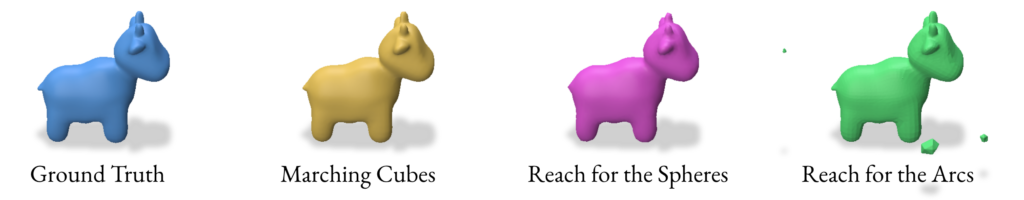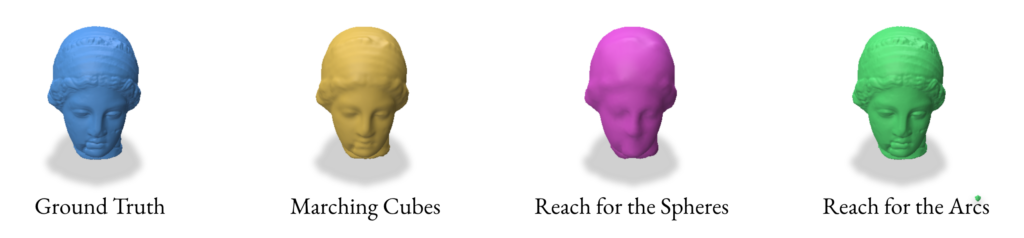Students: Eleanor Wiesler, Sara Samy, Juan Serratos
Collision detection is an important problem in interactive computer graphics and physics-based simulation that seeks to determine if, when and where two or more objects come into contact. [4] In this project, we implement bounded deformation trees (BD-Trees) and adapt this method to represent complex deformations of any geometry as linear superpositions of displacement fields.
Mesh deformationsusing modal analysis
When an object collides with a surface, we should expect the object to deform in some way, e.g. if a bouncing ball is thrown against a wall or dropped from a building, it should momentarily be “squished” or flattened at the site of collision. This is the effect we aim to accomplish using modal analysis.
We start with a manifold triangular mesh e.g. Spot the cow, and tetrahedralize it using the python library of TetGen, a Delaunay-based tetrahedral mesh generator. [1] The resulting mesh is given as a \((V, C)\), where \(C\) is a set of tetrahedral cells whose vertices are in \(V\), as shown in Figure 1 below.
Figure 1: Tetrahedral mesh of Spot.
We use the Physics Based Animation Toolkit (PBAT) to compute the free vibrational modes of our model. Physically, one can describe vibration as the oscillatory motion of a physical structure, induced by energy exchanges of the potential (elastic deformation) and the kinetic (moving mass) energies. Vibrations are typically classified as either free or forced. In free vibrations, there are no continuous external forces acting on the structure, e.g. when a guitar string is plucked, while forced vibrations result from ongoing external forces. By looking at these free vibrations, we can determine the natural frequencies and normal modes of the structure.
First, we convert our geometricmesh into a FEM mesh and compute its Jacobian determinants and gradients of its shape function. You can check the documentation to learn more about FEM meshes.
Using these FEM quantities, we can model a hyperelastic material given its Young’s modulus \(Y\), Poisson’s ratio \(\nu\) and mass density \(\rho\).
rho = 1000.
Y = np.full(mesh.E.shape[1], 1e6)
nu = np.full(mesh.E.shape[1], 0.45)
# Compute mass matrix
M = pbat.fem.MassMatrix(mesh, detJeM, rho=rho, dims=3, quadrature_order=2).to_matrix()
# Define hyperelastic potential
hep = pbat.fem.HyperElasticPotential(mesh, detJeU, GNeU, Y, nu, energy=pbat.fem.HyperElasticEnergy.StableNeoHookean, quadrature_order=1)
Now we compute the Hessian matrix of the hyperelastic potential, and solve the generalized eigenvalue problem \(Av = \lambda M v\) using SciPy, where \(A\) denotes the Hessian matrix (a real symmetric matrix) and \(M\) denotes the mass matrix.
import scipy as sp
# Reshape matrix of vertices into a one-dimensional array
vs = mesh.X.reshape(mesh.X.shape[0]*mesh.X.shape[1], order="f")
hep.precompute_hessian_sparsity()
hep.compute_element_elasticity(vs)
HU = hep.hessian()
leigs, Veigs = sp.sparse.linalg.eigsh(HU, k=30, M=M, sigma=-1e-5, which="LM")
The resulting eigenvectors represent different deformation modes of the mesh. They can be animated as time continuous signals, as shown in Figure 2 below.
Figure 2: Six different deformation modes of Spot. Notice how each mode is characterized by deformations in a different local site of the mesh like its legs or neck.
Reduced Deformation Models
The BD-Tree paper [2] introduced the bounded deformation tree, which can perform collision detection for reduced deformable models at similar costs to standard algorithms for rigid bodies. But what do we mean exactly by reduced deformable models? First, unlike rigid bodies, where collisions affect only the position or movement of the object, deformable bodies can dynamically change their shape when forces are applied. Naturally, collision detection is simpler for rigid bodies than for deformable ones. Second, instead of explicitly tracking every individual triangle in a mesh, reduced deformable models represent complex deformations efficiently by a smaller set of parameters. This is achieved by using a linear superposition of pre-computed displacement fields that capture the essential ways a model can deform.
Suppose we have a triangular mesh with \(|V| = n\). Let \(\boldsymbol{p} \in \mathbb{R}^{3n}\) denote the undeformed vertices locations, and let \(U \in \mathbb{R}^{3n \times r}\) be a matrix with \(r \ll n\). Then the new deformed vertices location \(\boldsymbol{p’}\) are approximated by a linear superposition of \(r\) displacement fields given by the columns of \(U\) such that
where the amplitude of each displacement field is determined by the reduced coordinates \(\boldsymbol{q} \in \mathbb{R}^{r}\). Both \(U\) and \(\boldsymbol{q}\) must already be known in advance. In our case, the columns of \(U\) are the eigenvectors obtained from modal analysis described earlier, although they could also result from methods, e.g. an interpolation process. The reduced coordinates \(\boldsymbol{q}\) could also be determined by some possibly non-linear black box process. This is important to note: although the shape model is linear, the deformation process itself can be arbitrary!
Bounded deformation trees
Welzl’s algorithm
The BD-Tree works by constructing a hierarchy of minimum bounding spheres. As a first step, we need a method to construct the smallest enclosing sphere for some set of points. Fortunately, this problem has been well studied in the field of computational geometry, and we can use the randomized recursive algorithm of Welzl [3] that runs in expected linear time.
The Welzl’s algorithm is based on a simple observation: assume a minimum bounding sphere \(S\) has been computed a set of points \(P\). If a new point \(p\) is added to \(P\), then \(S\) needs to be recomputed only if \(p\) lies outside of \(S\), and the new point \(p\) must lie on the boundary of the new minimum bounding sphere for the points \(P \cup \{p\}\). So the algorithm keeps track of the set of input points and a set of support, which contains the points from the input set that must lie on the boundary of the minimum bounding sphere.
Sphere WelzlSphere(Point pt[], unsigned int numPts, Point sos[], unsigned int numSos)
{
// if no input points, the recursion has bottomed out.
// Now compute an exact sphere based on points in set of support (zero through four points)
if (numPts == 0) {
switch (numSos) {
case 0: return Sphere();
case 1: return Sphere(sos[0]);
case 2: return Sphere(sos[0], sos[1]);
case 3: return Sphere(sos[0], sos[1], sos[2]);
case 4: return Sphere(sos[0], sos[1], sos[2], sos[3]);
}
}
// Pick a point at "random" (here just the last point of the input set)
int index = numPts - 1;
// Recursively compute the smallest bounding sphere of the remaining points
Sphere smallestSphere = WelzlSphere(pt, numPts - 1, sos, numSos);
// If the selected point lies inside this sphere, it is indeed the smallest
if(PointInsideSphere(pt[index], smallestSphere))
return smallestSphere;
// Otherwise, update set of support to additionally contain the new point
sos[numSos] = pt[index];
// Recursively compute the smallest sphere of remaining points with new s.o.s.
return WelzlSphere(pt, numPts - 1, sos, numSos + 1);
}
The BD-Tree Method
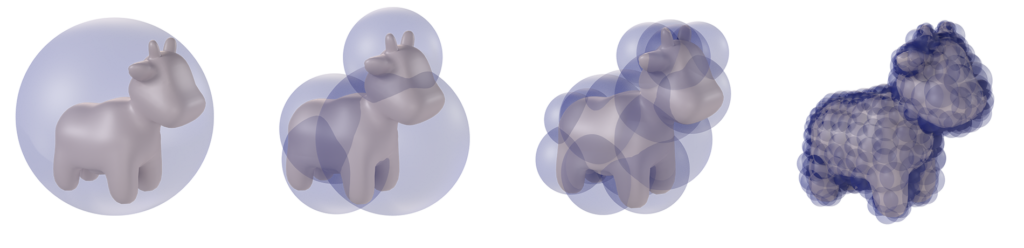
Figure 3: Wrapped BD-Tree for Spot at increasing recursion levels.
Now that we can compute the minimum bounding spheres for any set of points, we are ready to construct a hierarchical sphere tree on the undeformed model, after which it can be updated following deformation. First we note that the BD-Tree is a wrapped hierarchy, wherein the bounding spheres tightly enclose the underlying geometry but any bounding sphere at one level need not contain its child spheres. This is different from a layered hierarchy in which spheres must enclose their child spheres, but can fit the underlying geometry more loosely (see Figure 4).
Figure 4: An illustration—re-created from [2] of the wrapped hierarchy (left) and layered hierarchy (right). The underlying geometry is shown in green with five vertices and four edges.
