Authors: Sana Arastehfar, Erik Ekgasit, Maria Stuebner
This is a follow up to a previous blogpost. We recommend that you read the previous post before this one.
We devoted our second week to exploring three methods of ensuring temporal consistency between runs of the Latent-NeRF code:
1. fine-tuning
2. retraining a model halfway through
3. deforming Latent-NeRFs with NeRF-Editing.
The overall aim was to keep certain characteristics of the generated images, for example, of a Lego man, consistent between runs of the code. If the following tests were run:
- Lego man
- Lego man holding a sword
we would want the Lego man to retain his original colors, hair, and features except for his originally raised hand which we would want to now be lowered slightly and holding a sword.
If we tested for a color change, for example, such as
- red Lego man
- green Lego man
we would want the Lego man to retain exactly the same geometry between runs, with only the color of the Lego man changing as noted by the change in text guidance. After discussing ways in which to go about achieving this temporal consistency, we each decided to explore a different method, as outlined below.
1. Fine-tuning
Experimental Setup
The experiments were conducted using the same sketch and text prompt as a basis for animation generation. Different variations of the text prompts and sketch guides were used to observe the changes in the generated animations. The generated animations were evaluated based on color consistency, configuration accuracy, and adherence to the provided prompts.
Consistency Analysis
The initial experiments revealed that the model demonstrated remarkable consistency when animating a Lego man holding a sword (Figure 1). Even when the text prompt was altered to depict a teddy holding a sword (Figure 2), the generated animations still maintained accurate depictions, both in color and shape, demonstrating the model’s robustness.
Figure 1: Latent NeRF with sketch guide + text guide “a lego man holding a sword”
Figure 2: Latent NeRF output with a sketch guide and text prompt “a teddy bear holding a sword”.
Influence of Text Prompt and Sketch Guide
Figure 3 presented two different results when using the same shape guidance but different text prompts: “a Lego man” and “a Lego man with left arm up.” This indicated that the text prompt had a more significant impact on the final animation results than the sketch guide.
Figure 3: latent NeRF outputs using the same sketch guide, different text prompts. “a lego man” (left), and “a lego man with left arm up” (right), demonstrating the weight of text guide in latent NeRF.
Animation Sequence and Consistency To investigate the model’s ability to maintain consistency in an animation sequence, a series of runs were conducted where a Lego man attempted to raise the sword. After four runs, the sword’s color became inconsistent, and after the fifth run, the sword was no longer present (Figure 4).
Figure 4: Prompt: “lego man holding a sword” with different sketch shapes. The 10 sketch shapes for man animation of a humanoid figure holding a sword and raising their arm.
Fine-Tuning Techniques
Three fine-tuning techniques were attempted to enhance the model’s performance on the same sketch shape guide and text prompt:
a. Full-Level Fine-Tuning
Full-level fine-tuning is a technique used in transfer learning, where an entire pre-trained model is fine-tuned on a new task or dataset. This process involves updating the weights of all layers in the model, including both lower-level and higher-level layers. Full-level fine-tuning is typically chosen when the new task significantly differs from the original task for which the model was pre-trained.
In the context of generating animations of a Lego man holding a sword, full-level fine-tuning was employed by using the weights obtained from a run where the generated animations had a completely visible sword. These weights were then utilized to fine-tune the model on runs where the generated animations had no swords. The outcome of this fine-tuning process showed a visible sword in the generated animations, but the boundary for the configuration of the Lego man appeared less-defined as observed in Figure 5. This suggests that while the model successfully retained the ability to depict the sword, some aspects of the Lego man’s configuration might have been compromised during the fine-tuning process. Fine-tuning at the full level can be advantageous when dealing with highly dissimilar tasks, but it also requires careful consideration of potential trade-offs in preserving specific features while adapting to the new task.
Figure 5: The output of sketch guided and text guided “a lego man holding a sword”, where the sword was no longer visible (left) and full level fine tuning output (right).
b. Less Noise Fine-Tuning We performed fine-tuning on the stable diffusion model by increasing the number of training steps. The idea behind this was to take advantage of increased interactions between the model and the input data during training, as larger time steps can provide a better understanding of complex patterns. Surprisingly, this approach resulted in a decline in both configuration and color consistency in the generated animations, as evidenced in Figure 6.
Figure 6: The output of Latent-NeRF after altering the training steps from 1000 to 2000 in the stable diffusion.
In an effort to improve the model’s performance, we experimented with adjusting the noise level in the generated data. Originally, the noise level gradually decreased from the start to the end of training. However, we decided to explore an alternative approach using the squared cosine as a beta scheduler to stabilize training and potentially enhance the quality of generated samples. Unfortunately, this adjustment led to even further degradation in both configuration and color consistency, as shown in Figure 7.
