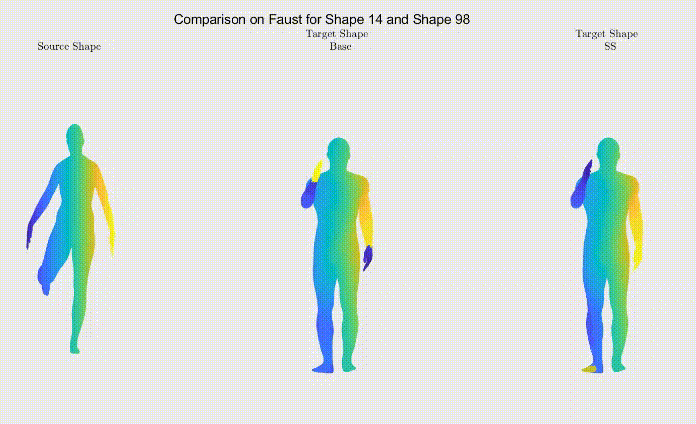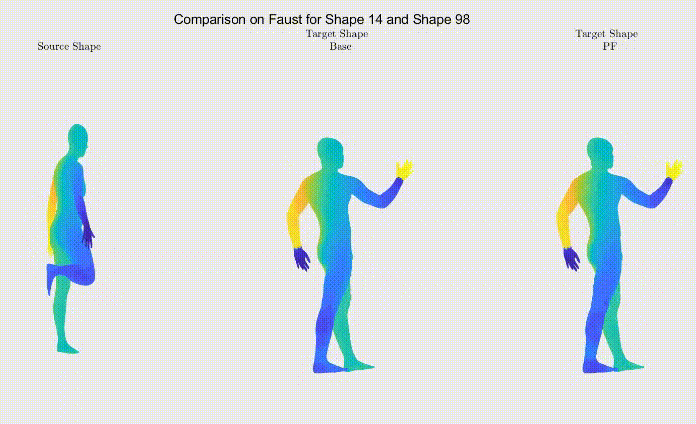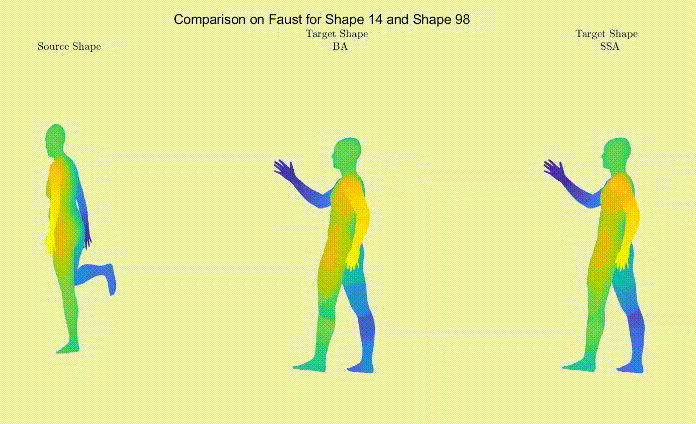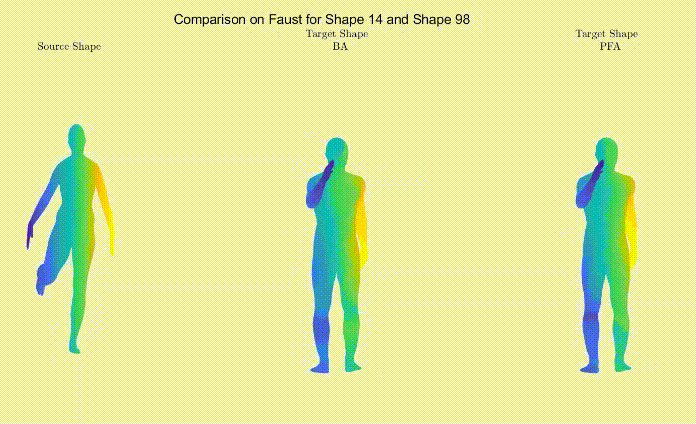During the 4th week of SGI, we worked closely with Dr. Tal Shnitzer to develop an improved loss function for learning functional maps with robustness to symmetric ambiguity. Our project goal was to modify recent weakly-supervised works that generated deep functional maps to make them handle symmetric correspondences better.
Introduction:
Shape correspondence is a task that has various applications in geometry processing, computer graphics, and computer vision – quad mesh transfer, shape interpolation, and object recognition, to name a few. It entails computing a mapping between two objects in a geometric dataset. Several techniques for computing shape correspondence exist – functional maps is one of them.
A functional map is a representation that can map between functions on two shapes’ using their eigenbases or features (or both). Formally, it is the solution to \(\mathrm{arg}\min_{C_{12}}\left\Vert C_{12}F_1-F_2\right\Vert^2\), where \(C_{12}\) is the functional map from shape \(1\) to shape \(2\) and \(F_1\), \(F_2\) are corresponding functions projected onto the eigenbases of the two shapes, respectively.
Therefore, there is no direct mapping between vertices in a functional map. This concise representation facilitates manipulation and enables efficient inference.
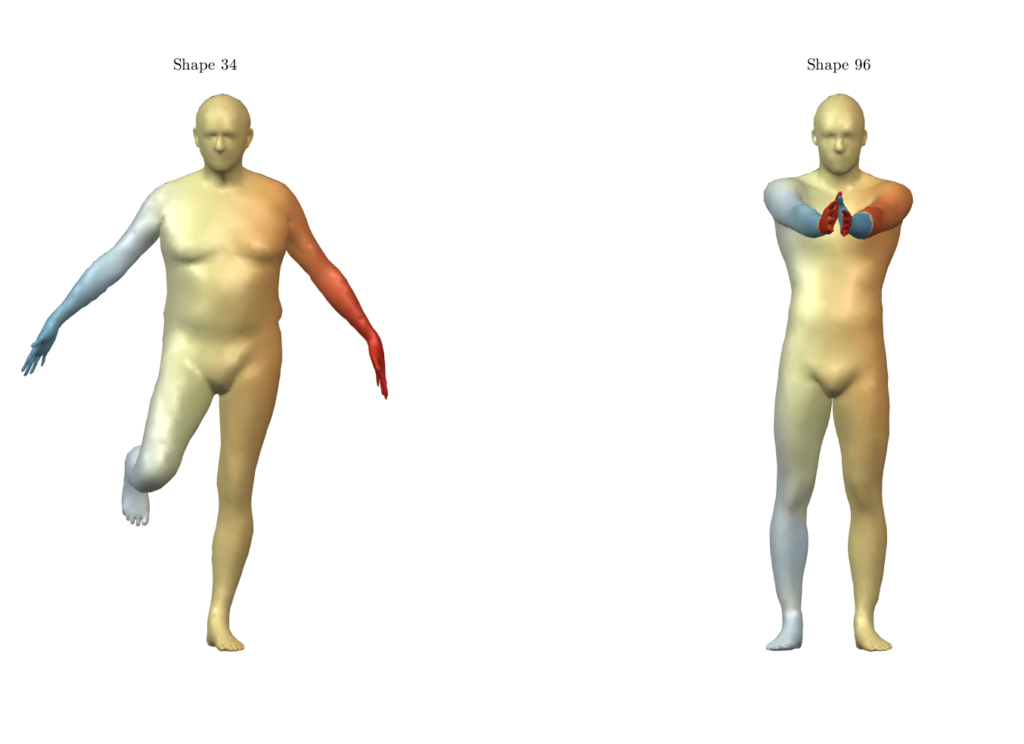
Figure 1: The approach proposed by Sharma and Ovsjanikov may fail on symmetric regions. Notice the hands, which have not been matched correctly due to their symmetric structure.
Recently, unsupervised deep learning methods have been developed for learning functional maps. One of the main challenges in such shape correspondence tasks is learning a map that differentiates between shape regions that are similar (due to symmetry). We worked on tackling this challenge.
Background
We build upon the state-of-the-art work “Weakly Supervised Deep Functional Map for Shape Matching” by Sharma and Ovsjanikov, which learns shape descriptors from raw 3D data using a PointNet++ architecture. The network’s loss function is based on regularization terms that enforce bijectivity, orthogonality, and Laplacian commutativity.
This method is weakly supervised because the input shapes must be equally aligned, i.e., share the same 6DOF pose. This weak supervision is required because PointNet-like feature extractors cannot distinguish between left and right unless the shapes share the same pose.
To mitigate the same-pose requirement, we explored adding another component to the loss function Contextual Loss by Mechrez et al. Contextual Loss is high when the network learns a large number of similar features. Otherwise, it is low. This characteristic promotes the learning of global features and can, therefore, work on non-aligned data.
Work
Model architecture overview: As stated above, our basic model architecture is similar to “Weakly Supervised Deep Functional Map for Shape Matching” by Sharma and Ovsjanikov. We use the basic PointNet++ architecture and pass its output through a \(4\)-layer ResNet model. We use the output from ResNet as shape features to compute the functional map. We randomly select \(4000\) vertices and pass them as input to our PointNet++ architecture.
Data augmentation: We randomly rotated the shapes of the input dataset around the “up” axis (in our case, the \(y\) coordinate). Our motivation for introducing data augmentation is to make the learning more robust and less dependent on the data orientation.
Contextual loss: We explored two ways of adding contextual loss as a component:
Self-similarity: Consider a pair of input shapes (\(S_1\), \(S_2\)) of features \(P_1\) with \(P_2\) respectively. We compute our loss function as follows: \(L_{CX}(S_1, S_2) = -log(CX(P_1, P_1)) – log(CX(P_2, P_2))\), where \(CX(x, y)\) is the contextual similarity between every element of \(x\) and every element of \(y\), considering the context of all features in \(y\). More intuitively, the contextual loss is applied on each shape feature with itself (\(P_1\) with \(P_1\) and \(P_2\) with \(P_2\)), thus giving us a measure of ‘self-similarity’ in a weakly-supervised way. This measure will help the network learn unique and better descriptors for each shape, thus alleviating errors from symmetric ambiguities.
Projected features: We also explored another method for employing the contextual loss. First, we project the basis \(B_1\) of \(S_1\) onto \(S_2\), so that \(B_{12} = B_ 1 \cdot C_{12}\). Similarly, \(B_{21} = B_2 \cdot C_{21}\). Note that the initial bases \(B_1\) and \(B_2\) are computed directly from the input shapes. Next, we want the projection \(B_{12}\) to get closer to \(B_2\) (the same applies for \(B_{21}\) and \(B_1\)). Hence, our loss function becomes: \(L_{CX}(S_1, S_2) = -log(CX(B_{21}, B_1)) – log(CX(B_{12}, B_2))\). Our motivation for applying this loss function is to reduce symmetry error by encouraging our model to map the eigenbases using \(C_{12}\) and \(C_{21}\) more accurately.
Geodesic error: For evaluating our work, we use the metric of average geodesic error between the vertex-pair mappings predicted by our models and the ground truth vertex-pair indices provided with the dataset.
Result
We trained six different models on the FAUST dataset (which contains \(10\) human shapes at the same \(10\) poses each). Our training set includes \(81\) samples, leaving out one full shape (all of its \(10\) poses) and one full pose (so the network never sees any shape doing that pose). These remaining \(19\) inputs are the test set. Additionally, during testing we used ZoomOut by Melzi et al.
Model
Data Augmentation
Contextual Loss
Base
False
None
BA
True
None
SS
False
Self Similarity
SSA
True
Self Similarity
PF
False
Projected Features
PFA
True
Projected Features
Table 1: We trained 7 models using the settings described in this table
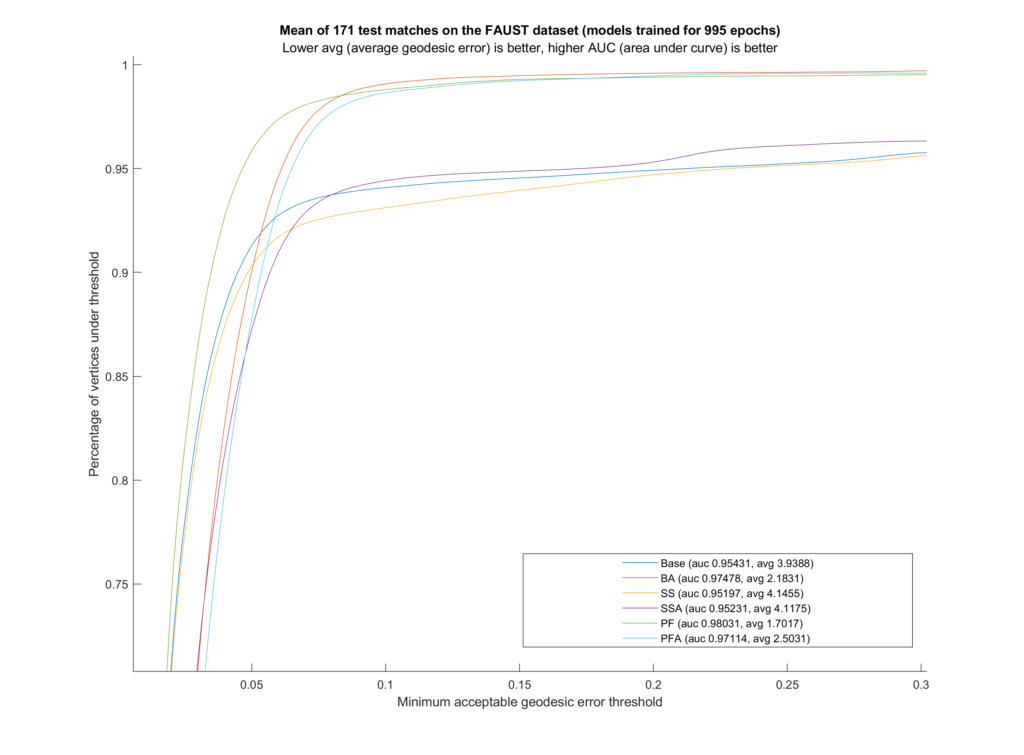
Figure 2: The AUC (area under curve) curves and values with the average geodesic error for each model.
