The SGI research program has been structured in a novel way in which each project lasts for one or two weeks only. This gives Fellows the opportunity to work with multiple mentors and in different areas of Geometry Processing. A lot of SGI fellows, including me, had wondered how we would be able to finish the projects in such a short period of time. After two weeks, as I pause my first research project at SGI, I am reminded of Professor Solomon’s remark that a surprising amount of work can be done within 1/2 weeks when guided by an expert mentor.
In this post, I have shared the work I have done under the mentorship of Prof. David Levin over the last two weeks.
Optimal Interlocking Parts via Implicit Shape Optimizations
In this project, we explored how to automatically design jigsaw puzzles such that all puzzle pieces are as close to a given input shape \(I\) as possible, while still satisfying the requirement of interlocking.
Lloyd relaxation with Shape Matching metric
As the first step, we needed a rough division of the domain into regions corresponding to puzzle pieces. For this initial division we used Lloyd’s relaxation as it ensured that the pieces would interlock. To create regions similar to the input shape, we employed a new distance metric. This metric is based on shape matching.
Shape Matching metric:
The input shape \(I\) is represented as a collection of points \(V\) on its boundary and is assumed to be of unit size and centered at the origin. Consider a pixel \(p\) and a site \(x\). First the input shape is translated to \(x\) ( \(V \rightarrow V’\)). The value of scaling factor \(s\) that minimizes the distance between \(p\) and the closest point \(V’_i\) on the boundary of the input shape gives us the shape matching metric. \[s^* = \text{arg min} \frac {1} {2}(dist(p, sV’))\]
Results of Lloyd’s relaxation with shape matching in a 16X16 domain for Input Shapes: Square and a Puzzle piece respectively.
Pre computing maps
The straightforward implementation for Lloyd’s relaxation that I had been using was iterative and therefore very slow. In fact, testing the algorithm for larger domains or complicated shapes that needed dense sampling of boundary points was infeasible. Therefore, optimizing the algorithm was an immediate requirement. I realized that relative to the site \(x\), the distances would vary around it in exactly the same way. So, computing the distance between each pixel and each site separately during each iteration of Lloyd’s relaxation was redundant and could be avoided by pre-computing a distance map for the given object before starting Lloyd’s relaxation.
200×200 maps for square input shape and puzzle piece. The input shape has been scaled and overlaid on top of the map for clarity.
Enhancing the shape matching metric
In addition to speeding up the algorithm, the distance maps also helped in determining the next step. As can be seen from the figures above, the maps weren’t smooth. These jumps in distance fields occurred because the shape matching metric worked on a set of discrete points. Optimizing the scaling factor for minimizing distance to the closest edge instead of closest point resolved this.
200×200 Map with enhanced Shape Matching metric input shape of a puzzle piece.
Shaping the puzzle pieces (In progress)
The initial regions are obtained from Lloyd’s algorithm with the shape matching metric need to be refined so that the final puzzle pieces are highly similar to the input shape \(I\).
I am currently exploring the use of point set registration methods to find the best transformations on the input shape so that it fits the initial regions. These transformations could then be used to inform the next iteration of Lloyd’s algorithm to refine the regions. This process can be repeated until the region stops changing, giving us our final puzzle pieces.
I have thoroughly enjoyed working on this project, and I am looking forward to the next project I would be working on!
What does it mean for a shape to be complex? We can imagine two shapes and decide which seems to be more complex, but is our perception based on concrete measures? The goal of this project is to develop a rigorous and comprehensive mathematical foundation for shape complexity. Our mentor Kathryn Leonard has conducted previous work on this topic, categorizing and analyzing different complexity measures. The categories include Skeleton Features, Moment Features, Coverage Features, Boundary Features, and Global Features. This week we focused primarily on two complexity measures from the Boundary Features. We tested these measures on an established database of shapes as well as producing some shapes of our own to see which aspects of complexity they measure and if they match our intuition.
Measures
Boundary
The first measure of complexity we considered was related to the boundary of the figure. To understand the measure, we first need to understand down-sampling. This is the process of lowering the number of vertices used to create the shape, and using a linear approximation to re-create the boundary. A total of five iterations were performed for each figure, typically leading to a largely convex shape.
Downsampled image with 500, 100, 50, 25, and 8 vertices.
The measure we considered was the ratio between the length of the downsampled boundary and that of the original boundary. In theory, downsampling would significantly change the boundary length of a complex shape. Thus, ratio values close to 0 are considered complex and values close to 1 are considered simple (that is, the downsampled length closely matches the original).
