A theoretical walkthrough INRs methods for unoriented point clouds
By Alisia Lupidi, Ahmed Elhag and Krishnendu Kar
Hello SGI Community, 👋
We are the Implicit Neural Representation (INR) team, Alisia Lupidi, Ahmed Elhag, and Krishnendu Kar, under the supervision of Dr. Dena Bazazian and Shaimaa Monem Abdelhafez. In this article, we would like to introduce you to the theoretical background for our project.
We based our work on two papers: one about Sinusoidal Representation Network (SIREN[1] ) and one about Divergence Guided Shape Implicit Neural Representation for unoriented point clouds (DiGS[2]), but before presenting these we added a (simple and straightforward) prerequisites section where you can find all the theoretical background needed to understand the papers.
Enjoy!

0. Prerequisites
0.1 Implicit Neural Representation (INR)
Various paradigms have been used to represent a 3D object predicted by neural networks – including voxels, point clouds, and meshes. All of these methods are discrete and therefore pose several limitations – for instance, they require a lot of memory which limits the resolution of the 3D object predicted.
The concept of implicit neural representation (INR) for 3D representation has recently been introduced and uses a signed distance function (SDF) to represent 3D objects implicitly. It is a type of regression problem and consists of encoding a continuous differential signal within a neural network. With INR, we can provide a high resolution for a 3D object with a lower memory footprint, despite the limitations of discrete methods.
0.2 Signed Distance Function (SDF)
The signed distance function[5] of a set in Ω is a metric space that determines the distance of a given point 𝓍 from the boundary of Ω.
The function has positive values for ∀𝓍 ∈ Ω, and this value decreases as 𝓍 approaches the boundary of Ω. On the boundary, the signed distance function is exactly 0 and it takes negative values outside of Ω.
0.3 Rectified Linear Unit (ReLU)
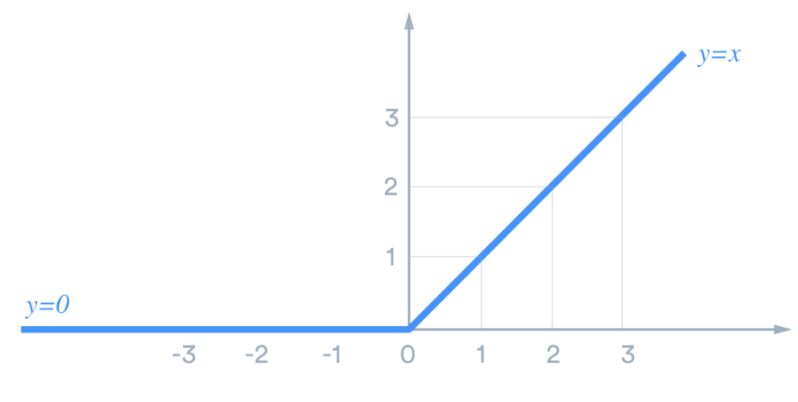
The Rectified Linear Unit (ReLU, Fig. 1) is the most commonly used activation function in deep learning models. The function returns 0 if it receives any negative input, but for any positive value 𝓍, it returns that value. It is defined by f(𝓍) = max(0, 𝓍), where 𝓍 is an input to a neuron.
| ReLU pros | ReLU cons |
| Extremely easy to implement (just a max function), unlike the Tanh and the Sigmoid activation functions that require exponential calculation | Dying ReLU: for all negative inputs, ReLU gives 0 as output – a ReLU neuron is “dead” if it is stuck in the negative side (not recoverable). |
| The rectifier function behaves like a linear activation function | Non-differentiable at zero |
| Can output a true zero value | Not zero-centered and unbounded |
0.4 Multilayer Perceptron (MLP)
A multilayer perceptron (MLP)[6] is a fully connected class of feedforward artificial neural network (ANN) that utilizes backpropagation for training (supervised learning). It has at least three layers of nodes: an input layer, a hidden layer and an output layer, and except for the first layer, each node is a neuron that uses a nonlinear activation function.
A perceptron is a linear classifier that takes in input 𝓎 = ∑ Wᵢ𝓍ᵢ + bᵢ where 𝓍 is the feature vector, W are the weights, and b the bias. This input, in some cases such as SIREN, is passed to an activation function to produce the bias (see equation 5).
1.SIREN
1.1 Sinusoidal Representation Network (SIREN)
SIRENs[1] are neural networks (NNs) used for signals’ INRs. In comparison with other networks’ architectures, SIRENs can represent a signal’s spatial and temporal derivatives, thus conveying a greater level of detail when modeling a signal, thanks to their sine-based activation function.