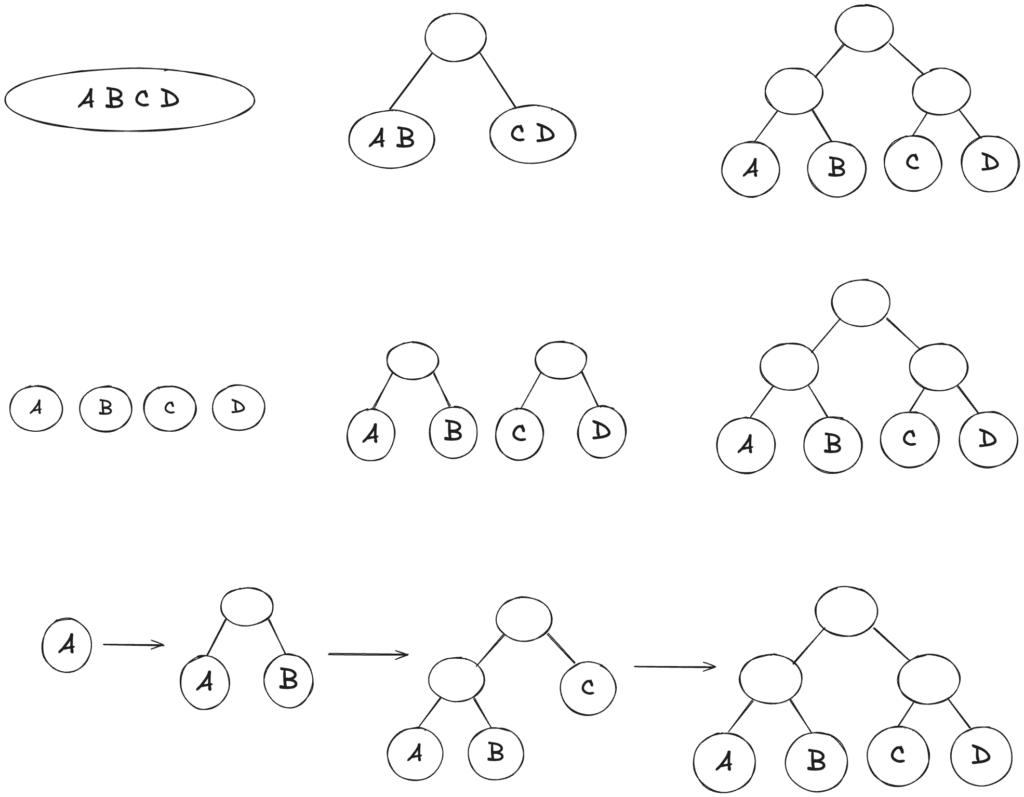
As shown in Figure 5, there are many possible approaches to building a binary tree. In our case, we use a simple top-down approach while partitioning the underlying geometry, i.e. we recursively split Spot at its median into two parts with respect to its local coordination axes, such that a leaf node (the lowest level) contains only one triangle.
Figure 5: Hierarchical binary tree construction with four objects using a top-down (top), bottom-up (middle) and insertion approach (bottom).
As the object deforms, how do we compute the new bounding spheres quickly and efficiently?
Let \(S\) denote a sphere in the hierarchical tree with center \(c\) and radius \(R\) containing the \(k\) points of the geometry \(\{p_{i}\}_{1 \leq i \leq k}\). After the deformation, the center of the sphere \(c\) is displaced by a weighted average of the contained points’ displacements \(u_{i}\) with weights \(\beta_i\) e.g. \(\beta_i := 1/k\) for \(1 \leq i \leq k\). So the new center can be expressed as
\(\displaystyle c’ = c + \sum_{i = 1}^{k} \beta_i u_i.\)
Using the displacement equation above, we can write \(u_i\) as the sum \(\sum_{j = 1}^{r} U_{ij} q_{j}\) and substitute this into the previous equation to obtain:
\(\displaystyle c’ = c + \sum_{j = 1}^{r} \left(\sum_{i = 1}^{k} \beta_i U_{ij}\right) q_j = c + \bar{U} \boldsymbol{q}.\)
To compute the new radius \(R’\), we make use of the triangle inequality
Thus, we have an updated bounding sphere \(S’\) with its center \(c’\) and radius \(R’\) computed as functions of the reduced coordinates \(\boldsymbol{q}\).
Figure 6: Spot colliding with ground plane. The colors of the spheres change based on the ratio of \(R\) in the undeformed state to \(R’\) in the deformed state.
References
[1] Hang Si. TetGen, a Delaunay-based quality tetrahedral mesh generator. ACM Transactions on Mathematical Software, 41(2), 2015.
[2] Doug L. James and Dinesh K. Pai. BD-Tree: Output-Sensitive Collision Detection for Reduced Deformable Models. ACM Transactions on Graphics, 23(3), 2004.
[3] Emo Welzl. Smallest enclosing disks (balls and ellipsoids). New Results and New Trends in Computer Science, 555, 1991.
[4] Christer Ericson. Real-Time Collision Detection. CRC Press, Taylor & Francis Group. Chapter 4, p. 99-100. 2005.
Simulations often become unstable as a result of self-intersection or intersection between two meshes. This instability can lead to wrong simulation results and incorrect outputs. At the same time, self and inter collisions of meshes are a necessity for artistic purposes in cases such as 3D animation. To resolve this issue, Baraff et al. (2003) reveals a method known as global intersection analysis, which specifies how to resolve these mesh intersections while allowing the simulation to run as it normally would. This ensures that we obtain simulation stability while also allowing for mesh intersections when required.
The goal
For the sake of our one week project time period, our project focussed on creating a simple implementation of the global intersection analysis algorithm along with a simple resolution method between two different meshes.
The global intersection analysis algorithm required a few steps:
Identify a contour along which both meshes intersect each other
Identify the points inside and outside this contour for both mesh
Use these points to resolve the intersections by adding a constraint that “pulls” them out of each other (subsequently resolving the intersection)
Allow the physics solver to run as it normally would after resolution of intersection.
The global intersection analysis algorithm, which would perform the steps above
Our physics solver, which would run an XPBD algorithm for the cloth to follow
Integrating both these systems together in terms of the constraints needed for the cloth XPBD to take intersection resolution into account.
For our demo scene, we used a simple rigid ball and a tesselated plane to act as a cloth mesh.
Both test meshes with their intersection contour
Contour Identification and Flood Filling
For our GIA implementation, we created a scene which identifies a contour, identifies the points inside and outside and provides this data as output for further processing.
Points identified as inside and outside on the cloth mesh
Points identified as inside and outside the contour along the ball mesh
Our identification of points is done through a flood fill algorithm.
The original method mentioned by Baraff et al. (2003) discusses selecting the region with lesser area, determining that to be the area inside the contour and then flood filling from inside this smaller area and larger area with two separate colors to identify both regions on the mesh. It isn’t entirely clear how to choose a point in this area or how to determine this area solely from the contour. As a result, we created and implemented our own method for the flood fill which works well in our current test cases.
Our method follows standard flood filling techniques, where we identify a point on the surface with one color, then recursively repeat the coloring process to all points connected to the last one. To identify if a point is across the contour, we change the color if the edge that connects two points is identified as one that intersects with the edges on the contour.
To make this more efficient, we identify contour intersecting edges beforehand. We also colored any points along the contour beforehand to ensure the flood fill would not overwrite or mistake those points. As a heuristic, we also begin the flood fill along any identified points along the contour since pre-coloring a point means the flood fill algorithm will not continue if all points adjacent to a point are colored.
We utilised the IPC Toolkit [3] to perform intersection operations between the surface and contour edges.
XPBD Implementation
Using Matthias Müller’s implementation[2] as reference, we also implemented an XPBD cloth simulator.
Our cloth dangling by a few points on it’s top edges
We provide various parameters to change as well, such as the simulation time step and cloth properties.
Integration
To integrate both systems, the most important part was integrating the GIA collision resolution into the cloth mesh’s XPBD constraint formulation. For simplicity, we push away the cloth in a force whose direction is the vector from center of the cloth contour points and the ball mesh contour points. This way, we would have a close-enough approximation to push the cloth away. We then integrate this constraint into the system, where we identify and assign this force direction for the cloth after performing a GIA call. One GIA call would perform a contouring, vertex identification and force direction identification before assigning it to the cloth’s constraint. The cloth’s XPBD solver would then take this into account when determining the next position of points on the cloth.
Result
The results of our integration can be seen here.
The UI also allows user to play around with different simulation settings and options.
To get a look into the source code, our GitHub repository can be found here.
Scope for improvement
Given our 1 week period, there are some areas for improvement.
Our current GIA implementation is too slow to be used in realtime and can be made faster.
Our intersection resolution method is not what is exactly outlined in the original “Untangling cloth” paper but a rough approximation. Baraff et al. (2003) provide a much more precise method to determine per vertex resolution along the meshes.
XPBD may not be the most accurate simulator of cloth (though for an application such as animation, it works well enough visually).
Our GIA flood fill can sometimes identify vertices incorrectly, leading to inaccuracies in the mesh-intersection resolution.
References
[1] Baraff, D., Witkin, A., & Kass, M. (2003). Untangling cloth. ACM Transactions on Graphics, 22(3), 862–870. https://doi.org/10.1145/882262.882357
[2] Matthias Müller. pages/tenMinutePhysics/15-selfCollision.html at master · matthias-research/pages. GitHub. https://github.com/matthias-research/pages/blob/master/tenMinutePhysics/15-selfCollision.html
[3] IPC Toolkit. https://ipctk.xyz/
This blog was written by Sachin Kishan as one of the outcomes of a project during the SGI 2024 Fellowship under the mentorship of Zachary Ferguson.
A spline is a function that usually represents a piecewise polynomial. Splines have a variety of applications, from being used to visualize a curve to representing motion in animation, to model a surface, or for artistic visualizations.
Our project on Arc Length Splines aimed to satisfy a new necessity in spline formulation- an analytically computable arc length. We aim to allow users to output the arc length and further constrain the spline using the arc length. Further, we want to ensure some amount of continuity on the spline.
Background
Continuity
In the context of splines, continuity can be defined as having no sudden change in value across the spline function. There are two kinds of continuity discussed here, namely parametric (C) and geometric (G) continuity.