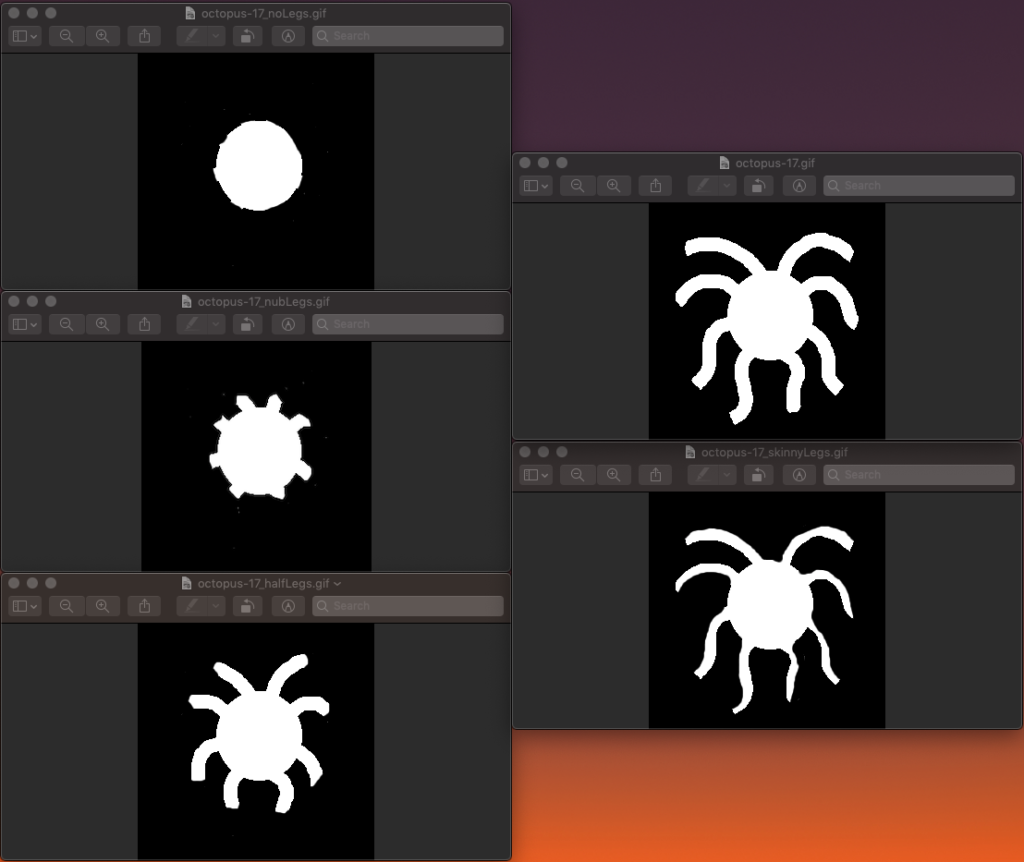
The boundary measure was tested on images which had been hand-edited to create a clear progression of complexity.
For example, the boundary measure created a ranking that nearly matched our intuition, besides switching the regular octopus and the octopus with skinny legs. For all other hand-edited progressions, the boundary measure exactly matched our intuition.
See Appendix 3 in the attached spreadsheet for the full boundary data.
Curvature
The second measure of complexity we considered was curvature. We calculate a normalized, ten bin histogram of the distribution of curvature values at each point of the shape boundary for a given shape and rank the complexity based on the value of the first bin, which was shown in user studies to be highly correlated with user rankings. Higher numbers generated from this measure indicate greater complexity.
One thing this measure emphasizes is sharp corners. At these points the curvature is very high, having a large impact on the overall value.
0.040800
0.042084
0.048096
Adding sharp bends increases complexity as measured by curvature
User Ranking
To see how these measurements compared to our conception of complexity, we looked at previously created images and ranked them as a group according to our notion of complexity. One such subset of images was a group of eight unrelated figures, shown below.
We then used the two measures to create an automated ranking.
The octopus had the lowest boundary length value, and thus the highest complexity ranking according to this measure. Much of the original figure’s perimeter is contained in the tentacles, which are smoothed out during the downsampling. This leads to a large difference in boundary lengths, meaning a more complex ranking.
As previously mentioned, the curvature measure emphasizes sharp corners. This is why the curvature measure ranks the stingray and flower higher than the boundary measure does.
To evaluate how well the resulting ranking matched with our own ordering, we used three similarity measures shown below.
Measure
Similarity Value
Avg. Distance
Normalized Dist
Boundary Length
0.3750
1.00
0.12500
Curvature
0.2500
0.75
0.09375
The first measure we used to compare the user and automated rankings was the ratio of the number of images with matching rank to the total number of images. We called this ratio the similarity value. For example, the user rankings and curvature rankings both placed ‘lizzard-9’ at #1 and ‘Glas-9’ at #6. Thus, the similarity value for the curvature measure was 2/8, or 0.25.