1.2 How does SIREN work?
We want to learn a function Φ that satisfies the following equation and is limited by a set of constraints[1],
This above is the formulation of an implicit neural representation where F is our NN architecture and it takes as input the spatio-temporal coordinates 𝓍 ∈ ℝm and the derivatives of Φ with respect to 𝓍. This feasibility problem can be summarized as[1],
As we want to learn Φ, it makes sense to cast this problem in a loss function to see how well we accomplish our goal. This loss function penalizes deviations from the constraints on their domain Ωm[1],

Here we have the indicator function 1Ωm= 1 if 𝓍 ∈ Ωm and otherwise equal to 0.
All points 𝓍ᵢ are mapped to Φ(𝓍) in a way that minimizes its deviation from the sampled value of the constraint aᵢ(𝓍). The dataset D = {(𝓍ᵢ, aᵢ(𝓍))}ᵢ is sampled dynamically at training time using Monte Carlo integration. The aim of doing this is to improve the approximation of the loss L as the number of samples grows.
To calculate Φ, we use θ parameters and solve the resulting optimization problem using gradient descent.[1]
Here θi ∶ ℝ→ ℝNi is the ith layer of the network. It consists of the affine transform defined by the weight matrix Wi ∈ ℝNi x Mi and the biases bi ∈ ℝNi applied on the input 𝓍ᵢ ∈ ℝMi. The sine acts as the activation function and it was chosen to achieve greater resolution: a sine activation function ensures that all derivatives are never null regardless of their order (the sine’s derivative is a cosine, whereas a polynomial one would approach zero in a number of derivations related to its grade). A polynomial would thus lose higher order frequencies and therefore render a model with less information.
1.3 Examples and Experiments
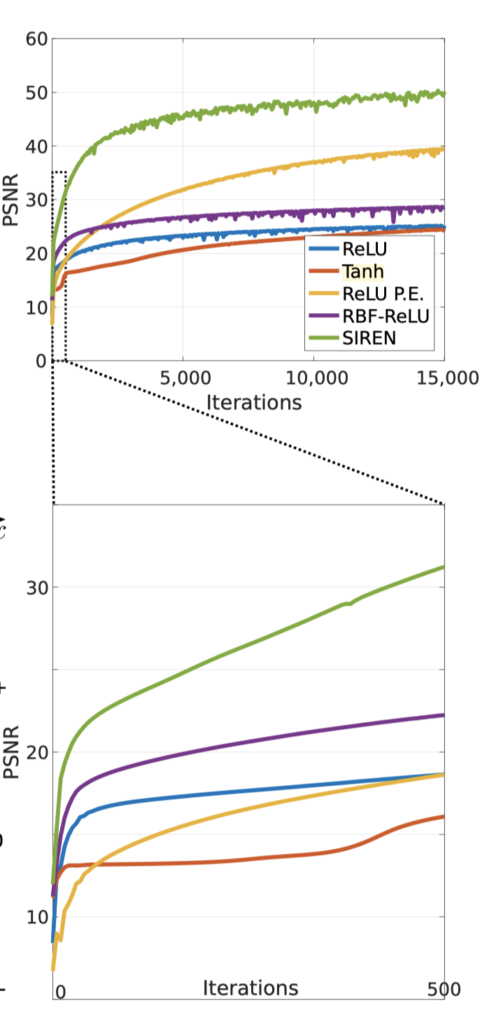
In the paper[1], the authors compared SIREN performances to the most popular network architectures used-like Tanh, ReLU, Softplus, etc. Conducting experiments on different signals (picture, sound, video, etc), we can see that SIREN outperforms all the other methods by a significant margin (i.e., it reconstructs the signal with higher accuracy, Fig. 2).
To appreciate all of SIREN’s potential, it is worth mentioning that we can look at the experiment the authors did on an oriented point cloud representing a 3D statue and on shape representation with differentiable signed distance functions (Fig. 3).