For qualitative comparison purposes, the following GIF displays a mapping result. Overall, the main noticeable visual differences between our work and the one we based ourselves on appeared when dealing with symmetric body parts (e.g., hands and feet).
Figure 3: Comparison between shape correspondence produced by the models described in Table 1.
Still, as it can be seen, the symmetric body parts remain the less accurate mappings in our work too, meaning there’s still much to improve.
Conclusion
We thoroughly enjoyed working on this project during SGI and are looking forward to investigating this problem further, to which end we will continue to work on this project after the program. We want to extend our deepest gratitude to our mentor, Dr. Tal Shnitzer, for her continuous guidance and patience. None of this would be possible without her.
Thank you for taking the time to read this post. If there are any questions or suggestions, we’re eager to hear them!
Over the first 2 weeks of SGI (July 26 – August 6, 2021), we have been working on the “Probabilistic Correspondence Synchronization using Functional Maps” project under the supervision of Nina Miolane and Tolga Birdal with TA Dena Bazazian. In this blog, we motivate and formulate our research questions and present our first results.
Finding a meaningful correspondence between two or more shapes is one of the most fundamental shape analysis tasks. Van Kaick et al (2010) stated the problem as follows: given input shapes \(S_1, S_2,…, S_N\), find a meaningful relation (or mapping) between their elements. Shape correspondence is a crucial building block of many computer vision and biomedical imaging algorithms, ranging from texture transfer in computer graphics to segmentation of anatomical structures in computational medicine. In the literature, shape correspondence has been also referred to as shape matching, shape registration, and shape alignment.
In this project, we consider a dataset of 3D shapes and represent the correspondence between any two shapes using the concept of “functional maps” [see section 1]. We then show how the technique of “synchronization” [see section 2] allows us to improve our computations of shape correspondences, i.e., allows us to refine some initial estimates of functional maps. During this project, we implement a method of synchronization using tools from geometric statistics and optimization on a Riemannian manifold describing functional maps, the Stiefel manifold, using the packages geomstats and pymanopt.
1. Representing Shape Correspondences with Functional Maps
Shape correspondence is a well-studied problem that applies to both rigid and non-rigid matching. In the rigid scenario, the transformation between two given 3D shapes can be described by a 3D rotation and a 3D translation. If there is a non-rigid transformation between the two 3D shapes, we can use point-to-point correspondences to model the shape matching. However, as mentioned in Ovsjanikov et al (2012), many practical situations make it either impossible or unnecessary to establish point-to-point correspondences between a pair of shapes, because of inherent shape ambiguities or because the user may only be interested in approximate alignment. To tackle that problem, functional maps are introduced in Ovsjanikov et al (2012) and can be considered a generalization of point-to-point correspondences.
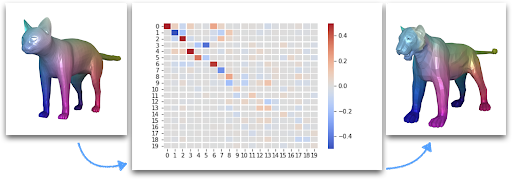
By definition, a functional map between two shapes is a map between functions defined on these shapes. A function defined on a shape assigns a value to each point of the shape and can be represented as a heatmap on the shape; see Figure 2 for functions defined on a cat and a tiger respectively. Then, the functional map of Figure 2 maps the function defined on the first shape — the cat — to a function on the second shape — the tiger. All in all, instead of computing correspondences between points on the shapes, functional maps compute mappings between functions defined on the shapes.
In practice, the functional map is represented by a \(p \times q\) matrix, called C. Specifically, we consider p basis functions defined on the source shape (e.g. the cat) and q basis functions defined on the target shape (e.g. the tiger). Typically, we can consider the eigenfunctions of the Laplace-Beltrami operator. The functional map C then represents how each of the p basis functions of the source shape is mapped onto the set of q basis functions of the target shape.
Figure 2: Functional map mapping a function defined on a cat (“source shape”) to a function defined on a tiger (“target shape”). The functional map is represented by a matrix that describes how each of the 20 basis functions chosen on the source shape is mapped onto the set of 20 basis functions chosen on the target shape. (generated using PyFM)
2. Problem Formulation: Synchronization Improves Shape Correspondences
In this section, we describe the technique of “synchronization” that allows us to improve the computations of functional maps between shapes, and we introduce the related notations. We use subsets of the TOSCA dataset (http://tosca.cs.technion.ac.il/book/resources_data.html), which contains a dataset of 3D shapes of cats, to illustrate the concepts.
Intuitively, the method of synchronization builds a graph that links pairs of 3D shapes within the input dataset by edges representing their functional maps; see Figure 3 for an example of such a graph with 4 shapes and 6 edges. The method of synchronization then leverages the property of cycle consistency within the graph. Cycle consistency is a concept that enforces a global agreement among the shape matchings in the graph, by distributing and minimizing the errors to the entire graph — so that not only pairwise relationships are modeled but also global ones. This is why, intuitively, synchronization allows us to refine the functional maps between pairs of shapes by extracting global information over the entire shape dataset.
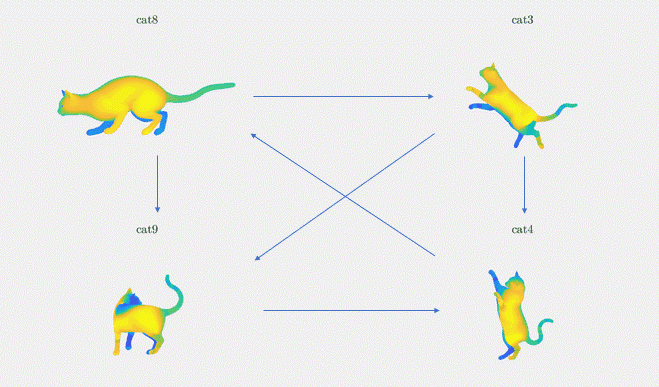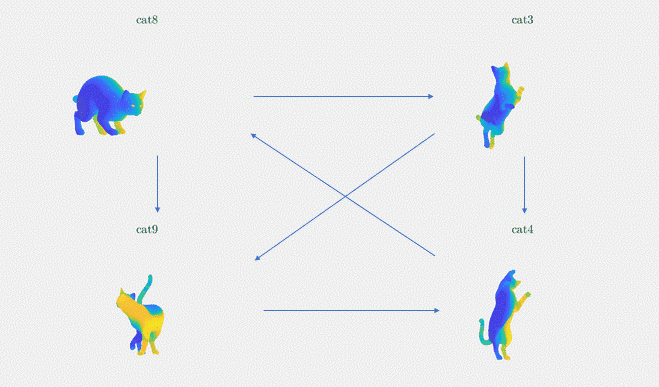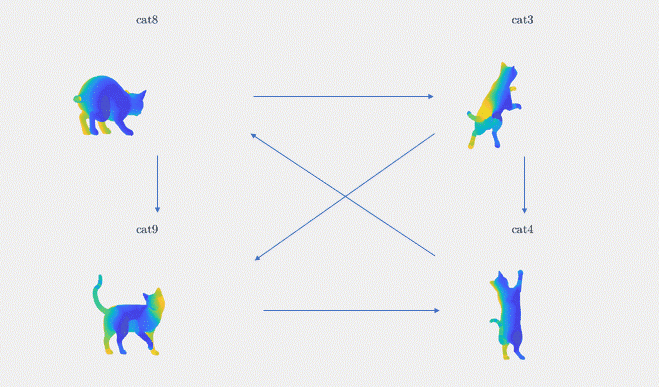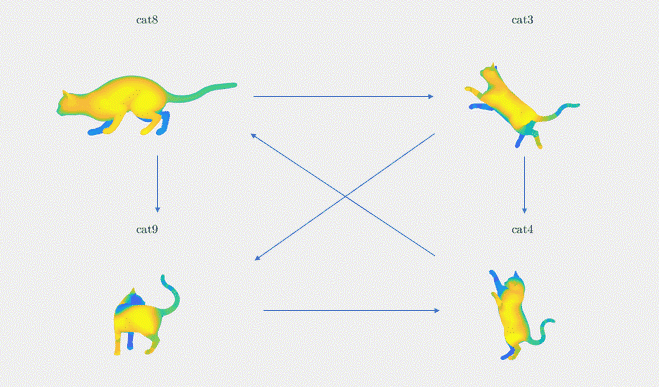
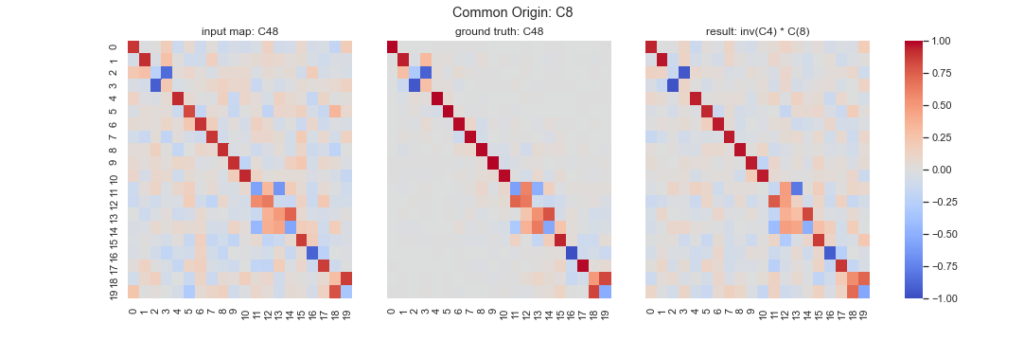
Let’s now introduce notations to give the mathematical formulation of the synchronization method. We begin with a set of pairwise functional maps, \(C_{ij} \in \{\mathcal{F}(M_i,M_j)\}_{i,j}\) for \((i,j) \in \varepsilon\). M denotes the set of \(n\) input 3D shapes and \(\varepsilon\) denotes the set of the edges of the directed graph of \(n\) nodes representing the shapes: \(\varepsilon \subset \{1,\dots, n\} \times \{1,\dots, n\}\). We are then interested in finding the underlying “absolute functional maps” \(C_i\) for \(i\in\{1,\dots,n\}\) with respect to a common origin (e.g. \(C_0=I\), the identity matrix) that would respect the consistency of the underlying graph structure. We illustrate these notations in Figure 3. Given a graph of four cat shapes (cat8, cat3, cat9, cat4) and their relative functional maps (C83, C94, C34, C89, C48, C39), we want to find the absolute functional maps (C8, C3, C4, C9).
Figure 3: Synchronization between four shapes from the TOSCA dataset. We are given the functional maps Cij between pairs of shapes (i, j) in the graph. We wish to find the absolute functional map of these shapes: the Ci for each shape i in the graph.
3. Riemannian Optimization Algorithm
In this section, we explain how we frame the synchronization problem as an optimization problem on a Riemannian manifold.
Constraints: As shown by Ovsjanikov et al (2012), functional maps are orthogonal matrices for near-isometry: the columns forming functional map matrix C are orthonormal vectors. Hence, functional maps naturally reside on the Stiefel manifold which is the manifold of matrices with orthonormal columns. The Stiefel manifold can be equipped with a Riemannian geometric structure that is implemented in the packages geomstats and pymanopt. We design a Riemannian optimization algorithm that iterates over the Stiefel manifold (or power manifold of Stiefels) using elementary operations of Riemannian geometry, and converges to our estimates of absolute functional maps. Later, we compare this method to the corresponding non-Riemannian optimization algorithm that does not constrain the iterates to belong to the Stiefel manifold.
Cost function: We describe here the cost function associated with the Riemannian optimization. We want our absolute functional maps to be consistent with the relative maps as much as possible. That is, in the ideal case, \(C_i \cdot C_{ij} = C_j \). To abide by this, we consider the following cost function in our algorithm:
In this equation, we measure this norm in terms of the Frobenius norm, which is equal to the square root of the sum of the squares of the matrix values. This cost is implemented in Python, as follows:
# Cis are the maps we compute, input_Cijs are the input functional maps
def cost_function(Cis, input_Cijs):
cost = 0.
for edge, Cij in zip(EDGES, input_Cijs):
i, j = edge
Ci_Cij = np.matmul(Cis[i], Cij)
cost += np.linalg.norm(Ci_Cij - Cis[j], "fro") ** 2
return cost
Optimizer: Our goal is to minimize this cost with respect to the Cis, while constraining the Cis to remain on the Stiefel manifold. For solving our optimization problem, we use the TrustRegion algorithm from the Pymanopt library.
4. Experiments and Results
We present some preliminary results on the TOSCA dataset.