The second similarity measure we used was the average distance, the ratio of the sum of the differences in rank number for each image to the total number of images. This was included to consider how much the ranking of each image differed.
The third similarity measure was the normalized distance, the ratio of the average distance to the total number of images. This was included to account for differences in sample sizes.
The rankings of the group of eight images did differ from our ordering, but on average each shape was off by less than one rank.
Camel & Cattle
Now that we better understand each measurement, we tested them on a database of thirty-eight images of camels and cattle. As in the first example, we ranked the images in order of perceived complexity, and then generated an ordering from the boundary length and curvature measures.
Measure
Similarity Value
Avg. Distance
Normalized Dist
Boundary Length
0
10.31578
0.27146
Curvature
0.02631
8.68421
0.22853
This ranking was less accurate, but still had a clear similarity. We did see however similar groups of values in the boundary length, and ties within the curvature and to deal with this we ran k-mediods clustering on these bins of measures individually.
See Appendix 1 for the full data on the Camel-Cattle Rankings
K-mediods clustering is an algorithm that puts into groups or clusters pieces of data, in an attempt to minimize the distance (in this case Euclidean distance) between the points within each cluster to minimize the total of Euclidean distances summed over the distance within each cluster. For the curvature measure we got the following clusters. (Note that the boundary length and curvature measures ignore any ‘noise’ within the boundary of the image. Thus, the spots on the cows were not considered.)
This showing what the curvature measure considers the most similar shapes, and for the boundary length measure getting the following clusters:
In order to see how well the two measures did in combination, we used both quantities in a clustering algorithm to produce groupings of similar images. The resulting clusters grouped simple shapes with simple shapes, and more complex shapes with more complex shapes.
See Appendix 2 in the attached spreadsheet for the full clusters as well as their distances on the Camel-Cattle.
Polylines
To test our measures on a clear progression of complexity, we decided to make our own shapes. Using a Catmull-Rom interpolation of a set of random points (thanks day 3 of tutorial week!), we produced a large data set of smooth shapes. Generally, intuition says that the more points used in the interpolation, the more complex the resulting shape. Our measures both reflected that pattern.
N = 5
N = 10
N = 15
N = 25
C: 0.022044 B: 1.0044
C: 0.034068 B: 0.98265
C: 0.066132 B: 0.93492
C: 0.08016 B: 0.91145
See Appendix 4 in the attached spreadsheet for the full ranking data of the measures on the Polylines.
We calculated these measures on our database of over 150 shapes, each generated from five, ten, fifteen, or twenty-five points. Using these results, a clustering algorithm was able to roughly distinguish between these four groups. It groups 98.0% of the fives together, 78.7% of tens, 62.5% of fifteens, and 85.2% of twenty-fives. We also note that both complexity measures identify these shapes as much simpler than the other shapes in our database, even with the higher point orders. This is likely because of how smooth the lines are. This reveals an opportunity for future improvement in these measures, since intuition would rank a simple shape from the database (like the horseshoe) as simpler than the figure in the N = 25 column above.
See Appendix 5 in the attached spreadsheet for the clustering data of the polylines.
Noisy Circles
In order to test the measures on a clear progression of complexity that progressed the noise of the shape (small protrusions) rather than large protrusions or changes like in the Polylines we created we created a shape making program that started with a circle, something that both our intuition ad the constructive model of complexity put forth as the simplest shape. We then added noise to the circle by running a pseudo-random walk on each point on the boundary of the circle where we added a point for each step of the walk. The walk went in a random cardinal direction, a random number of steps for each point on the boundary, we then theorized that we would be able to add levels of complexity on average by increasing the number of propagations, eg: the number of times that the circle underwent every point taking a random walk. This has the additional benefit that like the polylines allows us to measure complexity on average levels which would give us a better comparison to see if our measures are reasonable.
To test this we ran eight levels of complexity with ten shapes per level. The shapes as well as what propagation, and thus complexity level each one is is shown in the first figure.
In order to give a partial test to see if our hypothesis that generally the more propagations are run the more complex the shape is we tested it against our human intuition of complexity, and ranked the shapes according to how complex they seemed to human intuition.