Figure 7: Changing the beta schedule from “scaled_linear” to “squaredcos_cap_v2” in Stable Diffusion.
These results indicate that finding an optimal balance between noise level and training steps is crucial when fine-tuning the stable diffusion model. The complex interplay between these factors can significantly impact the model’s ability to maintain configuration and color consistency. Further research and experimentation are needed to identify the most suitable combination of hyperparameters for this specific generative model.
c. Freeze Layers
Freezing layers during fine-tuning is a widely used technique to retain learned representations in specific parts of the model while adapting the rest to new data or tasks. In our experiment involving the pre-trained model for “the Lego man holding a sword,” we employed this approach to leverage the visible sword results and enhance the performance on the scenario where the sword was not visible.
To achieve this, we selectively froze layers from different networks responsible for color and background. However, the outcomes were mixed. When we froze the sigma network layer, we observed a visible sword in the generated animations. However, there was a trade-off as the configuration of the Lego man suffered, and the depiction became less defined as shown in Figure 8.
Figure 8: Freezing sigma network layers, you can see the before this fine tuning (top) there are no swords, and after fine tuning (bottom) there is a phantom of the sword.
On the other hand, freezing the background layer led to a different outcome. While the Lego man’s configuration was better preserved, the generated animations lacked the complete depiction of the Lego man and appeared incomplete as depicted in Figure 11.
These results suggest that freezing specific layers can have both positive and negative impacts on the generated animations. It’s important to strike a balance when deciding which layers to freeze, as it can greatly influence the final performance of the model. Fine-tuning a generative model with frozen layers requires careful consideration of the specific characteristics of the task and the trade-offs between preserving existing knowledge and adapting to new data. Further experimentation is necessary to identify the optimal configuration for freezing layers in order to achieve the best results in future fine-tuning endeavors.
Conclusion
The study explored the consistency and fine-tuning techniques of a generative model capable of animating a Lego man holding a sword. The model demonstrated high consistency when generating animations based on different prompts and sketch guides. However, fine-tuning techniques had varying effects on the model’s performance, with some approaches showing improvements in certain aspects but not others. Further research is necessary to achieve more reliable and consistent fine-tuning methods for generative animation models.
2. Can you retrain a NeRF midway through training?
The second approach was to modify text/shape guidance halfway through a training set, with the motivation of ensuring consistency of the elements not changed in the guidance. The idea between this method was to somehow “save” the initial conditions of the trained NeRF from the original text and/or geometry guidance so that the second set of text/geometry instructions would change only the minimal elements needed to align with the new guidance. To test this approach, we looked at three types of changes: 1) a change in the text guidance only, 2) a change in the geometry guidance, and 3) a change in both instructions.
Changing Text Guidance
When only the text guidance was changed, as shown in the modification to the aforementioned lego_man configuration file below,
log:
exp_name: 'lego_man'
guide:
text: 'a red lego man'
text2: 'a green lego man'
shape_path: shapes/teddy.obj
optim:
iters: 10,000
seed: 10
render:
nerf_type: 'latent'the NeRF was able to retrain to the new text guidance with some difficulty. The results below show a snapshot of the final result of the text guidance “a red lego man” and “a green lego man”, as well as the final 3D video of the green lego man. They show how although there are still some remnants of red in the green lego man and the design of his outfit had slightly changes, the basic geometry of the lego man as well as the design in white on the red lego man and then in black on the green lego man is unchanged:


Changing Geometry Guidance
When only the geometry guidance was changed, as shown in the lego_man configuration file below,
log:
exp_name: 'lego_man'
guide:
text: 'a lego man'
shape_path: shapes/teddy.obj
shape_path2: shape/raise_sword.obj
optim:
iters: 10,000
seed: 10
render:
nerf_type: 'latent'the NeRF had more difficulties retraining to match the new geometry of the lego man holding a sword. We show the two object files below that were used for these runs.


The results below show a snapshot of the final result of using the teddy.obj file for geometry guidance and then using the raise_sword.obj file, as well as the final 3D video of the second run using the raise_sword.obj file:


Changing Both
When both the text and geometry guidance were changed, as shown below,
log:
exp_name: 'lego_man'
guide:
text: 'a lego man'
text2: 'a lego man holding a sword'
shape_path: shapes/teddy.obj
shape_path2: shape/raise_sword.obj
optim:
iters: 10,000
seed: 10
render:
nerf_type: 'latent'the NeRF was able to retrain to the new guidance with less difficulty than in the case of the only using geometry guidance, yet the sword itself is somewhat translucent, and the outfit of the lego man changed from the original tuxedo look of the first run:


In conclusion, although these runs show promise for this approach of retraining a NeRF halfway through, they also indicate that there are certain initial conditions that either change completely in the retraining of the NeRF, or that inhibit the NeRF from being able to generate an accurate retrained 3D figure that corresponds to the new text and/or geometry guidance. Additionally, training data indicates that the learning curve for NeRFs may complicate the approach of retraining, as the NeRF learns certain final details only at the very end of training.