Dataset: For our baseline experiments, we use the 11 cat shapes from the TOSCA dataset. The cats have a wide variety of poses and deformations which make them particularly suitable for our baseline testing.
Initial Functional Map Generation: For each pair of cats within the TOSCA dataset, we compute initial functional maps using state-of-the-art methods, by adapting the source code from here. Our functional maps are of size 20 * 20, i.e they are written in terms of 20 basis functions on the source shape and 20 basis functions on the target shape.
Graph Generation: We implement a random graph generator using networkX that can generate cycle-consistent graphs. We use this graph generator to generate a graph, with nodes corresponding to shapes from a subset of the TOSCA dataset, and with edges depicting the correspondence relationship between the selected shapes. In our future experiments, this graph generator will allow us to compare the performance of our method depending on the number of shapes (or nodes) and the number of known initial correspondences (or initial functional maps) between the shapes (or sparsity of the graph).
Perturbation: We showcase the efficiency of our algorithm by inducing a synthetic perturbation on the initial functional maps and showing how synchronization allows us to correct it. Specifically, we add a Gaussian perturbation to the initial functional maps, with standard deviation s = 0.1, and project the resulting corrupted matrices on the Stiefel manifold to get “corrupted functional maps”. The corrupted functional maps are the inputs of our optimization algorithm.
Results: We demonstrate the result of our optimization algorithm for a subset of the TOSCA dataset and initial (corrupted) functional maps generated with the methods described above: we consider the graph with 4 shapes and 6 edges that was presented in Figure 3. The optimization algorithm converged in less than 20 iterations and less than 1 second. Figure 4 shows the output of our optimization algorithm on this graph. Specifically, we consider a function defined on one of the cats, and map it to the other cats using our functional maps. We can see how efficiently different body parts are being meaningfully mapped in each of these cat shapes.
Figure 4. The absolute functional map output is visualized as point-to-point mapping, The regions marked with the same colors on the four shapes are being mapped to each other (noise standard deviation = 0.1)
Comparison with initially corrupted functional maps: We show how synchronization allows us to improve over our initially corrupted functional maps. Figure 5 shows a comparison between the corrupted functional maps, the ground-truth (un-corrupted) functional maps, and the output functional maps computed via the output absolute maps given by our algorithm, for the correspondence between cat 4 and cat 8. While the algorithm does not allow to fully recover the ground-truth, our analysis shows that it has refined the initially corrupted functional maps. For example, we observe that the noise has been reduced for the off-diagonal elements. This visual inspection is confirmed quantitatively: the distance between the initially corrupted functional maps and the ground-truth is 2.033 while the distance between the output functional maps and the ground-truth is 1.853, as observed in Table 1.
However, the results on the other functional maps C83, C39, C94, C89, C34 are less convincing; see errors reported in Table 1. This can be explained by the fact that we have chosen a relatively small graph, with only 4 nodes i.e. 4 shapes. As a consequence, the synchronization method leveraging cycle consistency can be less efficient. Future results will investigate the performances of our approach for different graphs with different numbers of nodes and different numbers of edges (sparsity of the graph).
Func. Maps.
Error C83
Error C39
Error C48
Error C94
Error C89
Error C34
Before sync.
1.762
1.658
2.033
1.877
1.819
1.854
After sync.
1.659
2.519
1.741
2.323
2.118
2.492
After sync. (Riem.)
2.576
2.621
1.853
1.984
2.181
2.519
Table 1. Frobenius norms of the difference between different functional maps and the ground-truth functional maps
Discussion: We compare this method with the method that does not restrict the functional maps to be on the Riemannian Stiefel manifold. We observe similar performances, with a preference for the non-Riemannian optimization method. Future work will investigate which data regimes require optimization with Riemannian constraints and which regimes do not necessarily require it.
Figure 5. Result for the functional map relating cat 4 to cat 8. Left: Corrupted functional maps that are the inputs of our algorithm. Middle: ground-truth functional maps, i.e. functional maps before corruption with synthetic noise. Right: Functional maps given by the output of our algorithm.
Conclusion
In this blog, we explained the first steps of our work on shape correspondences. Currently, we are working on a Markov Chain Monte Carlo (MCMC) implementation to get better results with associated uncertainty quantification. We are also working on a custom gradient function to get better performance. In the coming weeks, we look forward to experimenting with other benchmark datasets and comparing our results with baselines.
Acknowledgment: We thank our mentors, Dr. Nina Miolane and Dr. Tolga Birdal for their consistent guidance and mentorship. They have relentlessly supported us from the beginning, debugged our errors. We especially thank Nina for guiding us to write this blog post. We are very grateful for her keen enthusiasm 😇. We also thank our TA, Dr. Dena Bazazian for her important feedback.
By Natasha Diederen, Alice Mehalek, Zhecheng Wang, and Olga Guțan
This week we worked on extending the results described here. We learned an array of new techniques and enhanced existing skills that we had developed the week(s) before. Here is some of the work we have accomplished since the last blog post.
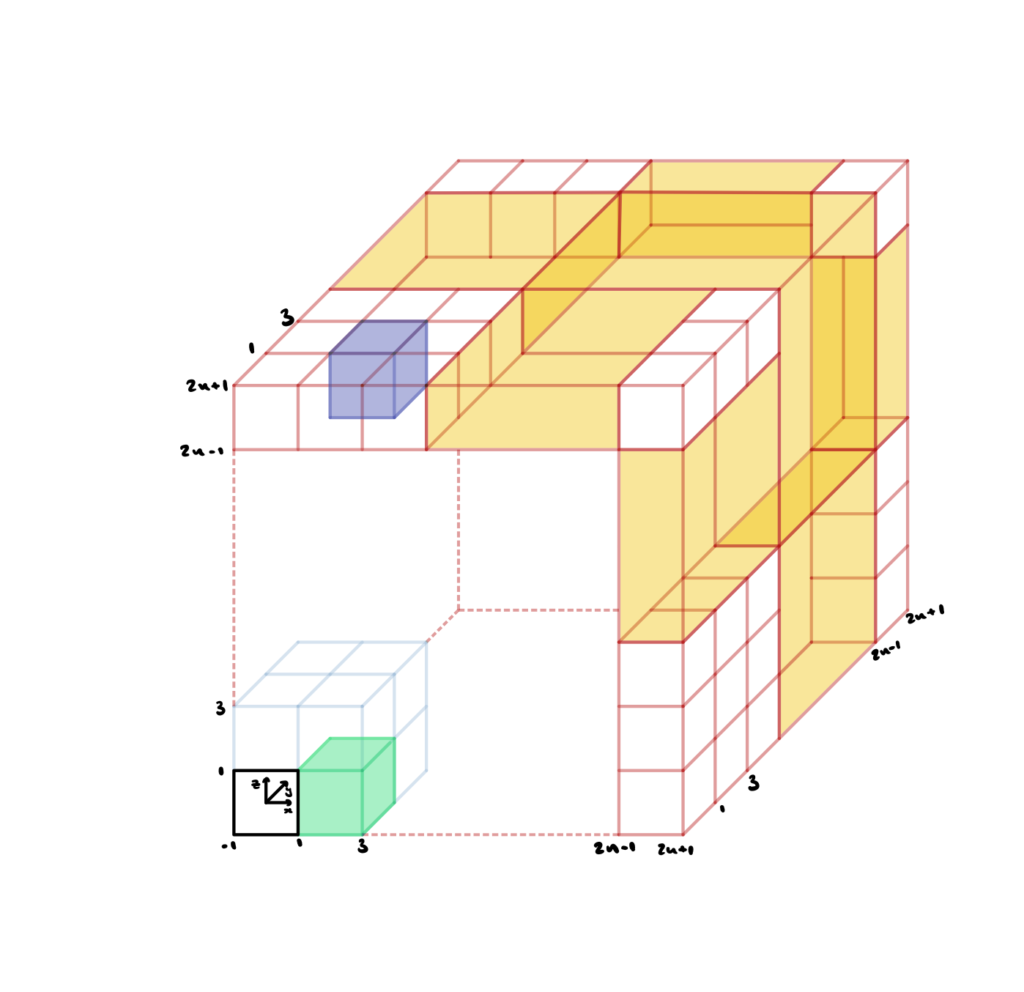
Tiling
One of the improvements we made was to create a tiling function which created an \( n^3 \) grid of our triply periodic surfaces, so that we were better able to visualise them as a structure. We started off with a surface inside a \( [-1, 1]^3 \) cube, and then imagined an \(n^3\) grid (pictured below). To make a duplicate of the surface in one of these grid cubes, we considered how much the surface would need to be translated in the \(x\), \(y\) and \(z\) directions. For example to duplicate the original surface in the black cube into the green square, we would need to shift all the \(x\)-coordinates in the mesh by two (since the cube is length two in all directions) and leave the \(y\)- and \(z\)-coordinates unchanged. Similarly, to duplicate the original surface into the purple square, we would need to shift the all \(x\)-coordinates in the mesh by two, all the \(y\)-coordinates by two, and all the \(z\)-coordinates by \(2n\).
Figure 1. A visualization of the the surface tiling.
To copy the surface \(n^3\) times into the right grid cubes, we need find all the unique permutations of groups of three vectors chosen from \((0,2,4, \dots, 2n)\) and add them to the vertices matrix of the of the mesh. To update the face data, we add multiples of the number of vertices each time we duplicate into a new cube.
With this function in place, we can now see our triply periodic surfaces morphing as a larger structure.
Figure 2. A 3x3x3 Tiling of the Surface.
Blender
A skill we continued developing and something we have grown to enjoy, is what we affectionately call “blendering.” To speak in technical terms, we use the open-source software Blender to generate triangle meshes that we, then, use as tests for our code.
For context: Blender is a free and open-source 3D computer graphics software tool set used for a plethora of purposes, such as creating animated films, 3D printed models, motion graphics, virtual reality, and computer games. It includes many features and it, truly, has endless possibilities. We used one small compartment of it: mesh creation and mesh editing, but we look forward to perhaps experiencing more of its possibilities in the future.
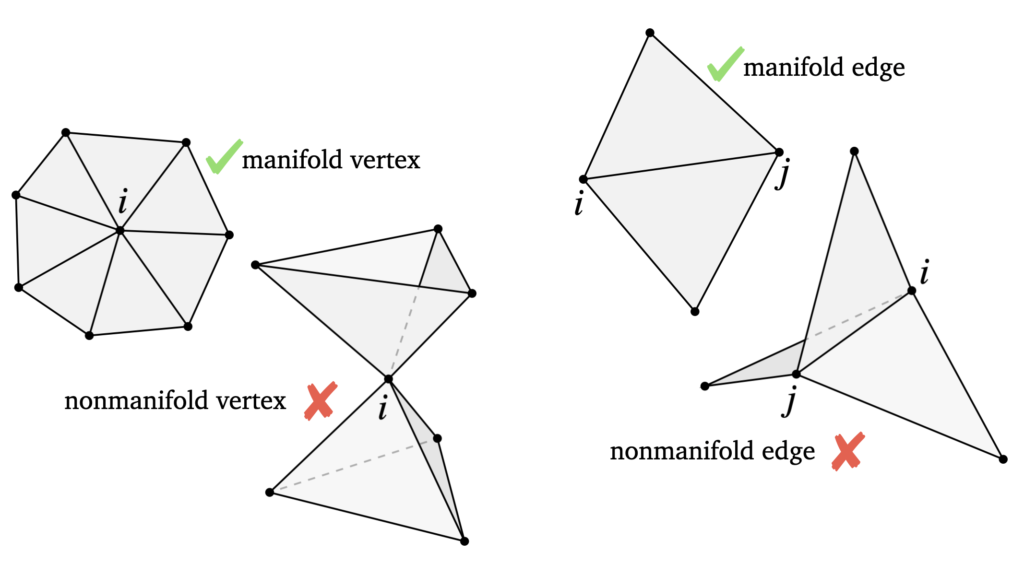
We seek to create shapes that are non-manifold; mathematically, this means that there exist local regions in our surface that are not homeomorphic to a subset of the Euclidean space. In other words, non-manifold shapes contain junctions where more than two faces meet at an edge, or more than two faces meet at a vertex without sharing an edge.
Figure 3. Manifold versus nonmanifold edges and vertices. Source.
This is intellectually intriguing to consider, because most standard geometry processing methods and techniques do not consider this class of shapes. As such, most algorithms and ideas need to be redesigned for non-manifold surfaces.
Our Blender work consisted of a lot of trial-and-error. None of us had used Blender before, so the learning curve was steep. Yet, despite the occasional frustration, we persevered. With each hour worked, we increased our understanding and expertise, and in the end we were able to generate surfaces we were quite proud of. Most importantly, these triangle meshes have been valuable input for our algorithm and have helped us explore in more detail the differences between manifold and non-manifold surfaces.
Figure 4. Manifold and Nonmanifold Periodic Surfaces.
Houdini
The new fellows joining this week came from a previous project on minimal surface led by Stephanie Wang, which used Houdini as a basis for generating minimal surfaces. Thus, we decided we could use Houdini to carry out some physical deformations, to see how non-manifold surfaces performed compared to similar manifold surfaces.
We used a standard Houdini vellum solver with some modifications to simulate a section of our surface falling under gravity. Below are some of the simulations we created.
Figure 5. A Nonmanifold and a Manifold Surface Experiencing Gravity.