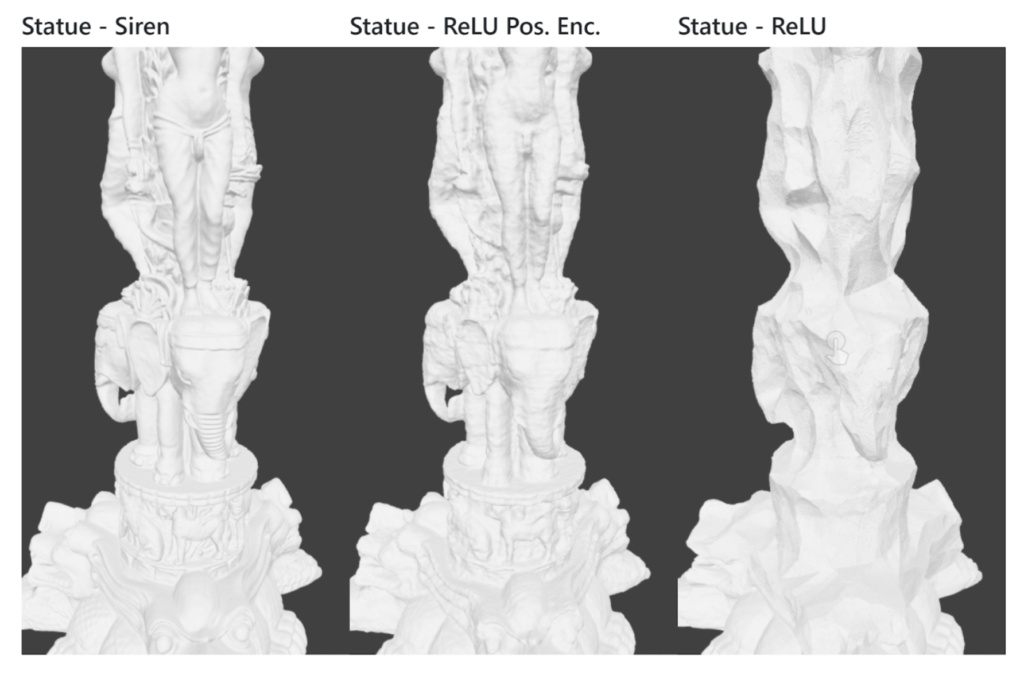
By applying SIREN to this problem, they were able to reconstruct the whole object while accurately reproducing even the finer details on the elephant and woman’s bodies.
The whole scene is stored in the weights of a single 5-layer NN.
Compared to recent procedures (like combining voxel grids with neural implicit representations) with SIREN, we have no 2D or 3D convolutions and fewer parameters.
What gives SIREN an edge over other architectures is that: it does not compute SDFs using supervised GT SDF or occupancy values. Instead, it requires supervision in the gradient domain, so even though it is a harder problem to solve, it results in a better model and more efficient approach.
1.4 Conclusion on SIREN
SIREN is a new and powerful method in the INR world that allows 3D image reconstructions with greater precision, an increased amount of details, and smaller memory usage.
All of this has been possible thanks to a smart choice of the activation function: using the sine gives an edge on the other networks (Tanh, ReLU, Sigmoid, etc) as its derivatives are never null and retrieve information even at higher frequency levels (higher order derivatives).
2. DiGS
2.1 Divergence Guided Shape Implicit Neural Representation for unoriented point clouds (DiGS)
Now that we know what SIREN is, we present DiGS[2]: a method to reconstruct surfaces from point clouds that have no normals.
Why are normals important for INR? When normal vectors are available for each point in the cloud, a higher fidelity representation can be learned. Unfortunately, most of the time normals are not provided with the raw data. DiGS is significant because it manages to render objects with high accuracy in all cases, thus bypassing the need for normals as a prior.
2.2 Training SIRENs without normal vectors
The problem has now changed into training a SIREN without supplying the shape’s normals beforehand.
Looking at the gradient vector field of the signed distance function produced by the network, we can see that it has low divergence nearly everywhere except for sink points – like in the center of the circle in Fig. 4. By incorporating this geometric prior as a soft constraint in the loss function, DiGS reliably orients gradients to match the unknown normals at each point and in some cases this produces results that are even better than those produced by approaches that use directly GT normals.
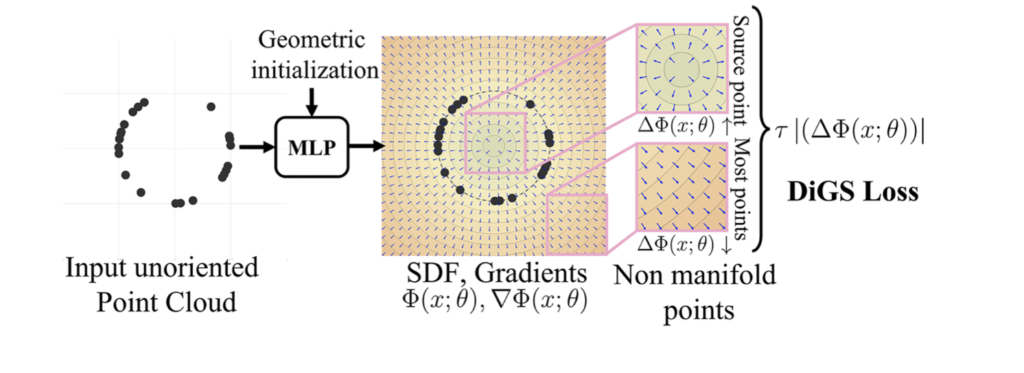
To do this, DiGS requires a network architecture that has continuous second derivatives, such as SIRENs, and an initial zero level set that is approximately spherical. To achieve the latter, two new geometric initialization methods are proposed: the initialization to a sphere and the Multi-Frequency Geometric Initialization (MFGI). The MFGI is better than the first because the first keeps all activations within the first period of the sinusoidal activation function and this will not generate high-frequency outputs, thus losing some detail. The second one, however, introduced controlled high frequencies into the first layer of the NN, and even though is a noisier method it solves the aforementioned problem.