Comparing the two we get the following table:
Similarity Percentage
Distance
58.75%
0.425
At first glance looking at the similarity percentage, that is how many of the shapes are placed by human intuition into the same complexity level as the number of perturbations, and we see that only 59% of the shapes are placed into the same level, however, looking at the distance tells us a different story. We see from the small distance value, that our similarity percentage is lower than we would like because swaps between one level and another are rather common which means that the general relation of propagations to complexity is what we desire, thus comparing distance to the original seems to be a promising measure of how accurate the propagations to complexity are. As this distance function implies that on average the complexities are in the correct level and are only moved half a level from the number of propagations done. Thus as our general hypothesis is true that the number of propagations correlates to the complexity we can look at the automatic measure of propagations rather than user intuition for comparing this data to the curvature and boundary measures.
Now that we have seen this let us look at how the curvature measure ranks the shapes. In the bottom left figure:
Similarity Percentage
Distance
0.3%
1.2625
We see from the similarity, that it is less similar to the propagations, than the intuition and thus is less accurate to our intuition than the number of propagations are, however it again does not have a large distance, in fact when taking into account the distance between the the intuition and the propagation we get that the distance range between intuition and the curvature measure ranking is in the range of 0.8375-1.6875, which is not too large of a change, and shows that the curvature measure is a reasonable measure insofar that it gives us the correlation that we are looking for generally, however as we can see looking at the ranking itself in the figure it is not entirely accurate.
See Appendix 6 in the attached spreadsheet for the full ranking data for the not-circles.
We now look at the other main measure that we use the boundary length measure to see the ranking that it produces. In the bottom right figure:
Similarity Percentage
Distance
0.375%
0.8625
From this data we see that in comparison to the curvature we have both a higher similarity and a lower distance. From the low distance we see that in general only small shifts between what levels things should be placed upon occur, confirmed by the difference between the boundary length measure and our intuition being in the range of 0.4375-1.2875, this shows that for looking of noise of this nature that the boundary length measure is better than the curvature measure as it keeps the general relationship and does so with much less error, thus showing a strong reason to use the boundary length measure as a way to classify the complexity of shapes differing in the amount of noise that they have.
See Appendix 6 in the attached spreadsheet for the full ranking data.
Lastly, to see whether or not these levels are somewhat arbitrary and whether there is an even gap between levels, we use k-medoids clustering on eight clusters to see how it is clustered using both the boundary length and curvature measures together. From this we get extremely interesting results, in that they say “No! There are not even gaps” we see this from the range in sizes of the clusters that occur ranging from 1 to 27, thus we see that the propagations do not create even clusters but rather bursts of complexity. This is however to be expected, the levels are simply the number of propagations that occur and we forced the earlier rankings into using the same number on each level, and thus this does not defeat that on average each level has more complexity, we also need to consider that there are some differences due to using these measures for clustering from how human intuition would cluster them. We now from seeing the lowest number of clusters have a strange result, one of the clusters has only one element in it, , and while this presents an initial puzzle after analysis it shows to have a good reason the circle like element by itself is almost a perfect (pixel) circle, thus it is placed by itself as its own level of a “zero” complexity. That many levels of propagations exist within one cluster is also similarly explained to clusters of different sizes, that is when we looked at our previous data small changes in distance were common and thus in clustering instead of small distances, where small shifts occur we instead have them in the same group.
See Appendix 7 in the attached spreadsheet for the full clusters as well as distances of the noisy circles.
Putting it all Together
Lastly we clustered everything in order to get a sense of the various complexities and how our measures would group all of the different main categories of shapes that we looked at, those being the camel-cattle, the polylines and the not circles. We put them into eight clusters in order to attempt to put them into the same category levels of complexity as were arbitrarily created by the not shape propagations. From this we got somewhat unexpected results, those being that while the camel-cattle were grouped together with the not circles, as well as with how their complexities would expect them to be grouped based on earlier clusterings, the polylines were in clusters by themselves. We then have to expand upon this clustering in order to try to explain it. The clusters of camel-cattle as well as not circles were four of the eight clusters, inside of these clusters we had on average the higher number of propagation on not circles grouped together with the camel-cattle that were given higher ranked complexity values, and vise-versa with lower propagation and lower ranked complexity. The other four clusters were the polyline data, and the reason for this is that as we can see the polylines are given by the curvature ad boundary length measures to have much less complexity and as such are in a group, well groups of their own having much less complexity than the camel-cattle as well as the not circles, and thus by our measures they are clustered separately. This is interesting especially as one of our not circles is almost just a perfect (pixel) circle, we then want to somewhat explain why this is more complex than the polylines, and the answer that we see for this is that the polylines are much smoother, while the pixel circle is still made out of these large pixels and thus is much sharper, it is thus left as a somewhat open question if this would be true for larger starting not circles.
See Appendix 8 in the attached spreadsheet for the full clusters as well as the distances of all the shapes.