Newton’s Method
When we were running Pinkhall and Polthier’s algorithm on our surfaces, we noticed that that algorithm would not stop at a local saddle point such as the Schwarz P surface, but would instead run until there was only a thin strip of area left, which is indeed a minimum, but not a very useful one.
Therefore, we switched to Newton’s Method to solve our optimization problem.
We define the triangle surface area as an energy: let the three vertices of a triangle be \(\mathbf{q}_1\), \(\mathbf{q}_2\), \(\mathbf{q}_3\). Then \(E = \frac{1}{2} \|\mathbf{n}\| \), where \(\mathbf{n} = (\mathbf{q}_2-\mathbf{q}_1) \times (\mathbf{q}_3-\mathbf{q}_1)\) is the surface area normal. Then we derive its Jacobian and Hessian, and construct the Jacobian and Hessian for all faces in the mesh.
However, this optimization scheme still did not converge to the desired minimum, perhaps because our initialization is far from the solution. Additionally, one of our project mentors implemented the approach in C++ and, similarly, no results ensued. Later, we tried to add line search to Newton’s Method, but also no luck.
Although our algorithm still does not converge to some minimal surfaces which we know to exist, it has generated the following fun bugs.
Figure 6.
Figure 7.
Figure 8.
Future Work
In the previous blog post, we discussed studying the physical properties of nonmanifold TPMS. Over the past week, we used the Vellum Solver in Houdini and explored some of the differences in physical properties between manifold and nonmanifold surfaces. However, this is just the beginning — we can continue to expand our work in that direction.
Additional goals may include writing a script to generate many possible initial conditions, then converting the initial conditions into minimal surfaces, either by using the Pinkall and Polthier algorithm, or by implementing another minimal-surface-generating algorithm.
More work can be done on enumerating all of the possible nonmanifold structures that the Pinkall and Polthier algorithm generates. The researchers can, then, categorize the structures based on their geometric or physical properties. As mentioned last week, this is still an open problem.
Acknowledgments
We would like to thank our mentors Etienne Vouga, Nicholas Sharp, and Josh Vekhter for their patient guidance and the numerous hours they spent helping us debug our Matlab code, even when the answers were not immediately obvious to any of us. A special thanks goes to Stephanie Wang, who shared her Houdini expertise with us and, thus, made a lot of our visualizations possible. We would also like to thank our Teaching Assistant Erik Amezquita.
Authors: Bryce Van Ross, Talant Talipov, Deniz Ozbay
The SGI project titled Robust computation of the Hausdorff distance between triangle meshes originally was planned for a 2 week duration, and due to common interest in continuing, was extended to 3 weeks. This research was led by mentor Dr. Leonardo Sacht of the Department of Mathematics of the Federal University of Santa Catarina (UFSC), Brazil. Accompanying support was TA Erik Amezquita, and the project team consisted of SGI fellows, math (under)graduate students, Deniz Ozbay, Talant Talipov, and Bryce Van Ross. Here is an introduction to the idea of our project.The following is a summary of our research and our experiences, regarding computation of the Hausdorff distance.
Definitions
Given two triangle meshes A, B in R³, the following are defined:
1-sided Hausdorff distanceh:
$$h(A, B) = \max\{d(x, B) : x\in A\} = \max\{\min\{\|x-y\|: x\in A\}: y\in B\}$$
where d is the Euclidean distance and |x-y| is the Euclidean norm. Note thath, in general, is not symmetric. In this sense, h differs from our intuitive sense of distance, being bidirectional. So, h(B, A) can potentially be a smaller (or larger) distance in contrast to h(A, B). This motivates the need for an absolute Hausdorff distance.
2-sided Hausdorff distance H:
$$H(A,B) = \max\{h(A, B), h(B, A)\}$$
By definition, H is symmetric. Again, by definition, H depends on h. Thus, to yield accurate distance values for H, we must be confident in our implementation and precision of computing h.
Objects are geometrically complex and so too can their measurements be. There are different ways to compare meshes to each other via a range of geometry processing techniques and geometric properties. Distance is often a common metric of mesh comparison, but the conventional notion of distance is at times limited in scope. See Figures 1 and 2 below.
Figure 1: This distance is limited to the red vertices, ignoring other points of the triangles.
Figure 2: This distance ignores the spatial positions of the triangles. So, the distance is skewed to the points of the triangles, and not the contribution of the space between the triangles.
Our research focuses on robustly (efficiently, for all possible cases) computing the Hausdorff distance h for pairs of triangular meshes of objects. The Hausdorff distance h is fundamentally a maximum distance among a set of desirable distances between 2 meshes. These desirable distances are minimum distances of all possible vectors resulting from points taken from the first mesh to the second mesh.
Why is h significant? If h tends to 0, then this implies that our meshes, and the objects they represent, are very similar. Strong similarity indicates minimal change(s) from one mesh to the other, with possible dynamics being a slight deformation, rotation, translation, compression, stretch, etc. However, if h >> 0, then this implies that our meshes, and the objects they represent, are dissimilar. Weak similarity indicates significant change(s) from one mesh to the other, associated with the earlier dynamics. Intuitively, h depends on the strength of ideal correspondence from triangle to triangle, between the meshes. In summary, h serves as a means of calculating the similarity between triangle meshes by maximally separating the meshes according to the collection of all minimum pointwise-mesh distances.
Applications
The Hausdorff distance can be used for a variety of geometry processing purposes. Primary domains include computer vision, computer graphics, digital fabrication, 3D-printing, and modeling, among others.
Consider computer vision, an area vital to image processing, having a multitude of technological applications in our daily lives. It is often desirable to identify a best-candidate target relative to some initial mesh template. In reference to the set of points within the template, the Hausdorff distance can be computed for each potential target. The target with the minimum Hausdorff distance would qualify as being the best fit, ideally being a close approximation to the template object. The Hausdorff distance plays a similar role relative to other areas of computer science, engineering, animation, etc. See Figure 3 and 4, below, for a general representation of h.
Figure 3: Hausdorff distance h corresponds to the dotted lined distance of the left image. In the right image, h is found in the black shaded region of the green triangle via the Branch and Bound Method. This image is found in Figure 1 of the initial reading provided by Dr. Leonardo Sacht.
Figure 4: Hausdorff distance h corresponds to the solid lined distance of the left image. This distance is from the furthest “leftmost” point of the first mesh (armadillo) to the closest “leftmost” point of the second mesh. This image is found in Figure 5 of the initial reading provided by Dr. Leonardo Sacht.
Branch and Bound Method
Our goal was to implement the branch-and-bound method for calculating H. The main idea is to calculate the individual upper bounds of Hausdorff distance for each triangle meshes of mesh A and the common lower bound for the whole mesh A. If the upper bound of some triangle is greater than the general lower bound, then this face is discarded and the remaining ones are subdivided. So, we have these 3 main steps:
1. Calculating the lower bound
We define the lower bound as the minimum of the distances from all the vertices of mesh A to mesh B. Firstly, we choose the vertex P on mesh A. Secondly, we compute the distances from point P to all the faces of mesh B. The actual distance from point P to mesh B is the minimum of the distances that were calculated the step before. For more theoretical details you should check this blog post: http://summergeometry.org/sgi2021/finding-the-lower-bounds-of-the-hausdorff-distance/
The implementation of this part:
Calculating the distance from the point P to each triangle mesh T of mesh B is a very complicated process. So, I would like not to show the code and only describe it. The main features that should be considered during this computation is the position of point P relatively to the triangle T. For example, if the projection of point P on the triangle’s plane lies inside the triangle, then the distance from point P to triangle is just the length of the corresponding normal vector. In the other cases it could be the distance to the closest edge or vertex of triangle T.
During testing this code our team faced the problem: the calculating point-triangle distance takes too much time. So, we created the bounding-sphere idea. Instead of computing the point-triangle distance we decided to compute point-sphere distance, which is very simple. But what sphere should we pick? The first idea that sprung to our minds was the sphere that is generated by a circumscribed circle of the triangle T. But the computation of its center is also complicated. That is why we chose the center of mass M as the center of the sphere and maximal distance from M to each vertex of triangle T. So, if the distance from the point P to this sphere is greater than the actual minimum, then the distance to the corresponding triangle is exactly not the minimum. This trick made our code work approximately 30% faster. This is the realization:
During testing the code from this page on big meshes our team faced the memory problem. On the grounds that we tried to store the lengths that we already computed, it took too much memory. That is why we decided just compute these length one more time, even though it takes a little bit more time (it is not crucial):
Below are our results for two simple meshes, first one being a sphere mesh and the second one being the simple mesh found in the blog post linked under the “Discarding and subdividing” section.
Figure 5: Results for a sphere mesh with different tolerance levels
Figure 6: Results for a smaller, simple mesh with different tolerance levels
Conclusion
The intuition behind how to determine the Hausdorff distance is relatively simple, however the implementation of computing this distance isn’t trivial. Among the 3 tasks of this Hausdorff distance algorithm (finding the lower bound, finding the upper bound, and finding a triangular subdivision routine), the latter two tasks were dependent on finding the lower bound. We at first thought that the subdivision routine would be the most complicated process, and the lower bound would be the easiest. We were very wrong: the lower bound was actually the most challenging aspect of our code. Finding vertex-vertex distances was the easiest aspect of this computation. Given that in MATLAB triangular meshes are represented as faces of vertex points, it is difficult to identify specific non-vertex points of some triangle. To account for this, we at first used computations dependent on finding a series of normals amongst points. This yielded a functional, albeit slow, algorithm. Upon comparison, the lower bounds computation was the cause of this latency and needed to be improved. At this point, it was a matter of finding a different implementation. It was fun brainstorming with each other about possible ways to do this. It was more fun to consider counterexamples to our initial ideas, and to proceed from there. At a certain point, we incorporated geometric ideas (using the centroid of triangles) and topological ideas (using the closed balls) to find a subset of relevant faces relative to some vertex of the first mesh, instead of having to consider all possible faces of the secondary mesh. Bryce’s part was having to mathematically prove his argument, for it to be correct, but only to find out later it would be not feasible to implement (oh well). Currently, we are trying to resolve bugs, but throughout the entire process we learned a lot, had fun working with each other, and gained a stronger understanding of techniques used within geometry processing.
In conclusion, it was really fascinating to see the connection between the theoretical ideas and the implementation of an algorithm, especially how a theoretically simple algorithm can be very difficult to implement. We were able to learn more about the topological and geometric ideas behind the problem as well as the coding part of the project. We look forward to finding more robust ways to code our algorithm, and learning more about the mathematics behind this seemingly simple measure of the geometric difference between two meshes.
by Alice Mehalek, Marcus Vidaurri, and Zhecheng Wang
Background
UV mapping or UV parameterization is the process of mapping a 3D surface to a 2D plane. A UV map assigns every point on the surface to a point on the plane, so that a 2D texture can be applied to a 3D object. A simple example is the representation of the Earth as a 2D map. Because there is no perfect way to project the surface of a globe onto a plane, many different map projections have been made, each with different types and degrees of distortion. Some of these maps use “cuts” or discontinuities to fragment the Earth’s surface.
In computer graphics, the typical method of UV mapping is by representing a 3D object as a triangle mesh and explicitly assigning each vertex on the mesh to a point on the UV plane. This method is slow and must be repeated often, as the same texture map can’t be used by different meshes of the same object.
For any kind of parametrization or UV mapping, a good UV map must be injective and should be conformal (preserving angles) while having few cuts. Ideally it should also be isometric (preserve relative areas). In general, however, more cuts are needed to achieve less distortion.
Volume-encoded parameterization
Our research mentor, Marco Tarini, developed the method of Volume-encoded UV mapping. In this method, a surface is represented by parametric functions and each point on the surface is mapped to a UV position as a function of its 3D position. This is done by enclosing the surface or portion of the surface in a unit cube, or voxel, and assigning UV coordinates to each of the cube’s eight vertices. All other points on the surface can be mapped by trilinear interpolation. Volume-encoded parametrization has the advantage of only needing to store eight sets of UV coordinates per voxel, instead of unique locations of many mesh vertices, and can be applied to different types of surface representations, not just meshes.
We spent the first week of our research project learning about volume-encoded parametrization by exploring the 2D equivalent: mapping 2D curves to a one-dimensional line, u. Given a curve enclosed within a unit square, our task was to find the u-value for each corner of the square that optimized injectivity, conformality, and orthogonality. We did this using a Least Squares method to solve a linear system consisting of a set of constraints applied to points on the surface. All other points on the curve could then be mapped to u by bilinear interpolation.
A quarter circle (the red curve on the xy plane of the 3D plot) is mapped to a line, u, which is also represented as the height on the z axis in the 3D plot. The surface in the 3D plot is obtained by bilinear interpolation of the height of each corner of the square, and the red curve along the surface represents the path of the quarter circle mapped to 1D.
Each point on the path has a unique height, indicating an injective mapping.
An injective mapping was not possible for portions of a circle greater than a semicircle.
Each point on the path of u does not have a unique height, indicating loss of injectivity. There is also distortion in the middle where the slope is variable.
In Week 2 of the project, we moved on to 3D and created UV maps for portions of a sphere, using a similar method to the 2D case. Some of the questions we wanted to answer were: For what types of surfaces is volume-encoded parametrization possible? At what level of shape complexity is it necessary to introduce cuts, or split up the surface into smaller voxels? In the 2D case, we found that injectivity could be preserved when mapping curves less than half a circle, but there were overlaps for curves greater than a semicircle.