There are different levels of continuity dubbed C1 continuity, C2 continuity, and so on until Cn continuity. (The same applies to G as well)
A Ci continuous spline is defined as one where for a function f(t) that defines the spline, f i (t) is continuous for all points t, where i represents the order of the derivative. This is usually true for each curve that is in the spline. The points of interest where continuity may not occur are at the points where two curves meet, called the joints. To verify if there is continuity at the joints, we can use the following method:
Assume we have two curves A and B where the endpoint of A is connected to the starting point of B. These curves are parameterized on the domain [0,1].
A and B form a Ci continuous spline if
Ai (1) = Bi (0)
This can be used to verify any spline made of an arbitrary number of curves, given that for every two consecutive curves connected at a joint, they satisfy the above condition.
Any Ci spline is also C0, C1 … Ci-2, Ci-1continuous.
Gi continuity is based on the “geometric” smoothness of the curve. Where G1 is the continuity at the tangents along the spline. G2 continuity refers to the continuty of the curvature along the spline.
Continuity plays an important role in how a spline’s application may behave. For example, if a spline is acting as a path for an object moving along it, if the spline is not C1 continuous (meaning each consecutive curve has an endpoint that meets at the joint of the spline but with discontinuities for the first differential), the spline may not be useful. This is because objects would likely move at different speeds along different curves(or increase and decrease in speed at the joints.) This is what makes continuity a desirable property in spline applications.
Approximating vs interpolating control points
Splines can be changed based on their control points. Splines that go through the entire set of control points are called interpolating splines (since they interpolate between the entire given set of control points). In an approximating spline, the spline approximates the polyline made by the control points into a smooth curve.
Local and Global control
Based on the constraints on the spline formulation, the control points have influence over certain parts of the spline. In cases where a control point only effects the curve at which it acts as a joint (or is the point that directly decides how two curve segments are to be formed), the spline is said to have control points with local control. (Local being the curves before and after the control point at a joint).
In some cases, constraints may influence larger parts of the spline beyond local curves, this is referred to as global control.
It is usually desirable to have local control for applications like spline drawing, where we want to create a curve of a certain visual form without largely impacting the rest of the spline it is a part of.
Arc Length
Arc length is the distance along the curve given two points on the curve. For any arbitrary curves, arc length can be integrated between two points. For special curves such as circles or parabolas, there is an analytically computed arc length. Our choice of curve and interpolation schemes to explore were driven by where we could analytically calculate arc length for a curve. This also influenced other considerations of our spline.
Past Work
Most of our inspiration came from the paper “A Class of C^2 Interpolating Splines” by Cem Yuksel(2020). Yuksel was able to classify four different types of splines that maintained C^2 continuity and interpolation. These were splines using the Bézier interpolation function, circular interpolation function, elliptical interpolation function, and hybrid (circular-elliptical) interpolation function. Yuksel(2020) used a combination of the base curve and a blending function to maintain continuity.
The use of a blending function is excellent for ensuring continuity between different kinds of curves. However, our goal is to have an exact arc length. The function Yuksel(2020) uses was a second order trigonometric function. Thus, there was no closed formula for the arc-length of for the blending function.
Our work
After initial review of past literature- we compiled a set of curves in which an analytical solution for arc length exists. We dived deeper into curves which have closed formula arc length. The main curves of this family are circles, parabolas, catenoids, and the logarithmic spiral. We then focussed on creating splines out of this initial set of curves. Through this process, we recognised that circular curves may be the best option, not only because their arc length is easy to calculate, but presented properties to create a locally controllable spline with C1 continuity.
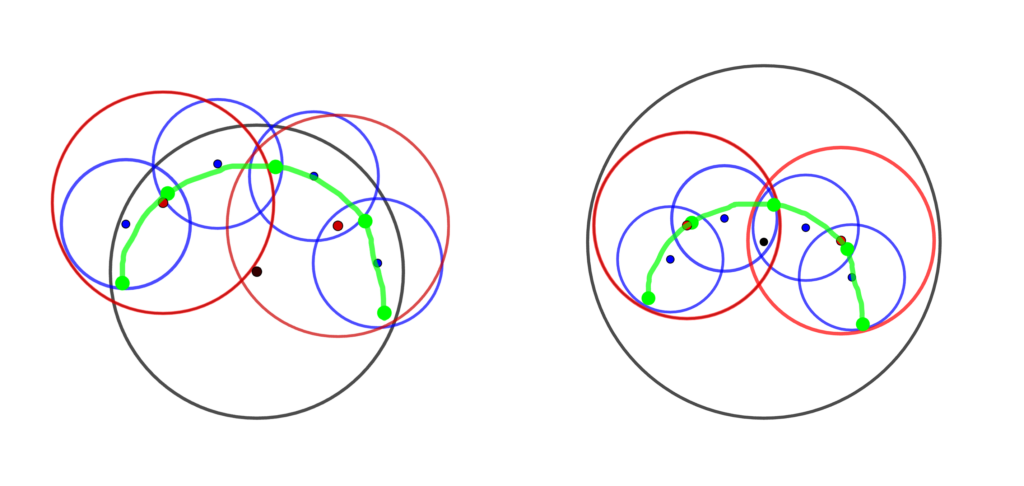
A spline is formed when we connect an endpoint of two curves to each other. To formulate a circular spline, there are different ways to connect them. One option was to just draw line segments between two arcs. The problem is that this may not always be continuous if further constraints are not provided.
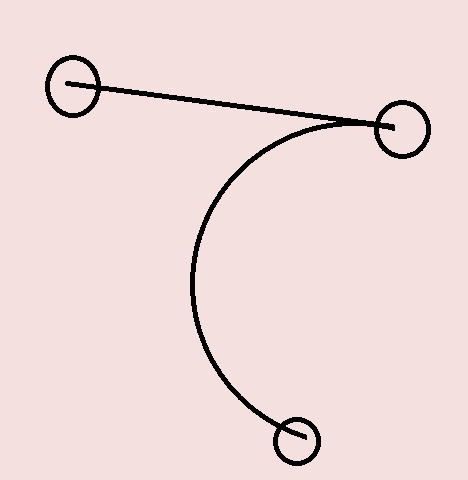
Another way to connect two circular arcs is to use the Dubins Path. Dubins Paths are usually used in robotics or car path planning. Since they are used to find the shortest path between any two curves which have constraints on curvature, they work perfectly to find a connecting path between two circular arcs.
Dubin’s path between two circular arcs, which turns out to be a line segment. Source: Salix Alba [2]
If a line segment between two curves is not a line segment, Dubin’s path instead form it’s own curve to draw between the two. These are known as CCC paths (where C stands for curve).
Dubin’s path between two circular arcs, which turns out to be another circular arc. Source: Salix Alba [3]
This ensures we no longer constrain user outcome and provide additional output for a user to adjust visually. The arc length of a Dubins path can also be computed analytically. This is because in all possible cases of a Dubins path, the path will either be a line segment or another circular arc. This allows for the analytical calculation of arc length across the entire spline while also ensuring C1 continuity. This fits with our requirements for an arc-length computable spline retaining at least a C1 continuity property.
We then worked on implementing the idea above: a set of circular arcs whose spline is formed with the dubins path connecting them.
To implement circular arcs, we used two points and a tangent from one of them to determine a circular arc. This would equate to 3 points used per arc. Using a set of 6 points (which form 2 circular arcs), we then create a path between them.
Our current implementation allows for the creation of circular arcs with straight paths formed between them.
Our implementation in python. Each arc is made of three points and is connected by a line segment
Future work
Our current implementation is limited, we intend to improve it in the following ways:
Ensure a Dubins path for all cases of circular arcs
Create arc length constraints as well as outputs for users to view and edit
Better interface to clearly demarcate between different curves, tangent points and circular arc points.
Implementing higher order continuity while ensuring lesser constraints on spline editing.
References
[1] Cem Yuksel. 2020. A Class of C2 Interpolating Splines. ACM Trans. Graph. 39, 5, Article 160 (October 2020), 14 pages. https://doi.org/10.1145/3400301
[2] Salix Alba (2016, 6 February) Dubins3.svg https://upload.wikimedia.org/wikipedia/commons/e/e7/Dubins3.svg
[3] Salix Alba (2016, 6 February) Dubins2.svg https://upload.wikimedia.org/wikipedia/commons/e/e7/Dubins2.svg
[4] Freya Holmér. (2022, December 7). The continuity of Splines [Video]. YouTube. https://www.youtube.com/watch?v=jvPPXbo87ds
This blog was written by Sachin Kishan and Brittney Fahnestock during the SGI 2024 Fellowship as one of the outcomes of a project under the mentorship of Sofia Wyetzner and the support of Shanthika Naik as teaching assistant.
Signed Distance Functions (SDFs) are widely used in computer graphics for rendering and animation. They provide an implicit representation of shapes, which can be converted to explicit representations using methods such as Marching Cubes (MC) and, more recently, Reach for the Spheres (RfS) [Sellan et al. 2023]. However, as we will demonstrate later in this blog post, SDFs have certain limitations in representing various types of surfaces, which can affect the quality of the resulting explicit representations.
Vector Distance Functions (VDFs) [Gomes and Faugeras, 2003] offer a promising alternative, with the potential to overcome some of these limitations. VDFs extend the concept of SDFs by incorporating directional information, allowing for more accurate representation of complex geometries.
This study explores both SDF and VDF-based reconstruction methods, comparing their effectiveness and identifying scenarios where each approach excels. By examining these techniques in detail, we aim to provide insights into their respective strengths and weaknesses, guiding future applications in computer graphics and geometric modeling.
2.0 Reconstruction from SDF
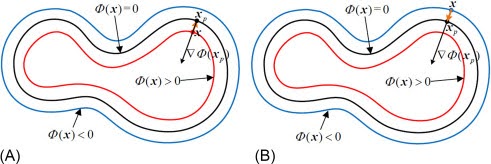
SDFs are one method of representing a surface implicitly. They involve assigning a scalar value to a set of points in a volume. The sign of the SDF value indicates whether the point is inside (-ve) or outside (+ve) the shape, while the magnitude represents the distance to the nearest point on the surface
Mathematically, an SDF \(f(x)\) for a surface \(S\) can be defined as:
$$ f(x) = \begin{cases} -\min_{y \in S} |x – y| & \text{if } x \text{ is inside } S\\ 0 & \text{if } x \text{ is on } S\\ \min_{y \in S} |x – y| & \text{if } x \text{ is outside } S \end{cases} $$
Where, \(|x-y|\) denotes the Euclidean distance between points \(x\) and \(y\).