Conclusion
From our tests and calculations, we conclude that our intuition of shape complexity is measurable, at least according to some respects, we saw that curvature was a good measure of how many sharp edges a shape has, and length was a measure of the noise and somewhat of the protrusions on a shape. The specific measurements of boundary length and curvature both give good estimations of complexity, giving the general relation between our intuitive understanding, while measuring in general different properties of shapes. However, we only did this research for one week and thus it feels necessary to say what would be done to continue on this research, the ways that we would continue the research is in three main facets. Firstly we would like to use more measures other than just the boundary length and curvature measures, in order to both see if there are other more effective general measures of complexity and in order for us to see if other measures are better able in particular at looking at different areas of complexity. From looking at more measures we can also increase what we consider in our k-medoids. The second thing that we would do is to compare and rank more of the shapes based on the intuition of more people, because of the subjective nature of doing this intuitive ranking. This would allow us to better with more data on subjective ranking see how accurate our complexity measurements are. On this same subject the third area we would do more research on would be to increase the number of shapes that we are looking at specifically the number of not circles, and polylines as they are randomly generated and thus only on average increase in complexity and thus with the more shapes we have of them the clearer we would see the differences in complexity between the number of points and the propagations.
Acknowledgements
We would like to express great appreciation for our mentor Kathryn Leonard, who generously devoted time and guidance during this project. We would also like to thank our TA Dena Bazazian, who provided feedback and encouragement throughout the week.
As the whirlpool of the first week of SGI came to an end, I felt that I’d learnt so much and perhaps not enough at the same time. I couldn’t help but wonder: Did I know enough about geometry processing (…or was it just the Laplacian) to actually start doing research the very next week? Nevertheless, I tried to overcome the imposter syndrome and signed up to do a research project.
I joined Professor Marcel Campen’s project on “Improved 2-D Higher Order Meshing” for Week 2. The project focused particularly on higher order triangle meshes, which are characterized by their curved (rather than straight) edges. We studied a previously presented algorithm for the generation of these meshes in 2D, with the goal of improving or generalizing it.
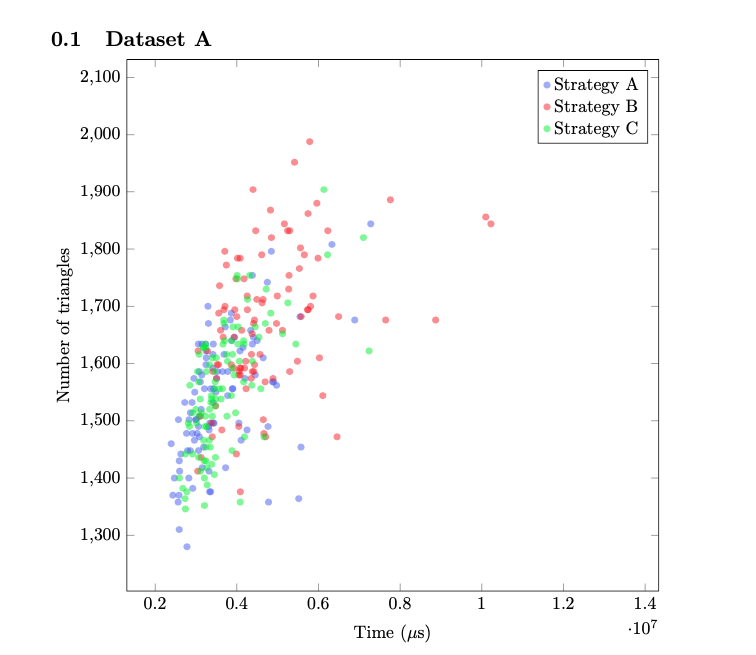
After an initial trial, where we struggled to get the program running on our systems, we discussed potential areas of research with Professor Campen and dived straight into the implementation of our ideas. The part of the algorithm that I worked on was concerned with the process of splitting given Bézier curves (for the purpose of creating a mesh), particularly how to choose the point of bisection, \(t\). During a later stage of the algorithm, the curves are enveloped by quadrilaterals (or two triangles with a curved edge). If two quads intersect, we must split one of the curves. The key idea here was that the quads could then potentially inform how the curves were to be split. Without going into too much technical detail, I essentially tried to implement different approaches to optimize the splitting process. The graph below shows a snippet of my results.
While Strategy A is the original algorithm implementation, Strategy B and C were possible improvements to it. For both of the latter strategies I used an area function to find the point where the resulting quads would have the approximately equal area. This equal distribution could point to an optimal solution. The difference between B and C has to do with how the value of \(t\) is iteratively changed as is shown below.