One dimension up, when we go into the 3D space, we found that uniform sampling on the quarter sphere was challenging. Sampling uniformly in the 2D parametric space will result in a distorted sampling that becomes denser when getting closer to the north pole of the sphere. We tried three different approaches: rewriting the parametric equations, sampling in a unit-sphere, and sampling in the 3D target space and then projecting the sample points back to the surface. Unfortunately, all three methods only worked with a certain parametric sphere equation.
When mapping a portion of a sphere to 2D, the grid allows us to see where the mapping is distorted. This mapping is most accurate at the north pole, while areas and angles both become distorted toward the equator.
In conclusion, over the two weeks, we designed and tested a volume-encoded least-squares conformal mapping in both 2D and 3D. In the future, we plan to rewrite the code in C++ and run more experiments.
By Joana Portmann, Tal Rastopchin, and Sahra Yusuf. Mentored by Professor Keenan Crane.
Intrinsic parameterization
During these last two weeks, we explored intrinsic encoding of triangle meshes. As an introduction to this new topic, we wrote a very simple algorithm that lays out a triangle mesh flat. We then improved this algorithm via line search over a week. In connection with this, we looked into terms like ‘angle defects,’ ‘cotangent weights,’ and the ‘cotangent Laplacian’ in preparation for more current research during the week.
From intrinsic to extrinsic parameterization
To get a short introduction into intrinsic parameterization and its applications, I quote some sentences from Keenan’s course. If you’re interested in the subject I can recommend the course notes “Geometry Processing with Intrinsic Triangulations.” “As triangle meshes are a basic representation for 3D geometry, playing the same central role as pixel arrays in image processing, even seemingly small shifts in the way we think about triangle meshes can have major consequences for a wide variety of applications. Instead of thinking about a triangle as a collection of vertex positions in \(\mathbb{R}^n\) from the intrinsic perspective, it’s a collection of edge lengths associated with edges.”
Many properties of a surface such as the shortest path do only depend on local measurements such as angles and distances along the surfaces and do not depend on how the surface is embedded in space (e.g. vertex positions in \(\mathbb{R}^n\)), so an intrinsic representation of the mesh works fine. Intrinsic triangulations bring several deep ideas from topology and differential geometry into a discrete, computational setting. And the framework of intrinsic triangulations is particularly useful for improving the robustness of existing algorithms.
Laying out edge lengths in the plane
Our first task was to implement a simple algorithm that uses intrinsic edge lengths and a breadth-first search to flatten a triangle mesh onto the plane. The key idea driving this algorithm is that given just a triangle’s edge lengths we can use the law of cosines to compute its internal angles. Given a triangle in the plane we can use the internal angles to flatten out its neighbors into the plane. We will later use these angles to modify the edge lengths so that we “better” flatten the model. The algorithm works by choosing some root triangle and then performing a breadth-first traversal to flatten each of the adjacent triangles into the plane until we have visited every triangle in the mesh.
Breadth-first search pseudocode
Some initial geometry central pseudocode for this breadth first search looks something like
// Pick and flatten some starting triangle
Face rootTriangle = mesh->face(0);
// Calculate the root triangle’s flattened vertex positions
calculateFlatVertices(rootTriangle);
// Initialize a map encoding visited faces
FaceData<bool> isVisited(*mesh, false);
// Initialize a queue for the BFS
std::queue<Face> visited;
// Mark the root triangle as visited and pop it into the queue
isVisited[rootTriangle] = true;
visited.push(rootTriangle);
// While our queue is not empty
while(!visited.empty())
{
// Pop the current Face off the front of the queue
Face currentFace = visited.front();
visited.pop();
// Visit the adjacent faces
For (Face adjFace : currentFace.adjacentFaces()) {
// If we have not already visited the face
if (!visited[adjFace]
// Calculate the triangle’s flattened vertex positions
calculateFlatVertices(adjFace);
// And push it onto the queue
visited.push(adjFace);
}
}
}
In order to make sure we lay down adjacent triangles with respect to the computed flattened plane coordinates of their parent triangle we need to know exactly how a child triangle connects to its parent triangle. Specifically, we need to know which edge is shared by the parent and child triangle and which point belongs to the child triangle but not the parent triangle. One way we could retrieve this information is by computing the set difference between the vertices belonging to the parent triangle and child triangle, all while carefully keeping track of vertex indices and edge orientation. This certainly works, however, it can be cumbersome to write a brute force combinatorial helper method for each unique mesh element traversal routine.
The halfedge mesh data structure
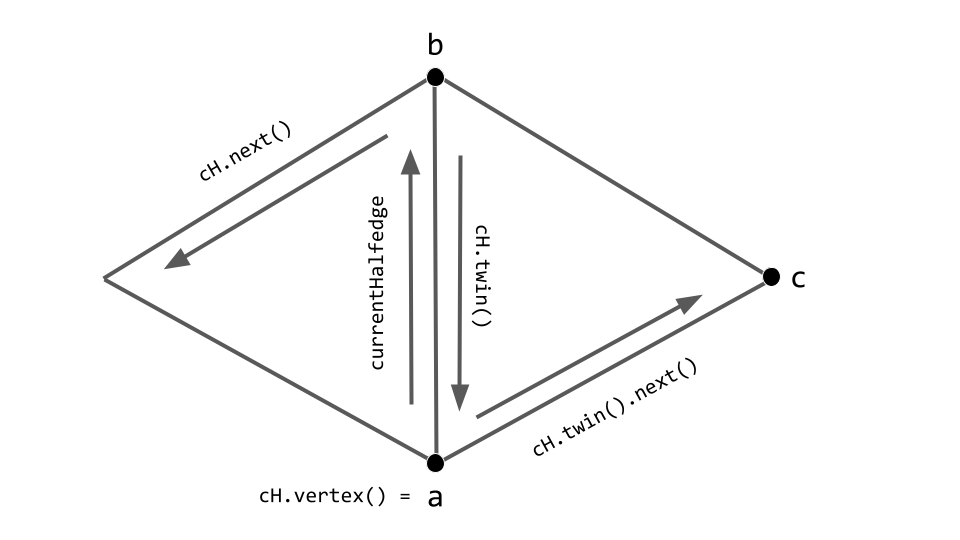
Professor Keenan Crane explained that a popular mesh data structure that allows a scientist to conveniently implement mesh traversal routines is that of the halfedge mesh. At its core a halfedge mesh encodes the connectivity information of a combinatorial surface by keeping track of a set of halfedges and the two connectivity functions known as twin and next. Here the set of halfedges are none other than the directed edges obtained from an oriented triangle mesh. The twin function takes a halfedge and brings it to its corresponding oppositely oriented twin halfedge. In this fashion, if we apply the twin function to some halfedge twice we get the same initial halfedge back. The next function takes a halfedge and brings it to the next halfedge in the current triangle. In this fashion if we take the next function and apply it to a halfedge belonging to a triangle three times, we get the same initial halfedge back.
A diagram depicting the halfedge data structure connectivity relationships. Source.
It turns out that geometry central uses the halfedge mesh data structure and so we can rewrite the traversal of the adjacent faces loop to more easily retrieve our desired connectivity information. In the geometry central implementation, every mesh element (vertex, edge, face, etc.) contains a reference to a halfedge, and vice versa.
// Pop the current Face off the front of the queue
Face currentFace = visited.front();
visited.pop();
// Get the face’s halfedge
Halfedge currentHalfedge = currentFace.halfedge();
// Visit the adjacent faces
do
{
// Get the current adjacent face
Face adjFace = currentHalfedge.twin().face();
if (!isVisited[adjFace])
{
// Retrieve our desired vertices
Vertex a = currentHalfedge.vertex();
Vertex b = currentHalfedge.next().vertex();
Vertex c = currentHalfedge.twin().next().next().vertex();
// Calculate the triangle’s flattened vertex positions
calculateFlatVertices(a, b, c);
// And push it onto the queue
visited.push(adjFace);
}
// Iterate to the next halfedge
currentHalfEdge = currentHalfEdge.next();
}
// Exit the loop when we reach our starting halfedge
while (currentHalfEdge != currentFace.halfedge());
Here’s a diagram illustrating the relationship between the currentHalfedge and vertices a, b, and c.
A diagram illustrating the connectivity relationship between the currentHalfedge and vertices a, b, and c. Note that cH abbreviates currentHalfedge.
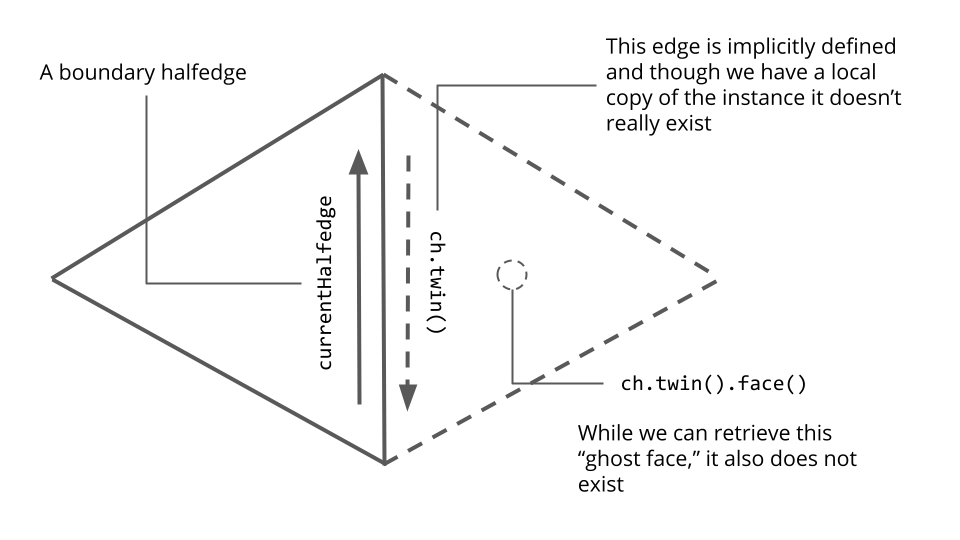
Segfaults, debugging, and ghost faces
This all looks great right? Now we need to determine the specifics of calculating the flat vertices? Well, not exactly. When we were running a version of this code in which we attempted to visualize the resulting breadth-first traversal we encountered several random segfaults. When Sahra ran a debugger (shout out to GDB and LLDB 🥰) we learned that the culprit was the isVisited[adjFace] function call on the line
if (!isVisited[adjFace])
We were very confused as to why we would be getting a segfault while trying to retrieve the value corresponding to the key adjFace contained in the map FaceData<bool> isVisited. Sahra inspected the contents of the adjFace object and observed that it had index 248 whereas the mesh we were testing the breadth-first search on only had 247 faces. Because C++ zero indexes its elements, this means we somehow retrieved a face with index out of range by 2! How could this have happened? How did we retrieve that face in the first place? Looking at the lines
// Get the current adjacent face
Face adjFace = currentHalfedge.twin().face();
we realized that we made an unsafe assumption about currentHalfedge. In particular, we assumed that it was not a boundary edge. What does the twin of a boundary halfedge that has no real twin look like? If the issue we were running to was that the currentHalfedge was a boundary halfedge, why didn’t we get a segfault on simply currentHalfedge.twin()? Doing some research, we found that the geometry central internals documentation explains that
“We can implicitly encode the twin() relationship by storing twinned halfedges adjacent to one another– that is, the twin of an even-numbered halfedge numbered he is he+1, and the twin of and odd-numbered halfedge is he-1.”
Aha! This explains exactly why currentHalfedge.twin() still works on a boundary halfedge; behind the scenes, it is just adding or subtracting one to the halfedge’s index. Where did the face index come from? We’re still unsure, but we realized that the face currentHalfedge.twin().face() only makes sense (and hence can only be used as a key for the visited map) when currentHalfedge is not a boundary halfedge. Here is a diagram of the “ghost face” that we think the line Face adjFace = currentHalfedge.twin().face() was producing.
A diagram depicting how taking the face of the twin of a boundary halfedge produces a nonexistent face.
Changing the map access line in the if statement to
if (!currentHalfedge.edge().isBoundary() && !isVisited[adjFace])
resolved the segfaults and produced a working breadth-first traversal.
Conformal parameterization
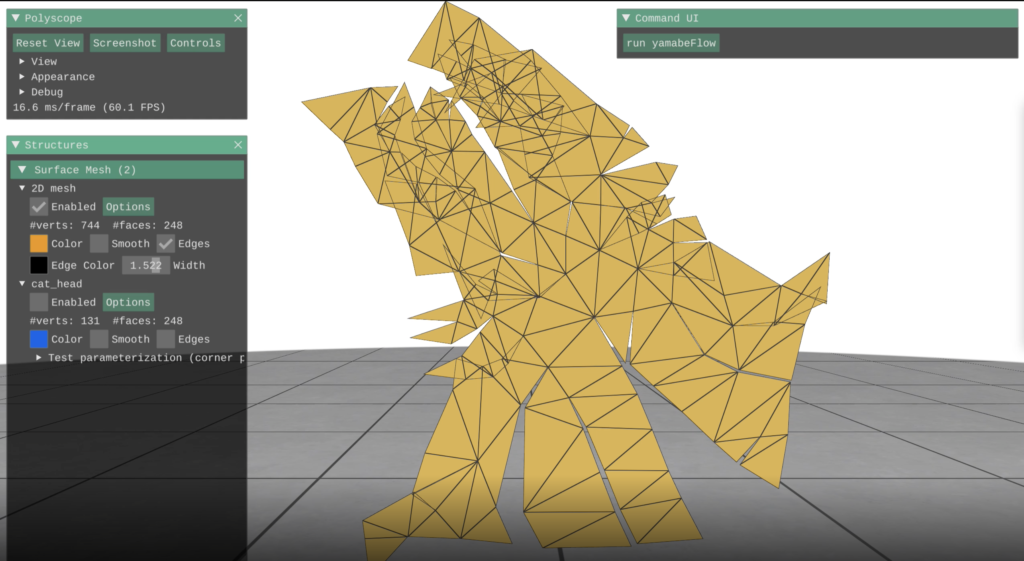
Here is a picture illustrating applying the flattening algorithm to a model of a cat head.