2.1 Extracting SDF
To reconstruct a surface from an SDF, we first need to obtain SDF values for a set of points in space. There are two main approaches we’ve implemented for sampling these points:
Random Sampling – Generating uniformly distributed random points within a bounding box that encompasses the mesh. This ensures a broad coverage of the space but may miss fine details of the surface.
Proximity-based Sampling – Generating points near the surface of the mesh. This method provides a higher density of samples near the surface, potentially capturing more detail. We implement this by first sampling the points and then adding Gaussian noise to these points.
def extract_sdf(sample_method: SampleMethod, mesh, num_samples=1250000, batch_size=50000, sigma=0.1):
v, f = gpy.read_mesh(mesh)
v = gpy.normalize_points(v)
bbox_min = np.min(v, axis=0)
bbox_max = np.max(v, axis=0)
bbox_range = bbox_max - bbox_min
pad = 0.1 * bbox_range
q_min = bbox_min - pad
q_max = bbox_max + pad
if sample_method == SampleMethod.RANDOM:
P = np.random.uniform(q_min, q_max, (num_samples, 3))
elif sample_method == SampleMethod.PROXIMITY:
P = gpy.random_points_on_mesh(v, f, num_samples)
noise = np.random.normal(0, sigma * np.mean(bbox_range), P.shape)
P += noise
sdf, _, _ = gpy.signed_distance(P, v, f)
return P, sdf
gpy.random_points_on_mesh() generates points on the mesh surface and gpy.signed_distance() computes the SDF values for the sampled points.
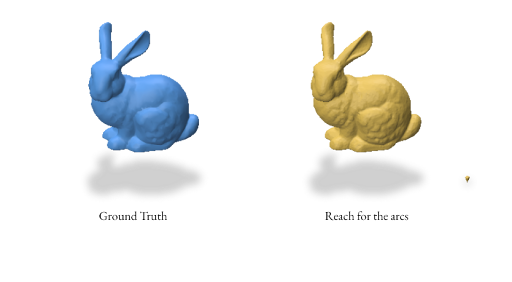
Here’s an example reconstruction using both random and proximity-based sampling for the bunny mesh using the Reach for the Arcs Algorithm:
2.2 Reconstruction using Marching Cubes
Marching Cubes is a classic algorithm for extracting a polygonal mesh from an implicit function, such as an SDF. The algorithm works by dividing the space into a regular grid of cubes and then “marching” through these cubes to construct triangles that approximate the surface.
The key steps of the Marching Cubes algorithm are:
Divide the 3D space into a regular grid of cubes.
For each cube:
Evaluate the SDF at each of the 8 vertices.
Determine which edges of the cube intersect the surface (where the SDF changes sign).
Calculate the exact intersection points on the edges using linear interpolation.
Connect these intersection points to form triangles based on a predefined table of cases.
How we implement the marching cubes algorithm in our project:
We first define a bounding box that encompasses all sample points.
We create a regular 3D grid within this bounding box.
We interpolate SDF values onto this regular grid using scipy.interpolate.griddata.
We use the skimage.measure.marching_cubes function to perform the actual Marching Cubes algorithm.
Finally, we scale and translate the resulting vertices back to the original coordinate system.
The Marching Cubes algorithm uses a look-up table to determine how to triangulate each cube based on the sign of the SDF at its vertices. There are 256 possible configurations, which can be reduced to 15 unique cases due to symmetry.
One limitation of the Marching Cubes algorithm is that it can miss thin features or sharp edges due to the fixed grid resolution. Higher resolutions can capture more detail but at the cost of increased computation time and memory usage.
In the next sections, we’ll explore more advanced reconstruction techniques that aim to overcome some of these limitations.
2.3 Reconstruction using Reach for the Spheres
Reach for the Spheres (RFS) is a surface reconstruction method introduced by Sellan et al. in 2023. Unlike Marching Cubes, which operates on a fixed grid, RFS iteratively refines an initial mesh to better approximate the surface represented by the SDF. The key idea behind RFS is to use local sphere approximations to guide the mesh refinement process.
The key steps of the RFS algorithm are:
Start with an initial mesh (typically a low-resolution sphere).
For each vertex in the mesh:
Compute the local reach (maximum sphere radius that doesn’t intersect the surface elsewhere).
Move the vertex to the center of this sphere.
Refine the mesh by splitting long edges and collapsing short ones.
Repeat steps 2-3 for a fixed number of iterations or until convergence.
For a vertex \(v\) and its normal \(n\), the local reach \(r\) is computed as:
$$ r = \arg\max_{r > 0} { \forall p \in \mathbb{R}^3 : |p – v| < r \Rightarrow f(p) > -r } $$
Where \(f(p)\) is the SDF value at point \(p\). The new position of the vertex is then:
$$v_{new} = v + r \cdot n$$
How we implement the RFS algorithm in our project:
def reach_for_spheres(self, num_iters=5):
v_init, f_init = gpy.icosphere(2)
v_init = gpy.normalize_points(v_init)
sdf_func = lambda x: griddata(self.pts, self.sdf, x, method='linear', fill_value=np.max(self.sdf))
for _ in range(num_iters):
v, f = gpy.reach_for_the_spheres(self.pts, sdf_func, v_init, f_init)
v_init, f_init = v, f
return v, f
In this implementation:
We start with an initial icosphere mesh with the subdivision level set to 2 which gives us 162 vertices and 320 faces.
We define an SDF function using interpolation from our sampled points.
We iteratively apply the reach_for_the_spheres function from the gpytoolbox library.
The resulting vertices and faces are used as input for the next iteration.
Based on empirical observations, we’ve found that the best results are achieved when the number of faces and vertices in the initial icosphere is close to, but slightly less than, the expected output mesh complexity. Keeping it greater just simply results in the icosphere as the output.
Subdivision Level (n)
Vertices
Faces
0
12
20
1
42
80
2
162
320
3
642
1280
4
2562
5120
5
10242
20480
6
40962
81920
Subdivision levels of an icosphere and corresponding vertex and face counts generated using the gpy.icosphere function.
Advantages of RFS:
Adaptive resolution: RFS naturally adapts to surface features, using smaller spheres in areas of high curvature and larger spheres in flatter regions.
Feature preservation: The method is better at preserving sharp features compared to Marching Cubes
Topology handling: RFS can handle complex topologies and thin features more effectively than grid-based method.
2.4 Reconstruction using Reach for the Arcs
When reconstructing a mesh with Reach for the Arcs (RFA), this algorithm allows us to generate a mesh from a signed distance function. This method is a sort of extension of Reach for the Spheres in the way that it is focused on the curvature of our initial mesh as the focus for the reconstruction. As mentioned in the paper, the run time is slower than reconstructing using Reach for the Sphere but it produces better outputs for closed surfaces with some curvature like spot and strawberry models in Section 2.5.
The key difference between RFA & RFS:
Instead of spheres, we use circular arcs to approximate the local surface.
The algorithm considers the principal curvatures of the surface when determining the arc parameters.
RFA includes additional steps for handling thin features and self-intersections.
For a vertex \(v\) with normal \(n\) and principal curvatures \(\kappa_1\) and \(\kappa_2\), the local arc is defined by:
$$ v(t) = v + r(\cos(t) – 1)n + r\sin(t)d $$
Where \(r = 1/\max(|\kappa_1|, |\kappa_2|)\) is the arc radius, and \(d\) is the direction of maximum curvature.
How we implement the RFA algorithm in our project:
3.0 Reconstruction using VDF (Vector Distance Functions)
Reconstructions using Vector Distance Functions (VDFs) are similar to those using SDFs, except we have added a directional component. After creating a grid of points in a space, we can construct a vector stemming from each point that is both pointing in the direction that minimizes the distance to the mesh, as well as has the magnitude of the SDF at that point. In this way, the tip of each vector will lie on the real surface. From here, we can extract a point cloud of points on the surface and implement a reconstruction method.
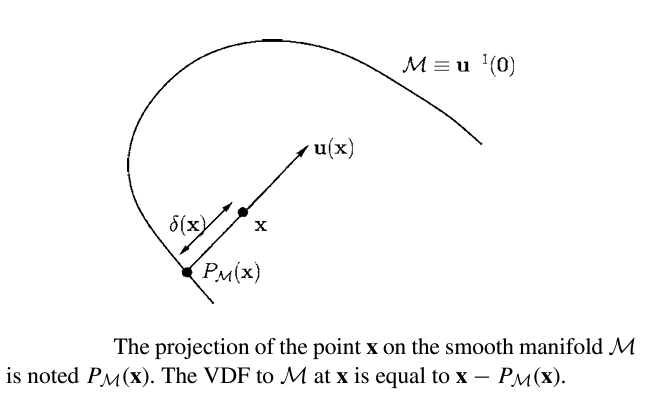
Mathematically, VDF can be used for arbitrary smooth maniform \(M\) with \(k\) dimension.
The following proof is from Gomes and Faugeras’ 2003 paper:
Given a smooth manifold \(M\), which is a subset of \(\mathbb{R}^n\), for every point \(x\), \(\delta(x)\) is that distance of \(\textbf{x}\) to \(M\). Let \(\textbf{u(x)}\) be the vector length of \(\delta(x)\), since \(u(x) = \delta{(x)}D\delta{(x)}\) for \(||D\delta{x}||\)=1. At a point \(\textbf{x}\) where \(\delta \) is differeientable, let \(\textbf{y} = P_{M}(x)\) be an unique projection of \(\textbf{x}\) onto \(M\). This point is such that \(\delta(x) = || x-y||\). Assuming \(M\) is smooth at \(y\), \(\textbf{x-y}\) is normal to \(M\) and parallel to \(D\delta{(x)}\).
