a smooth angle interpolation across the surface and reducing enormous calculation expenses required for optimizing all triangles.
$$\theta^* = \sum_{i=1}^{f} \sum_{j=1}^{h} W_{i, j} \theta_j$$
Where \(f\) is the number of triangle faces, \(h\) is the number of sample points. \(W_{i, j}\) is the biharmonic weights of a triangle with respect to each sample point, and \(\theta_j\) is the optimized solution of sample points.
References (APA style):
Sorkine, O., & Alexa, M. (2007, July). As-rigid-as-possible surface modeling. In Symposium on Geometry processing(Vol. 4, pp. 109-116).