While I was only able to run the program on a sample size of 100 2D images, basic quantitative analysis pointed towards Strategy A and C as the more optimal choices. However, to get more conclusive results, the strategies need to be tested on more data. In addition to Strategy B and C, another direction for further consideration was to use the corners of the quad to find the projection of the closest corner to the curve.
As the week came to an end, I was sad to leave the project at this somewhat incomplete stage. During the week, I went from nervously reading my first research paper to testing potential improvements to it. It was an exciting week for me and I can’t wait to see what’s next!
That was the tongue-in-cheek remark our TA Peter Rock made at the end of SGI’s last tutorial week session. For me, a fresh CS graduate who always managed to steer clear of the dark abyss where “real math” hides, that remark hit close to home. I think it is fair to say that even for the most math whizzy of us fellows, whether it felt like drinking from a fire hose or a squeeze bottle, the tutorial week left us undeniably very well hydrated.
The week started with Oded Stein’s lecture, an extremely friendly introduction to this new world of geometry processing. For me, it felt like a mixed bag of known concepts, brand new stuff, and some in-between. Maybe because of this, Oded’s lecture was just the introduction I needed to feel like I could do this thing. Surely enough, a few minutes after Oded finished his lecture, pictures of mangled triangle meshes and Gouraud-shaded goats started to flood our Slack. Not only could we do this, we were doing it!
Finally, Prof. Justin Solomon made some remarks at the end of the day that resonated with me so much; I hope I never let myself forget. I do not remember his exact words, but the message was: “math is hard for everyone. There’s no shame in it. Your job is not to understand things right away. Your job is to ask for help until you do.”
What followed the next day was a lecture by Derek Liu, showing how a few lines of math wizardry in MATLAB could perform shape deformations. Things were starting to look like the SIGGRAPH videos I’ve been drooling over for years! As is to be expected, with great wizardry comes great amounts of students asking for help. I was among them. Yet, Derek was so incredibly patient in walking all of us through each mathematical question and their respective MATLAB lines, I left the session actually knowing how to do those things. For someone who loved the videos but never understood a line of the papers, it was a day to remember.
The day continued, then, with Eris Zhang’s lecture, which took Derek’s concepts even further. It was mind-blowing to think a few months ago, a video of Eris’ work was one of those I was drooling over, and now she was there, teaching us the ropes, using excerpts from the video as an example! To me, that is the perfect picture of what an invaluable experience SGI is.
The third day was a very different experience (for me). Silvia Sellán’s lecture brought me a new point of view for things like splines and NURBS, concepts I had previously taught as a TA for semesters on end (albeit years ago). Her approach was very lighthearted and humorous, yet very grounded, making sure everything was accessible and carefully explained. The exercises were equally well thought out. Even so, I eventually needed to ask for help on a more “mathy” task, but Silvia did not give me the answer. Instead, she smoothly guided me through figuring it out for myself, which was amazing! Her closing remarks were: “now make sure you help others who struggle as well.” To me, this way of thinking summarizes the incredible spirit we’ve been having throughout the program.
The day closed with a talk by Shadertoy’s Íñigo Quilez, which first introduced us to rendering using SDFs, then completely opened Pandora’s box. Íñigo’s message was: “you are future researchers, well, here are some things for you to think about.” As honored as I feel by his trust in us, I must say I was too mesmerized by the rendering possibilities to think about how to solve the issues. As someone who used traditional rendering approaches for a long time, the world of SDFs felt like a trip to wonderland for a Mad Hatter’s tea party. A trip I wish to repeat soon! Again the feeling I had on the previous days is repeated: I had been visiting Shadertoy since before college, looking at the walls of code and wondering how they yielded such mesmerizing results. Well, now Íñigo has shown us the way, and the ball is on our court. Amazing.
I could go on for pages talking about the following days, including the incredible first week of research, but I believe this is better suited for a subsequent post. Overall, I can say that I feel extremely fortunate to be a part of this thing, be hand-fed this select knowledge from such experts in the field, and now have such an overview of what paths I can take in my career. SGI is proving to be much more of a game-changer in my life than I could have ever previously imagined. To everyone who made this possible, my sincerest thank you!!
Many of the datasets we would like to perform machine learning on have an intrinsic hierarchical structure. This includes social networks, taxonomies, NLP sentence structure, and anything that can be represented as a tree. While the most common machine learning tools work in the Euclidean space, this space is not optimal for representing hierarchical data.
When representing hierarchical data in the 2D space, we have two main objectives: to preserve the hierarchical relationships between parent and child nodes; and to ensure distances between nodes are somewhat proportional to the number of links in between. However, when representing this structure in the 2D Euclidean space, we run into a few limitations.