Thus:
$$ \textbf{u(x)}= \textbf{x-y}= x-P_{M}(x) $$
Advantages of VDFs:
Due to their directional nature, VDFs have the potential to have more versatility and accuracy compared to SDFs.
There are four main benefits of using VDFs instead of SDFs:
VDFs can be used with shapes with arbitrary codimension.
VDFs perform better mesh reconstruction for closed surfaces.
VDFs can represent open surfaces that SDFs cannot.
VDFs can represent non-manifold surfaces like a Möbius strip.
Disadvantages of VDFs:
Despite these advantages, VDFs do have some drawbacks:
VDFs require more information to be known compared to SDFs
SDFs only need one number (distance) associated with each point in the grid
VDFs, on the other hand, require three numbers (assuming a 3D grid) associated with each point, representing the x, y, and z directions associated with each vector
VDFs can be harder to visualize/debug compared to SDFs
Depending on the method used to obtain them, VDFs can be inaccurate at some grid points
For example, singularities in the gradient can create issues when attempting to use the gradient for a VDF
These inaccurate VDFs can create inaccurate point clouds, which can result in poor reconstructions
Now, we will discuss the methods we used for creating VDFs and using them for reconstructions.
3.1 Reconstruction using Gradient
The gradient-based method leverages the fact that the gradient of a Signed Distance Function (SDF) points in the direction of maximum increase in distance. By reversing this direction and scaling by the SDF value, we obtain vectors pointing towards the surface.
Given an SDF \(\phi(x)\), the VDF \(\mathbf{u}(x)\) is defined as:
This method computes gradients using finite differences, normalizes them, and then scales by the SDF value to obtain the VDF. The surface points are then computed by adding the VDF to the grid vertices.
However, the gradient VDF reconstruction method, while theoretically sound, presented significant practical challenges in our experiments. As evident in the image above, this method produced numerous artifacts and distortions:.These issues likely arise from singularities and numerical instabilities in the gradient field, especially in complex geometries.
Given these results, we opted to focus on the barycentric coordinate method for our VDF reconstructions. This approach proved more robust and reliable, especially for complex 3D models with intricate surface details.
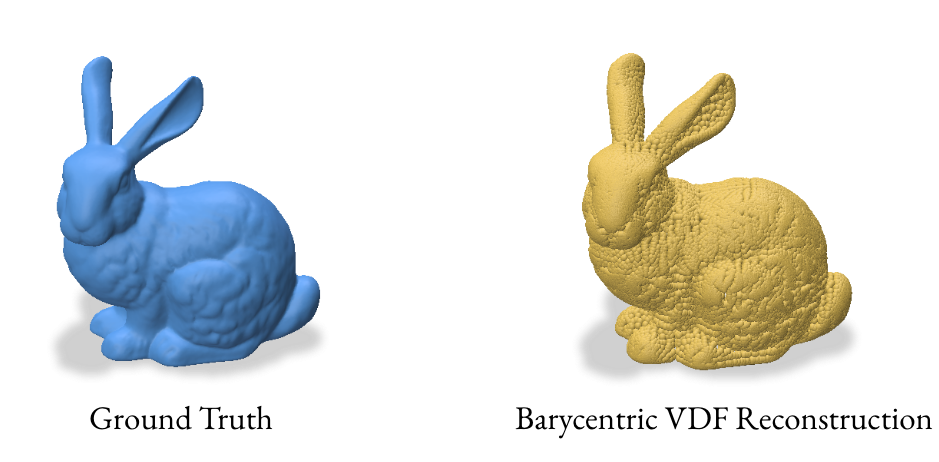
3.2 Reconstruction using Barycentric Coordinates
The barycentric coordinate method utilizes the signed_distance function from gpytoolbox to find the closest points on the mesh for each grid point. These closest points, represented in barycentric coordinates, are then converted to Cartesian coordinates to form a point cloud.
For a point \(p\) with barycentric coordinates \((u, v, w)\) relative to a triangle with vertices \((v_1, v_2, v_3)\), the Cartesian coordinates are:
This method computes the closest points on the mesh for each grid point and converts them to Cartesian coordinates. The VDF is then computed as the normalized vector from the grid point to its closest point on the mesh.
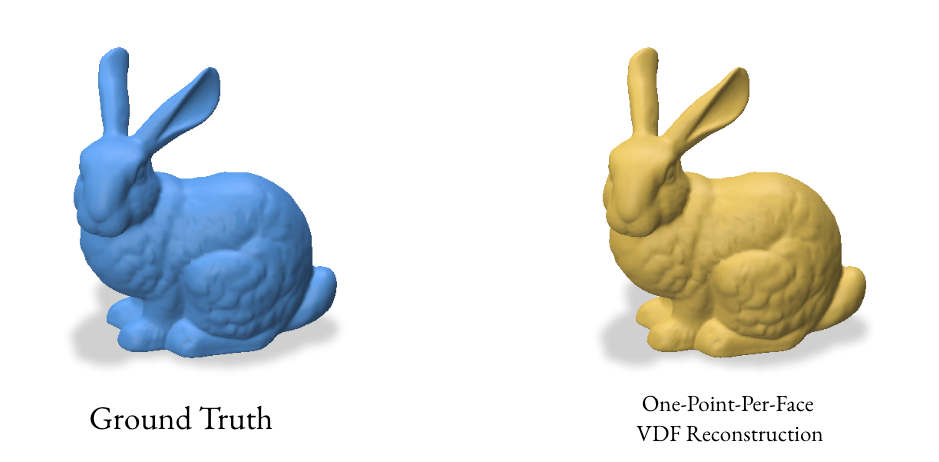
3.3 Reconstruction using one point per face
The one-point-per-face method aims to create a more uniform distribution of points on the surface by using the centroid of each face as a sample point. This approach is particularly effective for meshes with similarly-sized faces.
For a triangle face with vertices \((v_1, v_2, v_3)\), the centroid \(c\) is:
This method computes the centroids and normals for each face of the mesh. It creates a double-sided representation by duplicating the centroids and flipping the normals, which can help in creating a watertight reconstruction.
4.0 Analyzing the Results
After performing various reconstruction methods using Signed Distance Functions (SDFs) and Vector Distance Functions (VDFs), it’s crucial to analyze and compare the results. This section covers the visualization, and quantitative evaluation of the reconstructed meshes.
4.1 Visualizing the Results
The project uses the Polyscope library for visualizing the original and reconstructed meshes. The visualize method in all SDFReconstructor, VDFReconstructor and RayReconstructor classes handles the visualization.
This method creates a visual comparison between the original mesh and the reconstructed meshes or point clouds from different methods. The meshes are positioned side by side for easy comparison.
Additionally, the project includes a rendering functionality to export the visualization results as images. This is implemented in the render.py file
4.2 Fitness Score using Chamfer Distance
The project uses the Chamfer distance to compute a fitness score for the reconstructed meshes. The implementation is in the fitness.py file.
The Chamfer distance measures the average nearest-neighbor distance between two point sets. The fitness score is computed as:
This results in a value between 0 and 1, where higher values indicate better reconstruction.
5.0 Some Naive experimentation to get the results
Our initial experiments with the gradient VDF method produced unexpected results due to singularities, leading to inaccurate point clouds. This prompted us to explore alternative VDF methods that directly sample points on the surface, resulting in more reliable reconstructions.
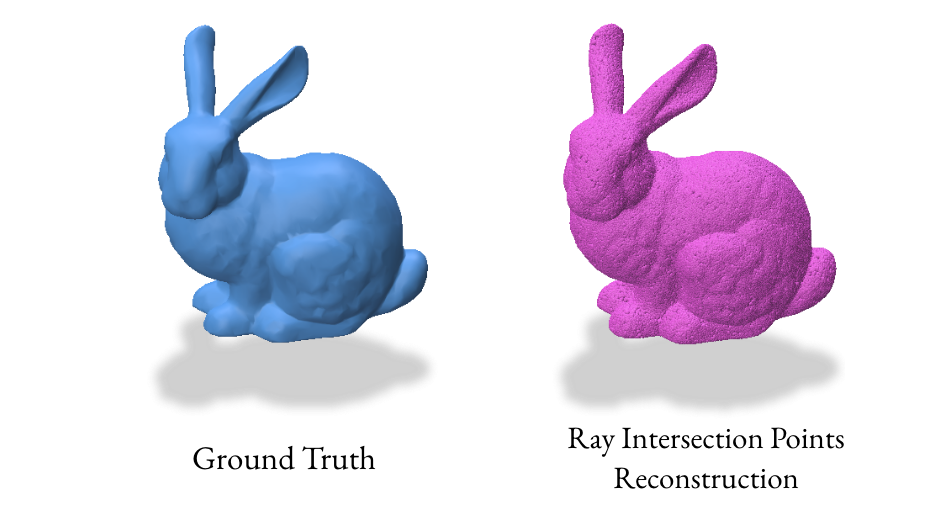
We implemented a ray-based reconstruction technique, the RayReconstructor class, as an additional method. This method generates a point cloud by shooting random rays and finding their intersections with the surface, then uses Poisson Surface Reconstruction to create the final mesh.
6.0 Takeaways & Further Exploration
Overall, VDFs are a promising alternative to SDFs and with the correct reconstruction method, can provide almost identical resultant meshes. They are able to provide more detail at the same resolution when compared to Marching Cubes and Reach for the Spheres. While Reach for the Arcs gives an impressive amount of detail, it often adds too much detail to where it results in details that are not present in the original mesh. VDFs, when constructed/used correctly, do not have this problem. If time permitted, we would have experimented with more non-manifold surfaces and compared the results of SDF and VDF reconstructions of these surfaces. VDFs do not require a clear outside and inside like SDFs do, so we could also explore more such surfaces manifold and non-manifold alike.