A picture illustrating the application of the flattening algorithm to a model of a cat head.
You can see that there are many cracks and this is because the model of the cat head is not flat—in particular, it has vertices with nonzero angle defect. A vertex angle defect for a given vertex is equal to the difference between \(2 \pi\) and the sum of the corner angles containing that vertex. This is a good measure of how flat a vertex is because for a perfectly flat vertex, all angles surrounding it will sum to \(2 \pi\).
After laying out the edges on the plane \(z=0\), we began the necessary steps to compute a conformal flattening (an angle-preserving parameterization). In order to complete this step, we needed to find a set of new edge lengths which would both be related to the original ones by a scale factor and minimize the angle defects,
where where \(l_{ij}\) is the new intrinsic edge length, \(\phi_i, \phi_j\) are the scale factors at vertices \(i, j\), and \(l_{ij}^0\) is the initial edge length.
Discrete Yamabe flow
At this stage, we have a clear goal: to optimize the scale factors in order to scale the edge lengths and minimize the angle defects across the mesh (i.e. fully flatten the mesh). From here, we use the discreteYamabe flow to meet both of these requirements. Before implementing this algorithm, we began by substituting the scale factors with their logarithms
\(l_{ij} = e^{(u_i + u_j)/2} l_{ij}^0\),
where \(l_{ij}\) is the new intrinsic edge length, \(u_i, u_j\) are the scale factors at vertices \(i, j\), and \(l_{ij}^0\) is the initial edge length. This ensures the new intrinsic edge lengths are always positive and that the optimization is convex.
To implement the algorithm, we followed this procedure:
1. Calculate the initial edge lengths
2. While all angle defects are below a certain threshold epsilon:
Compute the scaled edge lengths
Compute the current angle defects based on the new interior angles based on the scaled edge lengths
Update the scale factors using the step and the angle defects:
\(u_i \leftarrow u_i – h \Omega _i\),
where \(u_i\) is the scale factor of the \(i\)th vertex, \(h\) is the gradient descent step size, and \(\Omega_i\) is the intrinsic angle defect at the \(i\)th vertex.
After running this algorithm and displaying the result, we found that we were able to obtain a perfect conformal flattening of the input mesh (there were no cracks!). There was one issue, however: we needed to manually choose a step size that would work well for the chosen epsilon value. Our next step was to extend our current algorithm by implementing a backtracking line search which would change the step size based on the energy.
Results
Here are two videos demonstrating the Yamabe flow algorithm. The first video illustrates how each iteration of the flow improves the flattened mesh and the second video illustrates how that translates into UV coordinates for texture mapping. We are really happy with how these turned out!
A video visualizing intermediate 2D parameterizations produced by the Yamabe flow.A video visualizing the intermediate UV coordinates on the cat head mesh produced by the Yamabe flow
Line search
To implement this, we added a sub-loop to our existing Yamabe flow procedure which repeatedly test smaller step sizes until one is found which will decrease the energy, e.g., backtracking line search. A good resource on this topic is Stephen Boyd, Stephen P Boyd, and Lieven Vandenberghe. Convex optimization. Cambridge university press, 2004. After resolving a bug in which our step size would stall at very small values with no progress, we were successful in implementing this line search. Now, a large step size could be given without missing the minima.
Newton’s method
Next, we worked on using Newton’s method to improve the descent direction by changing the gradient to more easily reach the minimum. To complete this, we needed to calculate the Hessian — in this case, the Hessian of the discrete conformal energy was the cotan-Laplace matrix \(L\). This matrix had square dimensions (the number of rows and the number of columns was equal to the number of interior vertices) and has off-diagonal entries:
for each edge \(ij\) incident to the \(i\)th vertex.
The newton’s descent algorithm is as follows:
First, build the cotan-Laplace matrix L based on the above definitions
Determine the descent direction \(\dot{u} \in \mathbb{R}^{|V_{\text{int}}|}\), by solving the system \(L \dot{u} = – \Omega\) with \(\Omega \in \mathbb{R}^{|V_{\text{int}}|}\).as the vector containing all of the angle defects at interior vertices.
Run line search again, but with \(\dot{u}\) replacing \(– \Omega\) as the search direction.
This method yielded a completely flat mesh with no cracks. Newton’s method was also significantly faster: on one of our machines, Newton’s method took 3 ms to compute a crack-free parameterization for the cat head model while the original Yamabe flow implementation took 58 ms.
This week I worked on the “Robust computation of the Hausdorff distance between triangle meshes” project with our mentor Dr. Leonardo Sacht, TA Erik Amezquita and my team Talant Talipov and Bryce Van Ross.
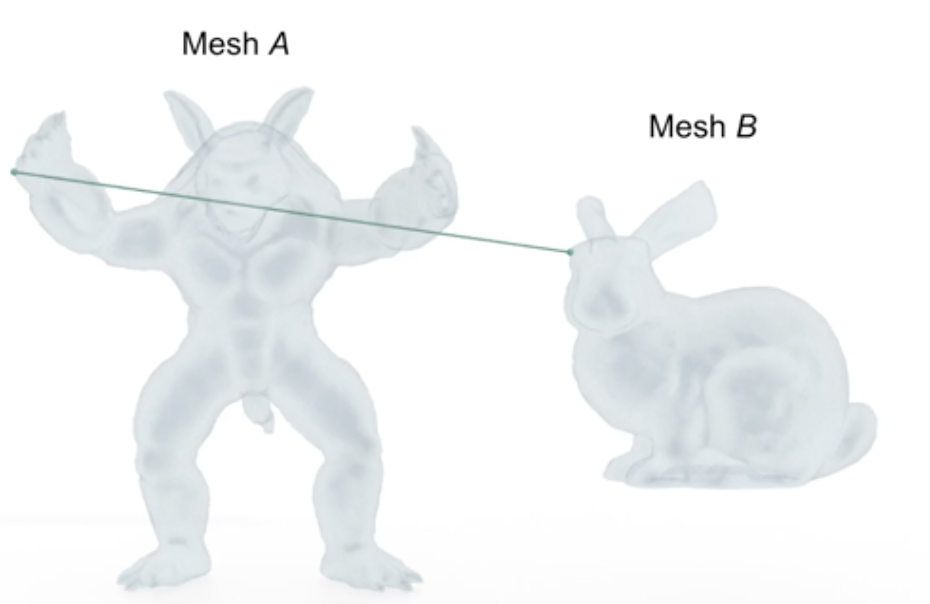
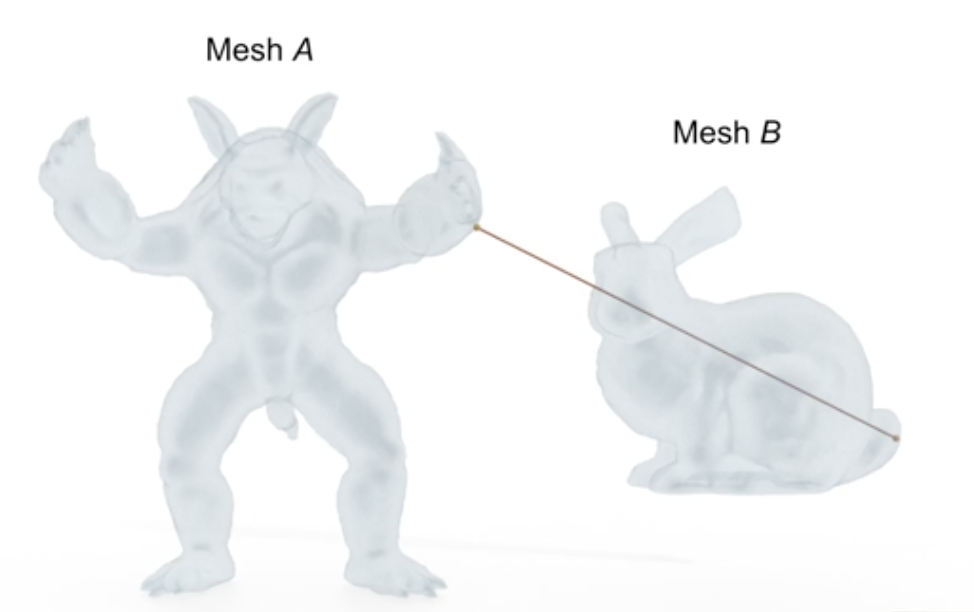
We started our project by doing some initial reading about the topic. Hausdorff distance from triangle meshes A to B is defined as $$h(A,B) = \max_{p \in A}d(p,B)$$ where d is the Euclidean norm. Finding the Hausdorff distance between two triangle meshes is one way of comparing these meshes. We note that the Hausdorff distance from A to B might be different from the Hausdorff distance from B to A, as you can see in the figure below, so it is important to distinguish which one is being computed.
Figure 1: Hausdorff distance from Mesh A to Mesh B
Figure 2: Hausdorff distance from Mesh B to Mesh A
Finally we define $$H(a,b) = \max{h(A,B), h(B,A)}$$ and use this value that is symmetric when comparing triangle meshes A and B.
Our first task was to implement Branch and Bound methods for calculating this distance. Suppose we want to calculate the Hausdorff distance from mesh A to mesh B. There were three main steps in the algorithm to do this: calculation of the upper and lower bound for the Hausdorff distance, and discarding and subdividing triangles according to the values of the upper and lower bound.
The upper bound for each triangle in A is calculated by taking the maximum of the distances from the given triangle to every vertex in B. The lower bound is calculated over A by taking the minimum of the distances from each vertex p in A to the triangle in B that is closest to p. If a triangle in A has an upper bound that is less than the lower bound, the triangle is discarded. After the discarding process, the remaining triangles are subdivided into four triangles and the process is repeated with recalculation of the upper bounds and the lower bound. The algorithm is run until the values for the upper and lower bound are within some ε of each other. Ultimately, we get a triangle region that contains the point that realizes the Hausdorff distance from A to B.
To implement this method, my teammates tackled the upper and lower bound codes while I wrote an algorithm for the discarding and subdividing process:
We ran this algorithm with testing values u = [1;2;3;4;5] and l = 3 and got these results:
Figure 3: Initial mesh
Figure 4: After discarding and subdividing
As expected, the two triangles that had the upper bound of 1 and 2 were discarded and the rest were subdivided.
The lower bound algorithm turned out to be more challenging than we anticipated, and we worked together to come up with a robust method. Currently, we are working on finishing up this part of the code, so that we can run and test the whole algorithm. After this, we are looking forward to extending this project in different directions, whether it is a more theoretical analysis of the topic or working on improving our algorithm!
Note: Although this is an ongoing work, this report documents our progress between the official 2 weeks of the project. (August 2, 2021 – August 13, 2021)
The past 2 weeks at SGI, we have been working with David Palmer on investigating a novel Bayesian approach towards the angular synchronization problem. This blog post is written to document our work and share a sneak peek into our research.
Introduction
Consider a set of unknown absolute orientations \(\{q_1, q_2, \ldots, q_n\}\) with respect to some fixed basis. The problem of angular synchronization deals with the accurate estimation of these orientations from noisy observations of their relative offsets \(O_{i, j}\), up to a constant additive phase. We are particularly interested in estimating these “true” orientations in the presence of many outlier measurements. Our interest in this topic stems from the fact that the angular synchronization problem arises in various avenues of science, including reconstruction problems in computer vision, ranking problems, sensor network localization, structural biology, etc. In our work, we study this problem from a Bayesian perspective, by modelling the observed data as a mixture between noisy observations and outliers. We also investigate the problem of continuous label switching, a global ambiguity that arises from the lack of knowledge about the basis of the absolute orientations \(q_i\). Finally, we experiment on a novel Riemannian gradient descent method for alleviating this continuous label switching problem and provide our observations herein.
Brief Primer on Bayesian Inference
Before going deeper, we’ll briefly discuss Bayesian inference. At the heart of Bayesian inference lies the celebrated Bayes’ rule (read \(a|b\) as “a given b”):
In our problem, \(q\) and \(O\) denote the true orientations that we are estimating and the noisy observations with outliers respectively. We are interested in finding the posterior distribution (or at least samples from it) over the ground truth \(q\) given the noisy observations \(O\).
The denominator (i.e., the evidence or partition function) is an integral over all \(q\)s. Exactly evaluating this integral is often intractable if \(q\) lies on some continuous manifold, as in our problem. This makes drawing samples from the posterior becomes hard.