Fig 1. A tree with branching factor of 2 drawn in the Euclidean space. (Courtesy of Alison Pouplin)
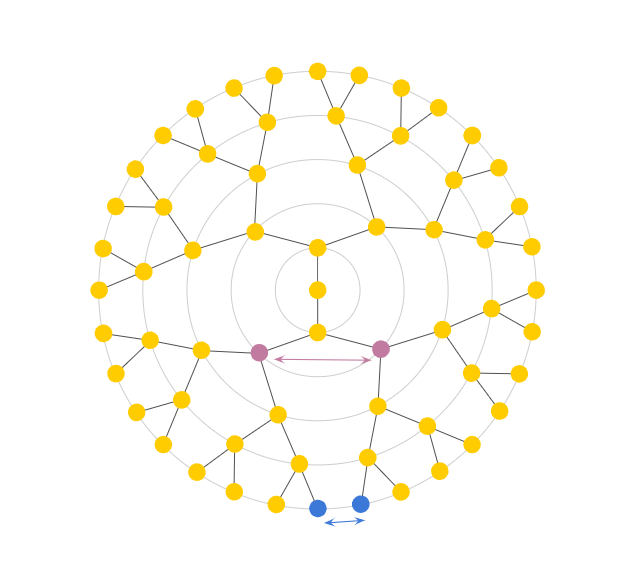
For example, let’s first draw a tree, with a branching factor of 2 (Fig 1). When our tree is very deep, placing nodes equidistantly causes us to run out of space rather quickly, like in our example above at only a depth of 5. The second problem we run into is with untrue distance relationships among nodes. To help visualize this phenomenon, refer to Fig 2a. Here, arc refers to the shortest path between two nodes.
—————————————— –Fig 2a.—————––––——–——————————-–––—–––——————–Fig 2b. Euclidean vs desired measurement of distance between nodes. (Courtesy of Alison Pouplin)
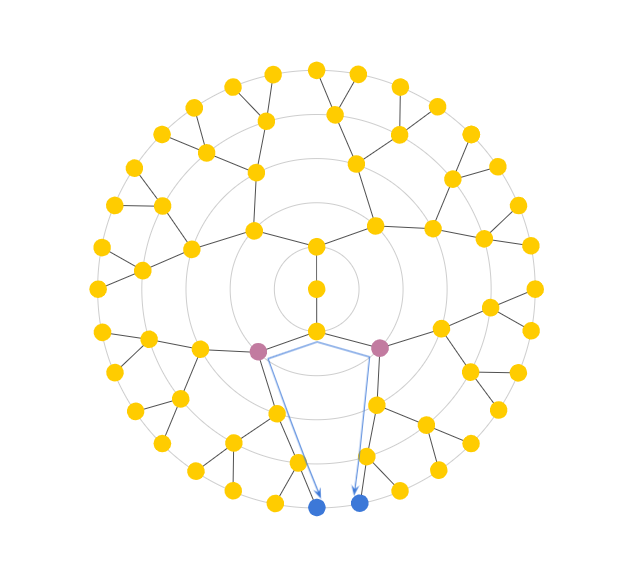
In theory, since the length of the arc between the purple nodes is less than that of the blue nodes, the purple nodes should result in the smaller distance. However, the Euclidean distance between the purple nodes is larger than the distance between the blue nodes. With the Euclidean 2D space, we observe that siblings in later generations end up closer and closer together, rendering Euclidean distance almost meaningless, as it only grows linearly with depth. Instead, we need a better distance measure: one that somehow travels “up” a tree before going back down as shown in Fig 2b and that is analogous to tree distance that grows exponentially as shown in Fig 3.