Silvia Sellán, Christopher Batty, and Oded Stein. 2023. Reach For the Spheres: Tangency-aware surface reconstruction of SDFs. In SIGGRAPH Asia 2023 Conference Papers (SA ’23). Association for Computing Machinery, New York, NY, USA, Article 73, 1–11. https://doi.org/10.1145/3610548.3618196
Silvia Sellán, Yingying Ren, Christopher Batty, and Oded Stein. 2024. Reach for the Arcs: Reconstructing Surfaces from SDFs via Tangent Points. In ACM SIGGRAPH 2024 Conference Papers (SIGGRAPH ’24). Association for Computing Machinery, New York, NY, USA, Article 23, 1–12. https://doi.org/10.1145/3641519.3657419
José Gomes and Olivier Faugeras. The Vector Distance Functions. International Journal of Computer Vision, vol. 52, no. 2–3, 2003. https://doi.org/10.1023/A:1022956108418
RXMesh is a framework for processing triangle mesh on the GPU. It allows developers to easily use the GPU’s massive parallelism to perform common geometry processing tasks on triangle mesh. For a preliminary introduction to RXMesh, check out this tutorial blog here.
Our task was to use RXMesh to implement some classic algorithms in geometry processing. This blog details one of the algorithms we implemented: Spectral Conformal Parameterization (SCP).
This blog will discuss the algorithm in terms of its basic concepts, the steps of the algorithm, the implementation using RXMesh, and our results.
Our entire implementation of SCP application in RXMesh can be found here.
Spectral Conformal Parameterization
Parameterization refers to the mapping of a triangle surface mesh in \(R^{3}\) space to a planar \(R^{2}\) space. This mapping can then be subsequently used in different application such as texture mapping, where we map the values from some other \(R^{2}\) space (e.g., image) to the surface of the mesh. In this case, we map color values to the mesh surface.
Often when we perform mesh parameterization, there is a possibility to change some properties of the geometric elements of the mesh, such as the size, shape, or angle between edges. It is desired to preserve these properties since we usually want to create a direct mapping of our intended values (e.g., texture color) to be in the “correct” positions on the mesh. What is correct is usually up to artistic opinion, and thus a mapping that preserves these properties is desirable. A mapping that conserves angles (and thus shape) is called a conformal mapping.
Mullen et al. (2008) provides a method to perform conformal parameterization of an open surface mesh by modelling the problem as a generalized Eigenvalue problem. Using an initial guess, we can perform multiple iterations of a general eigen vector solving method (i.e., the power method [2] ) to determine the largest eigen vector. This eigen vector, in our case, is the parameterized coordinates of the given mesh, giving us our desired output.
To find the eigenvector \(u\), we can the power method since the problem is in the form \(B y_{k+1} = A x_{k}\). This can be done in the following way:
Where \(u\) is the parameterized coordinates. \(T1\) and \(T2\) are temporary variables to store certain scalar or vector values. Other variables are explained by Mullen et al. (2008). This loop can be implemented like this using RXMesh:
\(T1\) is a vector whose values are per-vertex, which is why we perform a per vertex computation. \(T2\) is a scalar in which we store the value of the dot product dot(eb,uv).
Since our system matrix \(L_{c}\) has dimensions 2V x 2V, we use complex representations of value entries in the vectors and matrices we use. So, for example, our \(L_{c}\) matrix now has dimensions V x V where each entry is a complex number (with a real and complex part).
This means subsequent computations must use CUDA functions that operate on complex numbers (e.g., cuCsubf which subtracts complex numbers).
All initial pre-computations only allocate to the real part of the entry, except for the calculation of the area term \(A\) where we calculate \(L_{c}=L_{D}-A\) . For the area term, we assign values to the complex part of the area term. \(L_{D}\) represents the standard Laplace-Beltrami operator, which we calculate using the cotangent edge weights and assign to the real part.
After we obtain the eigenvector \(u\) in complex form, we can convert it to a standard V x 2 matrix form and use that for further processing (such as rendering).
Results
Using the SCP implementation, we can now apply texturing to our open meshes as shown in the examples below.
[2] Kozłowski, W. (1992). The power method for the generalized eigenvalue problem. Roczniki Polskiego Towarzystwa Matematycznego. Seria 3, Matematyka Stosowana/Matematyka Stosowana/Mathematica Applicanda, 21(35). https://doi.org/10.14708/ma.v21i35.1790
This blog was written by Sachin Kishan and Diany Pressato during the SGI 2024 Fellowship as one of the outcomes of a two-week project under the mentorship of Ahmed Mahmoud and the support of Supriya Gadi Patil as a teaching assistant.
RXMesh is a framework for processing triangle mesh on the GPU. It allows developers to easily use the GPU’s massive parallelism to perform common geometry processing tasks. For a preliminary introduction to RXMesh, check out this tutorial blog here.
Our task was to use RXMesh to implement some classic algorithms in geometry processing. This blog details one of the algorithms we implemented: As-Rigid-As-Possible(ARAP) Surface Modeling [1].
This blog will discuss the algorithm in terms of its basic concepts, the steps of the algorithm, the implementation using RXMesh, and the final results.
Our entire implementation of ARAP deformation in RXMesh can be found here.
As-Rigid-As-Possible Surface Modeling
Sorkine and Alexa (2007) formulated a method where we can retain the shape of an object as much as possible despite deforming one (or a set of) its vertices. This retention of shape is achieved by ensuring that subsequent transformations to the mesh after deforming its vertices are rigid. This property of rigidity means that a mesh can only undergo rigid transformations such as translation or rotation, but not stretching or shearing (since these are not rigid transformations).
The algorithm’s focus is to minimize the energy which measures the extent of deformation (dubbed rigidity energy). This energy is minimized when given a specific set of positions or a specific set of rotations. Notice that we can not minimize both at once—since we need the minimized rotational transformation for minimizing the energy from deformed positions. Thus, we instead solve both alternatively, i.e., solve for deformed positions assuming rotation is fixed, then solve for rotation assuming the position is fixed.
Using a Laplacian, we can form a sparse system of linear equations which we can then solve to obtain a new set of positions for the mesh. The algorithm works as follows for a single iteration
Identify the rotation matrix for the given deformed positions which minimizes deformation energy.
Solve for the new positions to minimize the energy, given a set of linear equations.
In this case, the set of linear equations to solve is in the form :
\(Lx=b\)
Where \(L\) is the Laplace-Beltrami operator, which can be formed by finding the cotangent edge weights of the mesh, \(x\) represents the set of new vertex positions we solve for, and \(b\) represents the right-hand side of Equation 8 from Sorkine and Alexa (2007). The derivation is detailed further in the original paper.
To further minimize the energy, we can perform multiple iterations of the same steps, using updated vertex positions and consequent rotations per iteration.
Implementation
The following code snippets show how the algorithm is implemented in RXMesh.
We first deform the input mesh and set constraints on each vertex depending on whether it is fixed, deformed, or free to move. This will be taken into account when calculating the system matrix \(L\).
// set constraints
const vec3<float> sphere_center(0.1818329, -0.99023, 0.325066);
rx.for_each_vertex(DEVICE, [=] __device__(const VertexHandle& vh) {
const vec3<float> p(deformed_vertex_pos(vh, 0),
deformed_vertex_pos(vh, 1),
deformed_vertex_pos(vh, 2));
// fix the bottom
if (p[2] < -0.63) {
constraints(vh) = 2;
}
// move the jaw
if (glm::distance(p, sphere_center) < 0.1) {
constraints(vh) = 1;
}
});
In the code above, we set the mesh to deform the dragon’s jaw and fix its bottom vertices (legs). This can vary depending on the type of input we want to have. Another possibility is to add a feature for users to click and select vertices to deform or fix them in space interactively.
Before we perform the iteration step, we calculate the Laplacian. It can be calculated as the cotangent edge weight matrix. So, we create a kernel using RXMesh.
auto calc_mat = [&](VertexHandle v_id, VertexIterator& vv) {
if (constraints(v_id, 0) == 0) {
for (int i = 0; i < vv.size(); i++) {
laplace_mat(v_id, v_id) += weight_matrix(v_id, vv[i]);
laplace_mat(v_id, vv[i]) -= weight_matrix(v_id, vv[i]);
}
} else {
for (int i = 0; i < vv.size(); i++) {
laplace_mat(v_id, vv[i]) = 0;
}
laplace_mat(v_id, v_id) = 1;
}
};
The weight matrix is calculated using a special query called “EVDiamond”, where we obtain the two end vertices and the two opposite vertices of an edge. This gives us exactly the data we need to find the cotangent edge weight.
auto calc_weights = [&](EdgeHandle edge_id, VertexIterator& vv) {
// the edge goes from p-r while the q and s are the opposite vertices
const rxmesh::VertexHandle p_id = vv[0];
const rxmesh::VertexHandle r_id = vv[2];
const rxmesh::VertexHandle q_id = vv[1];
const rxmesh::VertexHandle s_id = vv[3];
if (!p_id.is_valid() || !r_id.is_valid() || !q_id.is_valid() ||
!s_id.is_valid()) {
return;
}
const vec3<T> p(coords(p_id, 0), coords(p_id, 1), coords(p_id, 2));
const vec3<T> r(coords(r_id, 0), coords(r_id, 1), coords(r_id, 2));
const vec3<T> q(coords(q_id, 0), coords(q_id, 1), coords(q_id, 2));
const vec3<T> s(coords(s_id, 0), coords(s_id, 1), coords(s_id, 2));
T weight = 0;
weight += dot((p - q), (r - q)) / length(cross(p - q, r - q));
weight += dot((p - s), (r - s)) / length(cross(p - s, r - s));
weight /= 2;
weight = std::max(0.f, weight);
edge_weights(p_id, r_id) = weight;
edge_weights(r_id, p_id) = weight;
};
We now have all the building blocks necessary to perform an iteration step. This is what an iteration loop looks like:
// process step
for (int i = 0; i < iterations; i++) {
// solver for rotation
calculate_rotation_matrix<float, CUDABlockSize>
<<<lb_rot.blocks, lb_rot.num_threads, lb_rot.smem_bytes_dyn>>>(
rx.get_context(),
ref_vertex_pos,
deformed_vertex_pos,
rotations,
weight_matrix);
// solve for position
calculate_b<float, CUDABlockSize>
<<<lb_b_mat.blocks,
lb_b_mat.num_threads,
lb_b_mat.smem_bytes_dyn>>>(rx.get_context(),
ref_vertex_pos,
deformed_vertex_pos,
rotations,
weight_matrix,
b_mat,
constraints);
laplace_mat.solve(b_mat, *deformed_vertex_pos_mat);
}
We perform multiple iterations of the algorithm to effectively minimize the energy. We can see in the code above that we alternatively solve for rotation and then for positions. We first calculate the rotation matrix given a set of deformed positions, then calculate the \(b\) matrix (as defined earlier) and then solve the system of equations to identify the new vertex positions.