3. Deforming Latent-NeRFs with NeRF-Editing
Background
Since NeRFs are functions that provide the color and volume density of a scene at a given 3D point, they do not directly generate images. Instead, a NeRF needs to be rendered just like a triangle mesh or other 3D representation would. This is done using a volumetric rendering algorithm. For each pixel in the image, a ray is shot from the camera. The color and volume density is sampled along the ray the pixel’s color is computed from those values.
Nerf-Editing is a method that can be used to deform NeRFs. It extracts a triangle mesh from the surface of the NERF which the user can edit using whatever tools they desire. The original triangle mesh is then used to create a corresponding tetrahedral mesh. Then, the deformation of the triangle mesh is transferred to the tetrahedral mesh. This results in an original and deformed tetrahedral mesh. When the NeRF is rendered, rays are shot into the scene and points on the deformed tetrahedral mesh are sampled. Instead of sampling the NeRF at that point, the NeRF is sampled at the corresponding point on the undeformed mesh. This gives the NeRF the appearance of deformation when it is rendered to an image.
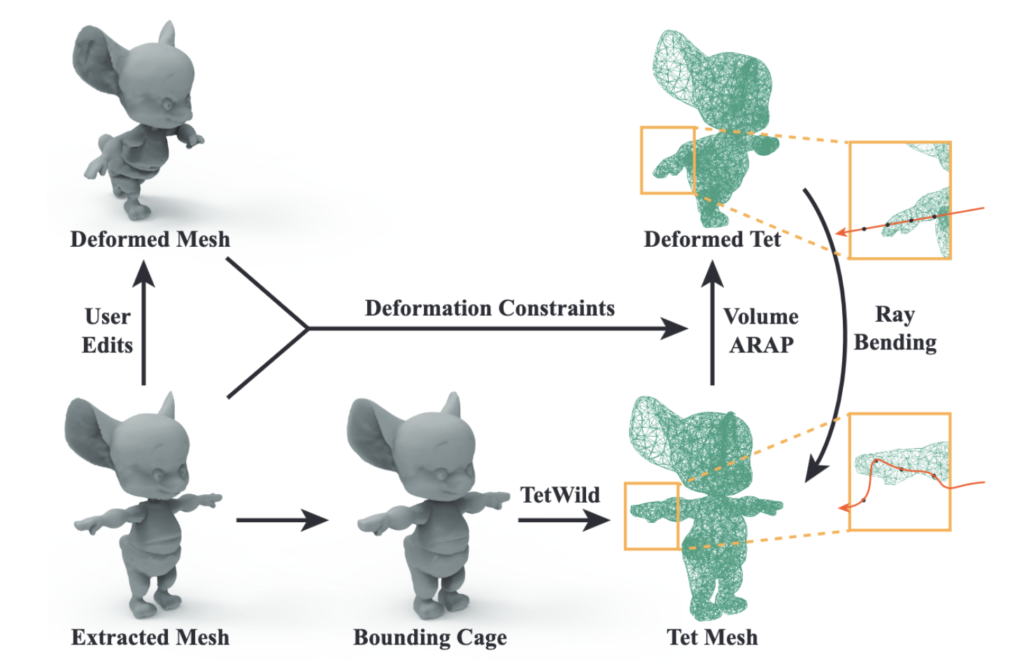
Figure: An overview of NeRF-Editing.
Proposed Process
Latent-NeRF can be guided with a sketch-shape. Ideally a user would able to deform the sketch shape and get a deformed NeRF back. We start with a sketch-shape and train a corresponding Latent-NeRF. We then put the trained NeRF into NeRF-Editing. Instead of extracting a triangle mesh to get an editable representation of the NeRF, we simply use the sketch-shape. The user edits the sketch-shape. We tetrahedralize the original sketch-shape and create a corresponding deformed tetrahedral shape. We then render the NeRF by sampling points on the deformed shape and then sampling the NeRF in the corresponding un-deformed location. It would be interesting to see whether the sketch shape would be enough to guide the deformation instead of a mesh extracted from the NeRF itself.
Challenges
The main challenge is that there are many different NeRF architectures since there are many ways to formulate a function from points in space and view direction to color and volume density. Latent-NeRF uses an architecture called Instant-NGP which stores visual features in a data structure called a hash grid and uses a small neural network to decode those features into color and volume density. NeRF-Editing uses a backend called NeuS. NeuS is an extension on the original NeRF method, which utilized one massive neural network, and embedded a signed distance function better define the boundaries of shapes. In theory, NeRF-Editing’s method is architecture agnostic, but the implementation of Instant-NGP into NeRF-Editing was too time consuming for the 2-week project timeline.