One way to avoid computing the partition function is a sampling method called Markov Chain Monte Carlo (MCMC). Intuitively, the posterior is approximated by a markov chain whose transitions can be computed using a simpler distribution called the proposal distribution. Successive samples are then accepted or rejected based on an acceptance probability designed to ensure convergence to the posterior distribution in the limit of infinite samples. Simply put, after enough samples are drawn using MCMC, they will look like the samples from the posterior\(P(q|O) \propto P(O|q) \cdot P(q)\) without requiring us to calculate the intractable normalization \(P(O) = \int\limits_q P(O|q)\cdot P(q)\). In our work, we use Hamiltonian Monte Carlo (HMC), an efficient variant of MCMC, which uses Hamiltonian Dynamics to propose the next sample. From an implementation perspective, we use the built-in HMC sampler in Stan for drawing samples.
Mixture Model
As mentioned before, we model the noisy observation as a mixture model of true distribution and outliers. This is denoted by (Equation 1):
where \(\eta_{i j}\) is the additive noise to our true observation, \(q_i q_j^T\) is the relative orientation between the \(i^\textrm{th}\) and \(j^\textrm{th}\) objects, and \(\textrm{Uniform}(\textrm{SO}(D))\) is the uniform distribution over the rotation group \(\textrm{SO}(D)\), representing our outlier distribution. \(\textrm{SO}(D)\) is the space where every element represents a D-dimensional rotation. This mixture model serves as the likelihood \(P(O|q)\) for our Bayesian framework.
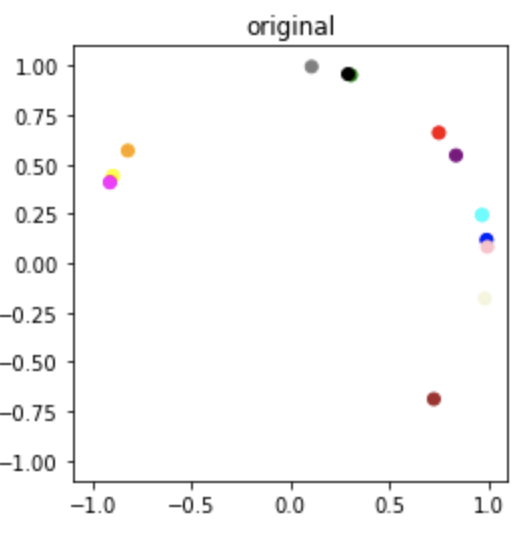
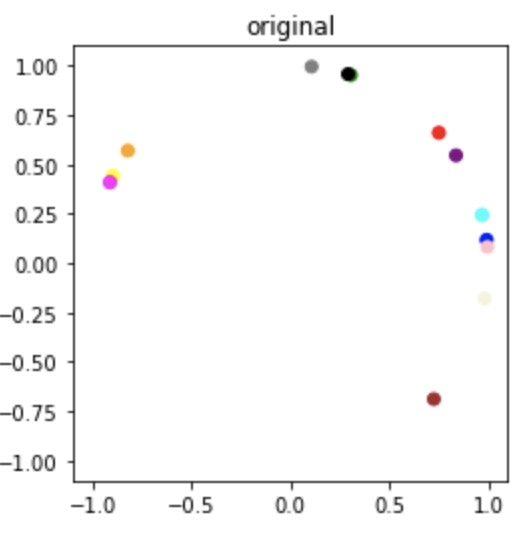
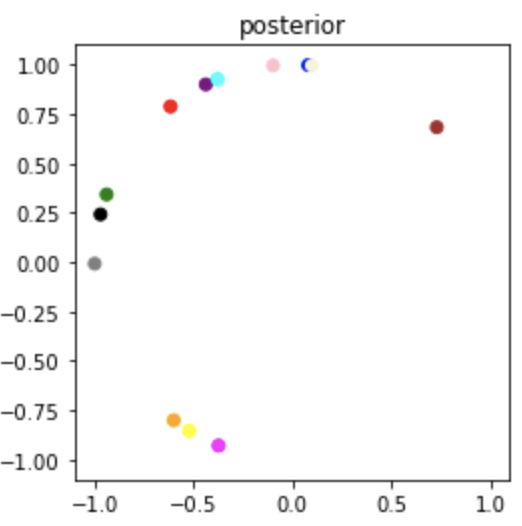
Sampled Result
Ground truth samples of \(q_i\)
\(\hat{q}_i \sim p(q|O)\) (estimated \(q_i\)) sampled from our posterior \(p(q|O)\)
The orientations \(\hat{q}_i\) sampled from the posterior look significantly rotated with respect to the original samples. Notice this is a global rotation since all the samples are rotated equally. This problem of global ambiguity of absolute orientations \(q_i\) arises from the fact that the relative orientations \(q_i q_j^T\) and \(\tilde{q}_i \tilde{q_j}^T\) of two different set of vectors can be the same even if the absolute orientations are different. The following section goes over this and provides a sneak peek into our solution for alleviating this problem.
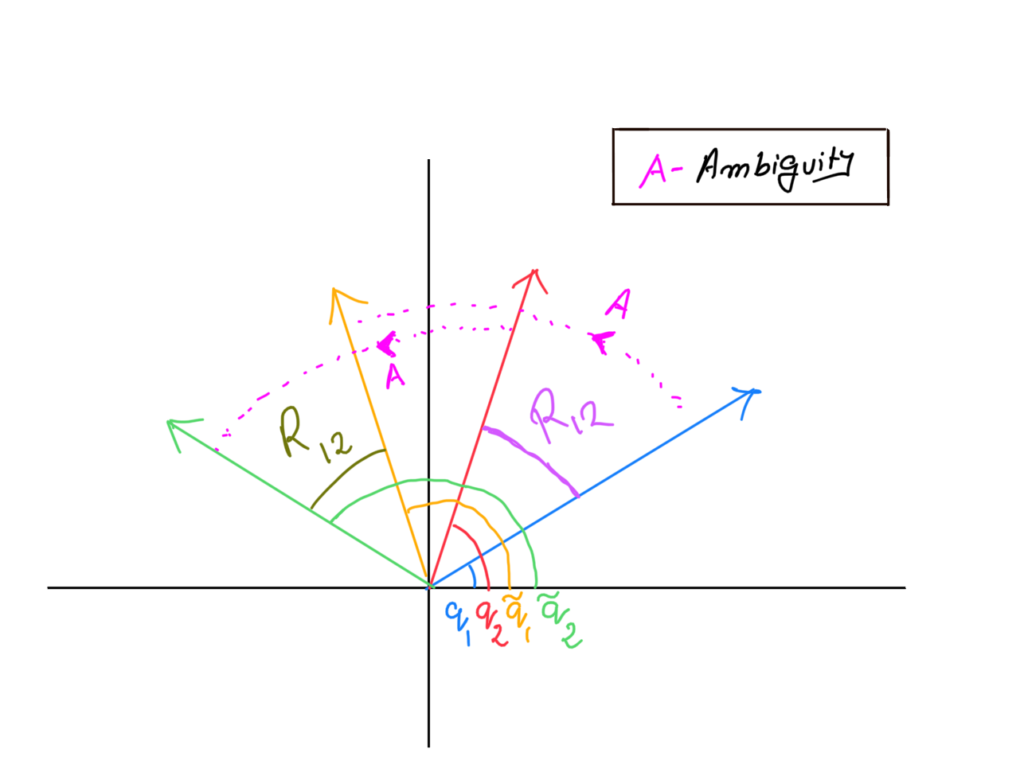
Continuous Label Switching
A careful observation of our problem formulation (Equation 1) would reveal the problem is invariant to transformation of the absolute orientations as long as the relative orientations are preserved. Consider the 2 pairs of observations in the figure below. (Blue and Red; Yellow and Green) Let the absolute orientations be \(q_1\), \(q_2\), \(\tilde{q}_1\) and \(\tilde{q}_2\) and relative orientations between the pairs be \(R_{12}\) and \(\tilde{R}_{12}\). As the absolute orientations \(q_1\) and \(q_2\) are equally rotated by a rotation matrix \(A\), the relative orientation between them \(R_{12}\) is preserved.
More formally, Let \(A \in \textrm{SO}(D)\) be a random orientation matrix in D-dimensions. The following equation demonstrates how rotating two absolute orientations \(q_i\) and \(q_j\) by a rotation matrix \(A\) preserves the relative orientations — which in turn gives rise to a global ambiguity in our framework.
\[
R_{ij} = q_i q_j = q_i A A^T q_j = (q_i A) (A^T q_j) = \tilde{q_i} \tilde{q_j}
\]
Since our inputs to the model are relative orientations, this ambiguity (known as label switching) causes our Bayesian estimates to come randomly rotated by some rotation \(A\).
Proposed Solution
Based on Monteiller et al., in this project we explored a novel solution for alleviating this problem. The intuition is that we believe the unknown ground truth is close to the posterior samples up to a global rotation. Hence we try to approximate the ground truth by starting out with a random guess and optimizing for the alignment map between the estimate and the ground truth. Using this alignment map, and the posterior samples, we iteratively update the guess, using a custom Riemannian Stochastic Gradient Descent over \(\textrm{SO}(D)\).
Algorithm
Start with a random guess \(\mu \sim \mathrm{Uniform}(\mathrm{SO}(D))\).
Sample \(\hat{q} \sim P(q | O)\), where \(P(q | O)\) is the posterior.
Find the global ambiguity \(R\), between \(\hat{q}\) and \(\mu\). This can be obtained by solving for \(\mathrm{argmin}_R \, \| \mu – R \hat{q}\|_\mathrm{F}\).
Move \(\mu\) along the shortest geodesic toward \(\hat{q}\).
Repeat Steps 2 – 4 until convergence. Convergence is detected by a threshold on geodesic distance.
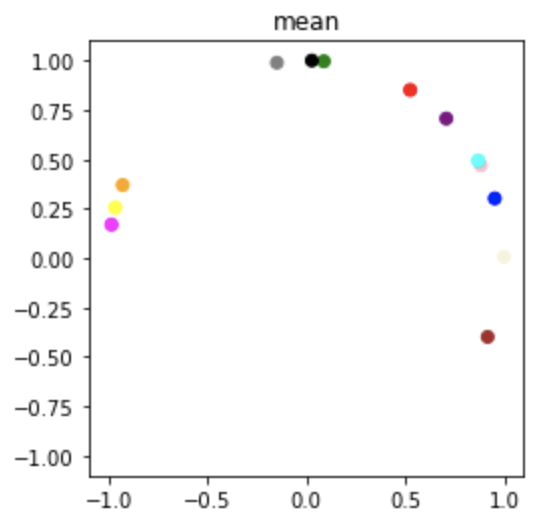
Results
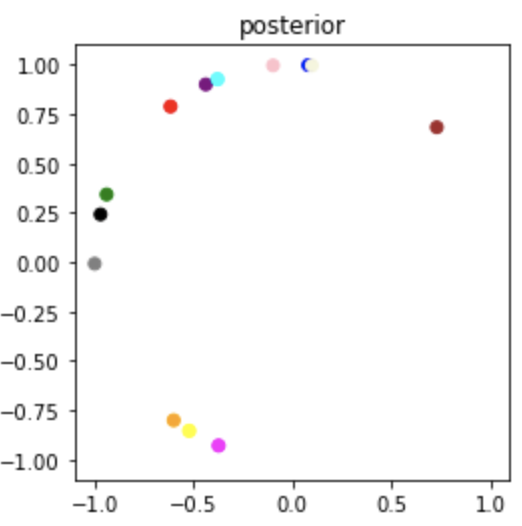
We use this method to estimate the mean of the posterior over \(\mathrm{SO}(2)\) and plot the results (i.e. 2D orientations) in the complex plane as shown below.
Original Sample
Sampled Posterior
Optimized Mean Posterior
The proposed optimization proceedure is able to successfully re-align the posterior samples by alleviating the continuous label switching problem.
Conclusion
In conclusion, we study the rotation synchronisation problem from a Bayesian perspective. We explore a custom Riemannian Gradient Descent procedure and perform experiments in the \(\mathrm{SO}(2)\) case. The current method is tested on a simple toy dataset. As future work we are interested in improving our Bayesian model and benchmarking it against the current state-of-the-art. There are certain performance bottlenecks in our current architecture, which constrain us to test only on \(\mathrm{SO}(2)\). In the future, we are also interested in carrying out experiments more thoroughly in various dimensions. While the current MCMC procedure we are using does not account for the non-Euclidean geometry of the space of orientations, \(\mathrm{SO}(D)\), we are looking into replacing it with Riemannian versions of MCMC.
By Zhecheng Wang, Zeltzyn Guadalupe Montes Rosales, and Olga Guțan
Note: This post describes work that has occurred between August 9 and August 20. The project will continue for a third week; more details to come.
I. Introduction
For the past two weeks we had the pleasure of working with Nicholas Sharp, Etienne Vouga, Josh Vekhter, and Erik Amezquita. We learned about a special type of minimal surfaces: triply-periodicminimal surfaces. Their name stems from their repeating pattern. Broadly speaking, a minimal surface minimizes its surface area. This is equivalent to having zero mean curvature. A triply-periodic minimal surface (TPMS) is a surface in \(\mathbb{R}^{3}\) that is invariant under a rank-3 lattice of translations.
Figure 1. (Left) A Minimal Surface [source] and (right) a TPMS [source].