The following kernel calculates the rotation matrix per vertex to minimize the rigidity energy given their positions.
auto cal_rot = [&](VertexHandle v_id, VertexIterator& vv) {
Eigen::Matrix3f S = Eigen::Matrix3f::Zero();
for (int j = 0; j < vv.size(); j++) {
float w = weight_matrix(v_id, vv[j]);
Eigen::Vector<float, 3> pi_vector = {
ref_vertex_pos(v_id, 0) - ref_vertex_pos(vv[j], 0),
ref_vertex_pos(v_id, 1) - ref_vertex_pos(vv[j], 1),
ref_vertex_pos(v_id, 2) - ref_vertex_pos(vv[j], 2)
};
Eigen::Vector<float, 3> pi_dash_vector = {
deformed_vertex_pos(v_id, 0) - deformed_vertex_pos(vv[j], 0),
deformed_vertex_pos(v_id, 1) - deformed_vertex_pos(vv[j], 1),
deformed_vertex_pos(v_id, 2) - deformed_vertex_pos(vv[j], 2)};
S = S + w * pi_vector * pi_dash_vector.transpose();
}
Eigen::Matrix3f U; // left singular vectors
Eigen::Matrix3f V; // right singular vectors
Eigen::Vector3f sing_val; // singular values
svd(S, U, sing_val, V);
const float smallest_singular_value = sing_val.minCoeff();
Eigen::Matrix3f R = V * U.transpose();
if (R.determinant() < 0) {
U.col(smallest_singular_value) =
U.col(smallest_singular_value) * -1;
R = V * U.transpose();
}
// Matrix R to vector attribute R
for (int i = 0; i < 3; i++)
for (int j = 0; j < 3; j++)
rotations(v_id, i * 3 + j) = R(i, j);
};
We first find the Single Value Decomposition (SVD) of the sum (\(S_{i} \)) where
\(S_{i}=\sum_{j\in N(i)} w_{ij}e_{ij}e^{‘T}_{ij} \) (Equation 5 in Sorkine and Alexa(2007))
We then use that to calculate rotation and assign that as the vertice’s rotation. After we calculate rotation, we calculate the right-hand side of Equation 8 as stated earlier.
auto init_lambda = [&](VertexHandle v_id, VertexIterator& vv) {
// variable to store ith entry of b_mat
Eigen::Vector3f bi(0.0f, 0.0f, 0.0f);
// get rotation matrix for ith vertex
Eigen::Matrix3f Ri = Eigen::Matrix3f::Zero(3, 3);
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++)
Ri(i, j) = rotations(v_id, i * 3 + j);
}
for (int nei_index = 0; nei_index < vv.size(); nei_index++) {
// get rotation matrix for neightbor j
Eigen::Matrix3f Rj = Eigen::Matrix3f::Zero(3, 3);
for (int i = 0; i < 3; i++)
for (int j = 0; j < 3; j++)
Rj(i, j) = rotations(vv[nei_index], i * 3 + j);
// find rotation addition
Eigen::Matrix3f rot_add = Ri + Rj;
// find coord difference
Eigen::Vector3f vert_diff = {
ref_vertex_pos(v_id, 0) - ref_vertex_pos(vv[nei_index], 0),
ref_vertex_pos(v_id, 1) - ref_vertex_pos(vv[nei_index], 1),
ref_vertex_pos(v_id, 2) - ref_vertex_pos(vv[nei_index], 2)};
// update bi
bi = bi +
0.5 * weight_mat(v_id, vv[nei_index]) * rot_add * vert_diff;
}
if (constraints(v_id, 0) == 0) {
b_mat(v_id, 0) = bi[0];
b_mat(v_id, 1) = bi[1];
b_mat(v_id, 2) = bi[2];
} else {
b_mat(v_id, 0) = deformed_vertex_pos(v_id, 0);
b_mat(v_id, 1) = deformed_vertex_pos(v_id, 1);
b_mat(v_id, 2) = deformed_vertex_pos(v_id, 2);
}
};
After calling both these kernels, we use the solve function to solve the equations. We then update the mesh with this new set of vertex positions.
Results
Using the implementation above, we can create a per-frame ARAP implementation to animate movement for a mesh. In the example below, we fix the upper half vertices of Spot the Cow and allow the bottom half to freely deform. We then move each of the bottom “feet” vertices in every frame to animate a swimming or walking-like movement in Spot.
The bottom feet vertices are user-deformed , the upper vertices are fixed, and the bottom half (except the feet) are free to move—and are determined by the ARAP algorithm.
Here’s another example with the dragon mesh.
Deform a vertex of the dragon’s jaw while keeping its feet fixed.
Further work
Polyscope shows us that the framerate of these demos is very poor (below 30 fps). We would expect it to do better, especially when using the GPU. A performance analysis as well as optimizing of the solver will be required to make the application reach desired levels of real-time processing.
References
[1] Olga Sorkine and Marc Alexa. 2007. As-rigid-as-possible surface modeling. In Proceedings of the fifth Eurographics symposium on Geometry processing (SGP ’07). Eurographics Association, Goslar, DEU, 109–116. https://doi.org/10.2312/SGP/SGP07/109-116
This blog was written by Sachin Kishan during the SGI 2024 Fellowship as one of the outcomes of a two-week project under the mentorship of Ahmed Mahmoud and the support of Supriya Gadi Patil as a teaching assistant.
Now that SGI has come to a close, it’s time to talk about my experiences from the second half of the program. During the fourth week of the program, we worked heavily with machine learning and training models, specifically NeRFies. Since I have a lack of machine learning experience, it was difficult to understand all of the code. Model building and training are different ways of thinking that I am not used to.
We were paired up to work on different parts of the code, and again, this was incredibly helpful. Even though my partner did not have extensive coding research, having someone to talk the code through with was incredibly helpful. Everyone on this project was understanding and helpful when we did not understand something.
For the last two weeks, I have been on the same project. This project was introduced with very direct applications, which piqued my interest. Our focus was on computer graphics, specifically modeling surfaces with discrete equivalence classes. While there have been several papers published on this idea, we were specifically focusing on using as few different polygons as possible. We worked on understanding the code and process by which this could be accomplished.
If you were to build a surface with polygons, it would be much easier and cheaper with only two unique polygons in comparison to hundreds of unique polygons. While I have previously not had any research or interest in computer graphics, it is now a field I am interested in learning more about.
Overall, this experience was so out of my comfort zone. I worked with several people, all with various methods of research. This process not only helped me find out more about my preferred research style but also how to adapt to different styles of research.
Finally, I not only learned more about coding and geometry processing, but I also learned what it is like to be confused and how to be okay with that. Research is all about asking questions that may not have answers and then trying. Our efforts may not always have publishable results, but that does not mean we should stop asking questions.
Thank you all for the wonderful, challenging experience of SGI.
In this two-part post series, Nicolas and I dive deeper into SLAM systems– our project’s focus for the past two weeks. In this part, I introduce and cover the evolution of SLAM systems. In the next part, Nicolas harnesses our interest by discussing the future. By the end of both parts, we should be able to give you an overview of What it Takes to Get a SLAM Dunk.
Collaborators: Nicolas Pigadas
Introduction
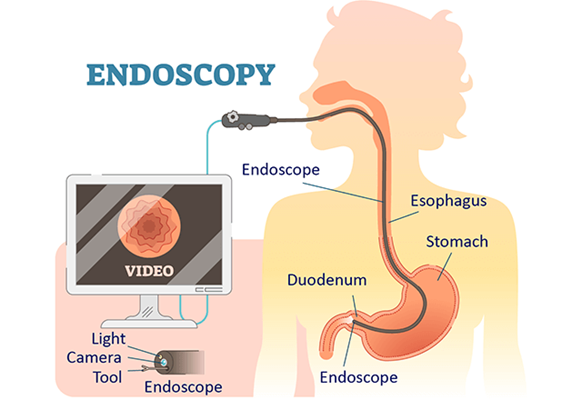
Simultaneous Localization and Mapping (SLAM) systems have become a standard in various technological fields, from autonomous robotics to augmented reality. However, in recent years, this technology has found a particularly unique application in medical imaging– in endoscopic videos. But what is SLAM?
Figure 1: A sample image using SLAM reconstruction from SG News Desk.
SLAM systems were conceptualized in robotics and computer vision for navigation purposes. Before SLAM, the fields employed more elementary methods,
Mapping: the process of creating a representation of an environment, typically in the form of a 2D or 3D map. This was done using grid-based and feature-based methods.
You may be thinking, Krishna, you just described SLAM systems, it sounds like. You are right, but the localizing and mapping were separate processes. So a robot would go through the pains of the Heisenberg principle, i.e., the robot would either localize or map– the or is exclusionary.
It was fairly obvious, but still daunting what the next step in research would be. Before we SLAM dunk our basketball, we must do a few lay-ups and free-throw shoots first.
Precursors to SLAM
Here are some inspirations that contributed to the development of SLAM
Probabilistic robotics: The introduction of probabilistic approaches, such as Bayesian filtering, allowed robots to estimate their position and map the environment with a degree of uncertainty, paving the way for more integrated systems.
Kalman filtering: a mathematical technique for estimating the state of a dynamic system. It allowed for continuous estimation of a robot’s position and could be invariant to noisy sensor data.
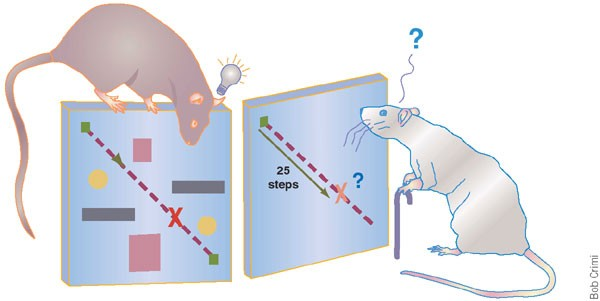
Cognitive Mapping in Animals: Research in cognitive science and animal navigation provided theoretical inspiration, particularly the idea that animals build mental maps of their environment while simultaneously keeping track of their location.