Fig 3. Desired measurement of distances between nodes. (Courtesy of Alison Pouplin)
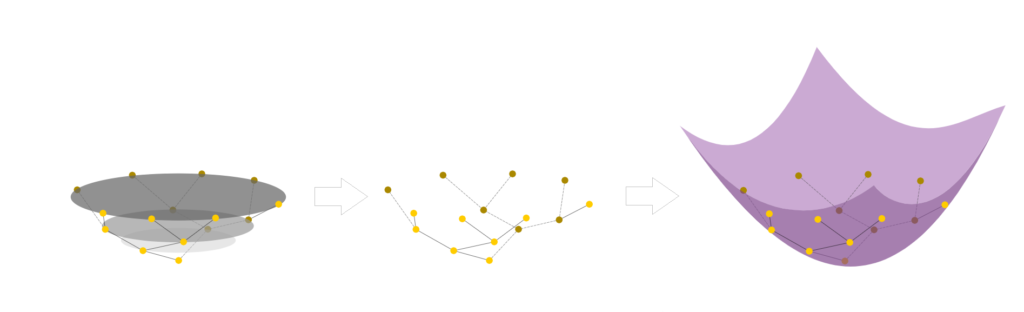
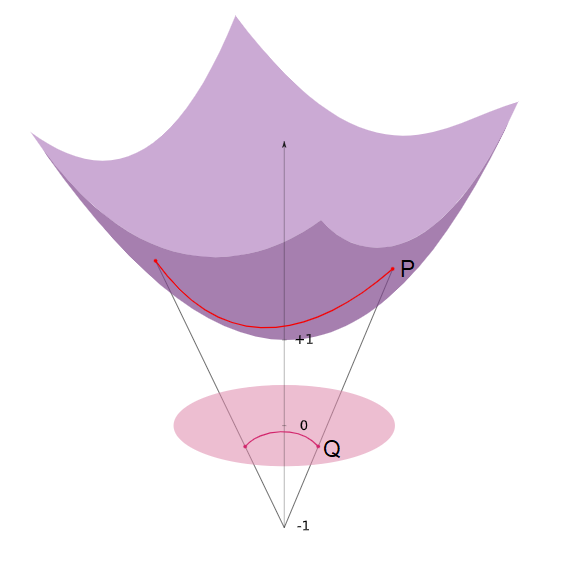
A solution for this is to add an extra dimension (Fig 4). Now, the tree follows a smooth manifold: a hyperboloid. A hyperboloid is a manifold with a negative sectional curvature in the Minkowski space, drawn by rotating a parabola around its symmetrical axis. Note, the Minkowski space is similar to the Euclidean space except dimension 1 is treated differently, while other dimensions are treated similarly to the Euclidean space.
Fig 4. Adding a fourth dimension to hierarchical data. (Courtesy of Alison Pouplin)
Embedding the tree on a smooth manifold now allows us to compute geodesics (shortest distance between two points on a surface). We can also project the data onto a lower dimensional manifold, such as the Poincaré disk model. This model can be derived using a stereoscopic projection of the hyperboloid model onto the unit circle of the z = 0 plane (Fig 5).
Fig 5. Projecting hyperbolic geodesic to Poincaré disk. (Courtesy of Alison Pouplin)
The basic idea of this stereoscopic projection is:
Start with a point P on the hyperboloid we wish to map.
Extend P out to a focal point N = (0,0,−1) to form a line.
Project that line onto the z = 0 plane to find our point Q in the Poincaré model.
The Poincaré disk model is governed by the Möbius gyrovector space in the same way that Euclidean geometry is governed by the common vector space (i.e., we have different rules, properties and metrics that govern this space). While we won’t go into the specifics of what constitutes a gyrovector space, we shall detail the properties of the Poincaré disk that make it advantageous for representing hierarchical data.
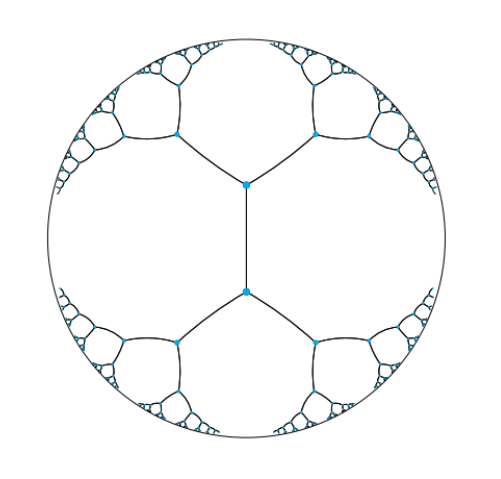
Fig 6. A tree with branching factor of 2 drawn on the Poincaré disk. (Source)
In Fig 6, we can see a hierarchical tree with branching factor two embedding into a Poincaré disk. Distances between all points are actually equal because distances grow exponentially as you move toward the edge of the disk.
Some notable points of this model are the following:
The arcs never reach the circumference of the circle. This is analogous to the geodesic on the hyperboloid extending out to infinity, that is, as the arc approaches the circumference it’s approaching the “infinity” of the plane.
This means distances at the edge of the circle grow exponentially as you move toward the edge of the circle (compared to their Euclidean distances).
Each arc approaches the circumference at a 90 degree angle, this just works out as a result of the math of the hyperboloid and the projection. The straight line in this case is a point that passes through the “bottom” of the hyperboloid at (0,0,1).
With these properties we are able to represent data in a compact, visually pleasing and apt form using hyperbolic geometry. Current research explores how we can harness these properties in order to perform effective machine learning on hierarchical data.