To train SIRENS with DiGS, firstly we need a precise geometric initialization. Initializing the shape to a sphere biases the function to start with an SDF that is positive away from the object and negative in the center of the object’s bounding box, while keeping the model’s ability to have high frequencies (in a controllable manner).
Progressively, finer and finer details are added into consideration, passing from a smooth surface to a coarse shape with edges. This step-by-step approach allows the model to learn a function that has smoothly changing normals and that is interpolated as much as possible with the original point cloud samples.
The original SIREN loss function includes:
- A manifold constraint: points on the surface manifold should be on the function’s zero-level set[2],
- A non-manifold penalization constraint because of which all off-surface point have SDF = 0 [2],
- An Eikonal term that defines all gradients to have unit length[2],
- A normal term that forces the gradients’ directions of points on the surface manifold to match the GT normals’ directions[2],
The original SIREN’s loss function is[2]
With DiGS, the normal term is replaced by a Laplacian one that imposes a penalty on the magnitude of the divergence of the gradient vector field.[2]
This leads to a new loss function which is equivalent to regularizing the learn loss function:[2]
2.3 Examples and Experiments
| Iterations | 0 | 50 | 2000 | 9000 |
| DiGS |  |  |  |  |
| SIREN |  |  |  |  |
In Fig. 5, both SIREN and DiGS were tasked with the reconstruction of a highly detailed statue of a dragon for which no normals were provided. The outputs were color mapped: in red, you can see the approximated solution, and in blue the reconstructed points match exactly with the ground truth.
At iteration 0, we can appreciate the spherical geometrical initialization required by DiGS. At first, it seems that SIREN converges faster and better to the solution: after 50 iterations, in fact, SIREN already has the shape of the dragon whereas DiGS has a potato-like object.
But as the reconstruction progresses, SIREN gets stuck on certain areas and cannot derive them. This phenomenon is known as “ghost geometries” (see Fig 6) as no matter how many iterations we do INR architectures cannot reconstruct these areas. This means that our results will always have irrecuperable holes. DiGS is slower but can overcome ghost geometries: after 9k iterations, DiGS manages to recover data for the whole statue – irrecuperable areas included.

2.4 Conclusion on DiGS
In general, DiGS behaves as good as (if not better) than other state-of-the-art methods with normal supervision and can also overcome ghost geometries and deal with unoriented point clouds.
3. Conclusions
Being able to reconstruct shapes from unoriented point clouds expands our ability to deal with incomplete data, which is something that often occurs in real life. As point clouds dataset without normals is more common than those with normals, the advancements championed by SIREN and DiGS will greatly facilitate 3D model reconstruction.
Acknowledgements
We want to thank our supervisor Dr. Dena Bazazian, and our TA Shaimaa Moner, for guiding us through this article. We also want to thank Dr. Ben-Shabat for his kindness in answering all our questions about his paper.
References
[1] Sitzmann, V., Martel, J., Bergman, A., Lindell, D. and Wetzstein, G., 2020. Implicit neural representations with periodic activation functions. Advances in Neural Information Processing Systems, 33, pp.7462-7473.
[2] Ben-Shabat, Y., Koneputugodage, C.H. and Gould, S., 2022. DiGS: Divergence guided shape implicit neural representation for unoriented point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 19323-19332.
[3] Liu, D., 2017, A Practical Guide to ReLU [online], https://medium.com/@danqing/a-practical-guide-to-relu-b83ca804f1f7 [Accessed on 26 July 2022].
[4] Sitzmann, V., 2020, Implicit Neural Representations with Periodic Activation Functions [online], https://www.vincentsitzmann.com/siren/, [Accessed 27 July 2022].
[5] Chan, Tony, and Wei Zhu. “Level set based shape prior segmentation.” 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05). Vol. 2. IEEE, 2005.
[6] Hastie, Trevor, et al. The elements of statistical learning: data mining, inference, and prediction. Vol. 2. New York: springer, 2009.
[7] anucvml, 2022, CVPR 2022 Paper: Divergence Guided Shape Implicit Neural Representation for Unoriented Point Clouds [online], https://www.youtube.com/watch?v=bQWpRyM9wYM, Available from 31 May 2022 [Accessed 27 July 2022].