Let’s talk about nonmanifold surfaces. “Manifold” is a geometry term that means: every local region of the surface looks like the plane (more formally — it is homeomorphic to a subset of Euclidean space). Non-manifold then allows for parts of the surface that do not look like the plane, such as T-junctions. Within the context of triangle meshes, a nonmanifold surface is a surface where more than 3 faces share an edge.
II. What We Did
First, we read and studied the 1993 paper by Pinkhall and Polthier that describes the algorithm for generating minimal surfaces. Our next goal was to generate minimal surfaces. Initially, we used pinned (Dirichlet) boundary conditions and regular manifold shapes. After ensuring that our code worked on manifold surfaces, we tested it on non-manifold input.
Additionally, our team members learned how to use Blender. It has been a very enjoyable process, and the work was deeply satisfying, because of the embedded mathematical ideas intertwined with the artistic components.
III. Reading the Pinkall Paper
“Computing Discrete Minimal Surfaces and Their Conjugates,” by Ulrich Pinkall and Konrad Polthier, is the classic paper on this subject; it introduces the iterative scheme we used to find minimal surfaces. Reading this paper was our first step in this project. The algorithm that finds a discrete locally area-minimizing surface is as follows:
Take the initial surface \(M_0\) with boundary \(∂M_0\) as first approximation of M. Set i to 0.
Compute the next surface \(M_i\) by solving the linear Dirichlet problem $$ \min_{M} \frac{1}{2}\int_{M_{i}}|\nabla (f:M_{i} \to M)|^{2}$$
Set i to i+1 and continue with step 2.
The stopping condition is \(|\text{area}(M_i)-\text{area}(M_{i+1})|<\epsilon\). In our case, we used a maximum number of iterations, set by the user, as a stopping condition.
There are additional subtleties that must be considered (such as “what to do with degenerate triangles?”), but since we did not implement them — their discussion is beyond the scope of this post.
IV. Adding Periodic Boundary Conditions
This is, at its core, an optimization problem. To ensure that the optimization works, the boundary conditions have to be periodic instead of fixed in space. This is because we are enforcing a set of boundary conditions on periodic shapes — that is, tiling in a 3D space.
IV(a). Matching Vertices
First, we need to check every two pairs of vertices in the mesh. We are looking to see if they have identical coordinates in two dimensions, but are separated by exactly two units in the third dimension. When we find such pairs of vertices, we classify them to \(G_x\), \(G_y\), or \(G_z\). Note that we only store unique pairs.
IV(b). Laplacian Smoothness at the Boundary Vertices
Instead of using the discrete Laplacian, now we introduce a sparse matrix K to adjust our smoothness term based on the new boundary:
Next, we construct the matrix K, which is a sparse square matrix of dimension #vertices by #vertices. To do so, we set \(K(i,i) = 1\), \(K(i,j) = 1\), and set the \(j\)th row entries to 0 for every pair of unique matched boundary vertices. For every interior vertex \(i\), we set \(K(i,i) = 1\).
IV(c). Aligning Boundary Vertices
Now we no longer want to pin boundary vertices to their original location in space. Instead, we want to allow our vertices to move, while the opposite sides of the boundary still match. To do that, we need to adjust the existing constraint term and to include additional linear constraints \(Ax=b\).
Therefore, we add two sets of linear constraints to our linear system:
For any pair of boundary vertices distanced by 2 units in one direction, the new coordinates should differ by 2 units.
For any pair of boundary vertices matched in the two other directions, the new coordinates should differ by 0.
We construct a selection matrix \(A\), which is a #pairs of boundary vertices in \(G\) by #vertices sparse matrix, to get the distance between any pair of boundary vertices. For every \(r\)th row, \(A(r,i)=1, A(r,j)=-1.\)$
Then we need to construct 3 \(b\) vectors, each of which is a sparse square matrix of the size [# of vector pairs of boundary vertices in G for a 3D coordinate (x,y,z)]. Based on whether at one given moment we are working with \(G_x\), \(G_y\), or \(G_z\), we enter \(2\) for those selected pairs, and \(0\) for the rest.
V. Correct Outcomes
Below, we can see the algorithm being correctly implemented. Each video represents a different mesh.
VI. Aesthetically Pleasing Bugs
Nothing is perfect, and coding in Matlab is no exception. We went through many iterations of our code before we got a functional version. Below are some examples of cool-looking bugs we encountered along the way, while testing the code on (what has become) one of our favorite shapes. Each video represents a different bug applied onto the same mesh.
VII. Conclusion and Future Work
Further work may include studying the physical properties of nonmanifold TPMS. It may also include additional basic structural simulations for physical properties, and establishing a comparison between the results for nonmanifold surfaces and the existing results for manifold surfaces.
Additional goals may be of computational or algebraic nature. For example, one can write scripts to generate many possible initial conditions, then use code to convert the surfaces with each of these conditions into minimal surfaces. An algebraic goal may be to enumerate all possible possibly-nonmanifold structures and perhaps categorize them based on their properties. This is, in fact, an open problem.
The possibilities are truly endless, and potential directions depend on the interests of the group of researchers undertaking this project further.
Architects often want to create visually striking structures that involve curved materials. The conventional way to do this is to pre-bend materials to form the shape of the desired curve. However, this generates large manufacturing and transportation costs. A proposed alternative to industrial bending is to elastically bend flat beams, where the desired curve is encoded into the stiffness profile of the beam. Wider sections of the beam will have a greater stiffness and bend less than narrower sections of the beam. Hence, it is possible to design an algorithm that enables a designer or architect to plan curved structures that can be assembled by bending flat beams. This is a topic currently being explored by Bernd Bickel and his student Christian Hafner (our project mentor).
A model created using the concept of active bending (source)
For the flat beam to remain bent as the desired curve, we must ensure that the beam assumes this form at its equilibrium point. In Lagrangian mechanics, this occurs when energy is minimised, since this implies that there is no other configuration of the system which would result in lower overall energy and thus be optimal instead. Two different questions arise from this formulation. First, given the stiffness profile \(K\), what deformed shapes \(\gamma\) can be generated? Second, given a curve \(\gamma\), what stiffness profiles \(K\) can be generated? In answering the first problem we will find the curve that will result from bending a beam with a given width profile. However, we are more interested in finding the stiffness profile of a beam which will result in a curved shape \(\gamma\) of our choice. Hence, we wish to solve the second problem.
Below, we will give a full formulation of our main problem, and discuss how we transformed this into MATLAB code and created a user interface. We will conclude by discussing a more generalised case involving joint curves.
Problem formulation
To recap, the problem we want to solve is, given a curve \(\gamma \), what stiffness profiles \(K\) can be generated? For each point \(s\) on our curve \(\gamma: (0,\ell) \to \mathbb{R}^2\), we have values for the position \(\gamma(s)\), turning angle \(\alpha(s)\), and signed curvature \(\alpha'(s)\). In addition, we define the energy of the beam system to be \[W[\alpha] := \int_0^\ell K(s)\alpha'(s)^2 ds,\] where \(K(s)\) is the stiffness at point \(s\). At the equilibrium state of the system, \(W[\alpha]\) will take a minimum value. Intuitively, this implies that, in general, regions of larger curvature will have a lower stiffness. However, it is not true that two different points of equal curvature will have equal stiffness, since there are other factors at play.
Now, before finding the \(K\) that minimises \(W[\alpha]\), we must set additional constraints \[\alpha(0) = \alpha_0, \quad \alpha(\ell) = \alpha_\ell\] and \[\gamma(0) = \gamma_0, \quad \gamma(\ell) = \gamma_\ell.\] In words, we are fixing the turning angles (tangents) and positions of the two boundary points. These constraints are necessary, since they dictate the position in space where the curve begins and ends, as well as the initial and final directions the curve moves in.
We have now formulated a problem that can be solved using variational calculus. Without going into detail, we find that stationary points of this function are given by the equation \[K \kappa = a + \langle b, \gamma \rangle,\] where \(\kappa\) is the signed curvature (previously \(\alpha’\)), and \(a \in \mathbb{R}\) and \(b \in \mathbb{R}^2\) are constants to be found. However, a stiffness profile cannot be generated for all curves \(\gamma\). More specifically, it was shown by Bernd Bickel and Christian Hafner that a solution exists if and only if there exists a line \(L\) that intersects \(\gamma\) exactly at its inflections. With this information in hand, we can begin to create a linear program that computes the stiffness function \(K\).
The top four curves can be created using active bending, but the bottom four cannot (source)
Creating a linear programme
In order to find the stiffness \(K\), we need to solve for the constants \(a\) and \(b\) in the equation \( K \kappa = a + \langle b, \gamma \rangle \), which can be discretised to \[ K(s_i) = \frac{a + \langle b, \gamma(s_i) \rangle }{\kappa(s_i)}.\] It is possible that there is more than one solution to \(K\), so we want some way to determine the “best” stiffness profile. If we think back to our original problem, we want to ensure that our beam is maximally uniform, since this is good for structural integrity. Hence, we solve for \(a\) and \(b\) in the above inequality in such a way that the ratio between maximum and minimum stiffness is minimised. To do this we set the minimum stiffness to an arbitrary value, for example 1, and then constrain \(K\) between 1 and \(M = \text{min}_i K_i\), thus obtaining the inequality \[1 \leq \frac{a + \langle b, \gamma(s_i) \rangle }{\kappa(s_i)} \leq M.\] This can be solved using MATLAB’s linprog function (read the documentation here). In this case, the variables we want to solve for are \(a \in \mathbb{R}\), \(b \in \mathbb{R}^2\), and \(M\) (a scalar we want to minimise). So, using the linprog documentation \(x\) is the vector \((a,b_1,b_2,M)\) and \(f\) is the vector \((0,0,0,1)\), since \(M\) is the only variable we want to minimise. Since linprog only deals with inequalities of the form \(A \cdot x \leq b\), we can split the above inequality into two and write it in terms of the elements of \(x\), like so: \[-\Bigg(\frac{1}{\kappa(s_i)}a + \frac{\gamma_x(s{i})}{\kappa(s_i)}b_1 + \frac{\gamma_y(s_{i})}{\kappa(s_i)}b_2 + 0\Bigg) \leq -1,\] \[\frac{1}{\kappa(s_i)}a + \frac{\gamma_x(s_{i})}{\kappa(s_i)}b_1 + \frac{\gamma_y(s_{i})}{\kappa(s_i)}b_2 -M \leq 0.\] These two equations are of a form that can be easily written into linprog to obtain the values of \(a\), \(b\) and \(M\) and hence \(K\).
User Interface
Once we solved the linear program outlined above, we created a user interface in MATLAB that would allow users to draw and edit a spline curve and see the corresponding elastic strip created in real time. Custom splines can be imported as a .txt file in the following format
or alternatively, the file that is already in the folder can be used. Users can then run the user interface and edit the spline in real time. To add points, simply shift-click, and a new point will be added at the midpoint between the selected point and the next point. The user can right-click to delete a point, and left-click and drag to move points around. If there are zero or one control points remaining, then the user can add a new point where their mouse cursor is by shift-clicking. The number of control points must be greater than or equal to the degree plus one for the spline to be formed. There are certain cases in which the linear program cannot be solved. In these cases the elastic strip is not plotted, and the user must move the control points around until it is possible to create a strip.
Demonstration of the user interface
Here is the link to the GitHub repository, for those who want to try the user interface out.
Joints Between Two or More Strips
The current version of our code is able to generate elastic strips for any (feasible) spline curve generated by the user. However, an as of yet unsolved problem is the feasibility condition for a pair of elastic strips with joints. Solving this problem would allow us compute a pair of stiffness functions \(K_1\) and \(K_2\) that yield elastic strips that can be connected via slots at the fixed joint locations. With a bit of maths we were able to derive the equilibrium equations that would produce such stiffness functions. Suppose the two spline curves are given by \(\gamma_{1}: [0,\ell_{1}] \to \mathbb{R}^2\) and \(\gamma_{2}: [0,\ell_{2}] \to \mathbb{R}^2\) and that they intersect at exactly one point such that \(\gamma_{1}(t_a) = \gamma_{2}(t_b)\). Then we must solve the following two equations: \[ K_{1}(t) \kappa_{1}(t) = \left \{ \begin{array}{ll} a_1 + \langle b_1, \gamma_{1}(t) \rangle + \langle c, \gamma_{1}(t) \rangle & 0 \leq t \leq t_a \\ a_1 + \langle b_1, \gamma_{1}(t) \rangle + \langle c, \gamma_{1}(t_a) \rangle & t_a < t \leq \ell_{1} \end{array}\right. \] \[ K_{2}(t) \kappa_{2}(t) = \left \{ \begin{array}{ll} a_2 + \langle b_2, \gamma_{2}(t) \rangle – \langle c, \gamma_{2}(t) \rangle & 0 \leq t \leq t_b \\ _2 + \langle b_2, \gamma_{2}(t) \rangle – \langle c, \gamma_{2}(t_b) \rangle & t_b < t \leq \ell_{2} \end{array}\right. \]
Similar to the one-spline case, these can be translated into a linear program problem which can be solved. Due to the time constraint of this project, we were not able to implement this into our code and build an associated user interface for creating multiple splines. Furthermore, above we have only discussed the situation with two curves and one joint. Adding more joints would increase the number of unknowns and add more sections to the above piece-wise-defined functions. Lastly, we are still lacking a geometric interpretation for the above equations. All of these issues regarding the extension to two or more spline curves would serve as great inspiration for further research!