Figure 3: Spatial behavior and cognitive mapping of mice with aging. Image from Nature.
SLAM Dunk – A Culmination (some real Vince Carter stuff)
Finally, many researchers agreed that the separation of localizing and mapping was ineffective, and great efforts went into their integration. SLAM was developed. The goal was to enable systems to explore and understand an unknown environment autonomously, they needed to localize and map the environment simultaneously, with each task informing and improving the other.
With its unique ability to localize and map, researchers found SLAM’s use in any sensory device. Some of SLAM’s earlier use were sensor-based; so data would be inputted from range finders, sonar, and LIDAR; in the late 80s and early 90s. It is good to note that the algorithms were computationally intensive– and still are.
As technology evolved, a vision-based SLAM emerged. This shift was inspired by the human visual system, which navigates the world primarily through sight, enabling more natural and flexible mapping techniques.
Key Milestones
With the latest iterations of SLAM being exponentially better than the origin, it is important to recognize the journey. Here are notable SLAM systems:
EKF-SLAM (Extended Kalman Filter SLAM): One of the earliest and most influential SLAM algorithms, EKF-SLAM, laid the foundation for probabilistic approaches to SLAM, allowing for more accurate mapping and localization.
FastSLAM: Introduced in the early 2000s, FastSLAM utilized particle filters, making it more efficient and scalable. This development was crucial in enabling real-time SLAM applications.
Visual SLAM: The transition to vision-based SLAM in the mid-2000s opened new possibilities for the technology. Visual SLAM systems, such as PTAM (Parallel Tracking and Mapping), enabled more detailed and accurate mapping using standard cameras, a significant step toward broader applications.
Figure 4: Left LSD-SLAM, right ORB-SLAM. Image found in fzheng.me
From Robotics to Endoscopy (Medical Vision)
As SLAM technology matured, researchers explored its potential beyond traditional robotics. Medical imaging, particularly endoscopy, presented a fantastic opportunity for SLAM. Endoscopy is a medical procedure involving a flexible tube with a camera to visualize the body’s interior, often within complex and dynamic environments like the gastrointestinal tract.
It is fairly trivial why SLAM could be applied to endoscopic and endoscopy-like procedures to gain insights and make more medically informed decisions. Early work focused on using visual SLAM to navigate the gastrointestinal tract, where the narrow and deformable environment presented significant challenges.
One of the first successful implementations involved using SLAM to reconstruct 3D maps of the colon during colonoscopy procedures. This approach improved navigation accuracy and provided valuable information for diagnosing conditions like polyps or tumors.
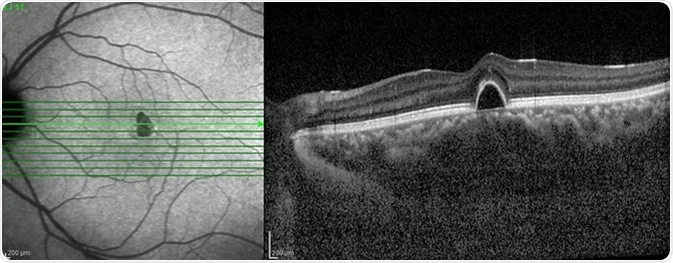
Researchers also explored the integration of SLAM with other technologies, such as optical coherence tomography (OCT) and ultrasound, to enhance the quality of the maps and provide additional layers of information. These efforts laid the groundwork for more advanced SLAM systems capable of handling the complexities of real-time endoscopic navigation.
Figure 6: Visual of Optical Coherence Tomography from News-Medical.
Endoscopy SLAMs – What Our Group Looked At
As a part of our study, we looked at some presently used and state-of-the-art SLAM systems. Below are the three that various members of our team attempted:
NICER-SLAM (RGB): a dense RGB SLAM system that simultaneously optimizes for camera poses and a hierarchical neural implicit map representation, which also allows for high-quality novel view synthesis.
ORB3-SLAM (RBG): (there is also ORB1 and ORB2) ORB-SLAM3 is the first real-time SLAM library able to perform Visual, Visual-Inertial, and Multi-Map SLAM with monocular, stereo, and RGB-D cameras, using pin-hole and fisheye lens models. In all sensor configurations, ORB-SLAM3 is as robust as the best systems available in the literature and significantly more accurate.
DROID-SLAM (RBG): a new deep learning-based SLAM system. DROID-SLAM consists of recurrent iterative updates of camera pose and pixel-wise depth through a Dense Bundle Adjustment layer.
Some other SLAM systems that our team would have loved to try our hand at are:
Gaussian Splatting SLAM: first application of 3D Gaussian Splatting in monocular SLAM, the most fundamental but the hardest setup for Visual SLAM.
GlORIE-SLAM: Globally Optimized RGB-only Implicit Encoding Point Cloud SLAM. This system uses a deformable point cloud as the scene representation and achieves lower trajectory error and higher rendering accuracy compared to competitive approaches.
This concludes part 1 of What it Takes to Get a SLAM Dunk. This post should have given you a gentle, but robust-enough introduction to SLAM systems. Vince Carter might even approve.
Figure 9: An homage to Vince Carter, arguably the greatest dunk-er ever. Image from Bleacher Report.
RXMesh is a framework for processing triangle mesh on the GPU. It allows developers to easily use the GPU’s massive parallelism to perform common geometry processing tasks.
This tutorial will cover the following topics:
Setting up RXMesh
RXMesh basic workflow
Writing kernels for queries
Example: Visualizing face normals
Setting up RXMesh
For the sake of this tutorial, you can set up a fork of RXMesh and then create your own small section to implement your own tutorial examples in the fork.
Once you have done the above steps, building the project with CMake is simple. Refer to the README in https://github.com/owensgroup/RXMesh to know the requirements and steps to build the project for your device.
Once the project has been set up, we can begin to test and run our introduction.cu file. If you were to run it, you should get an output of a 3D sphere.
This means the project set up has been successful, we can now begin learning RXMesh.
RXMesh basic workflow
RXMesh provides custom data structures and functions to handle various low-level computational tasks that would otherwise require low-level implementation. Let’s explore the fundamentals of how this workflow operates.
The above is a slightly simplified version of what a for_each computation program would look like using RXMesh. for_each involves accessing every mesh element of a specific type (vertex, edge, or face) and performing some process on/with it.
In the code example above, the computation adjusts the green component of the vertex’s color based on the vertex’s Y coordinate in 3D space.
But how do we comprehend this code? We will look at it line by line:
The above line declares the RXMeshStatic object. Static here stands for a static mesh (one whose connectivity remains constant for the duration of the program’s runtime). Using the RXMesh’s Input directory, we can use some meshes that come with it. In this case, we pass in the dragon.obj file, which holds the mesh data for a dragon.
auto polyscope_mesh = rx.get_polyscope_mesh();
This line returns the data needed for Polyscope to display the mesh along with any attribute content we add to it for visualization.
auto vertex_pos = *rx.get_input_vertex_coordinates();
This line is a special function that directly gives us the coordinates of the input mesh.
auto vertex_color = *rx.add_vertex_attribute<float>("vColor", 3);
This line gives vertex attributes called “vColor”. Attributes are simply data that lives on top of vertices, edges, or faces. To learn more about how to handle attributes in RXMesh, check out this. In this case, we associate three float-point numbers to each vertex in the mesh.
The above lines represent a lambda function that is utilized by the for_each computation. In this case, for_each_vertex accesses each of the vertices of the mesh associated with our dragon. We pass in the arguments:
rxmesh::DEVICE – to let RXMesh know this is happening on the device i.e., the GPU.
[vertex_color, vertex_pos] – represents the data we are passing to the function.
(const rxmesh::VertexHandle vh) – is the handle that is used in any RXMesh computation. A handle allows us to access data associated to individual geometric elements. In this case, we have a handle that allows us to access each vertex in the mesh.
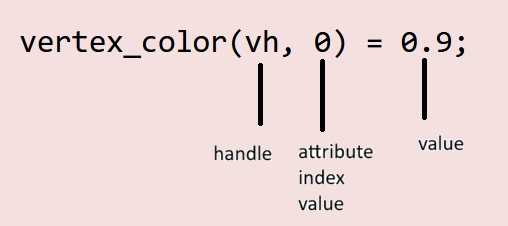
These 3 lines bring together a lot of the declarations made earlier. Through the kernel, we are accessing the attribute data we defined before. Since we need to know which vertex we are accessing its color, we pass in vh as the first argument. Since a vertex has three components (standing for RGB), we also need to pass which index in the attribute’s vector (you can think of it as a 1D array too) we are accessing. Hence vertex_color(vh, 0) = 0.9; which stands for “in the vertex color associated with the handle vh (which for the kernel represents a specific vertex on the mesh), the value of the first component is 0.9”. Note that this “first component” represents red for us.
What about vertex_color(vh, 1) = vertex_pos(vh, 1)? This line, similar to the previous one, is accessing the second component associated with the color, in the vertex the handle is associated with.
But what is on the right-hand side? We are accessing vertex_pos (our coordinates of each vertex in the mesh) and we are accessing it the same way we access our color. In this case, the line is telling us that we are accessing the 2nd positional coordinate (y coordinate) associated with our vertex (that our handle gives to the kernel).
vertex_color.move(rxmesh::DEVICE, rxmesh::HOST);
This line moves the attribute data from the GPU to the CPU.
This line uses Polyscope to add a “quantity” to Polyscope’s visualization of the mesh. In this case, when we add the VertexColorQuantity and pass vertex_color, Polyscope will now visualize the per-vertex color information we calculated in the lambda function.
polyscope::show();
We finally render the entire mesh with our added quantities using the show() function from Polyscope.
Throughout this basic workflow, you may have noticed it works similarly to any other program where we receive some input data, perform some processing, and then render/output it in some form.
More specifically, we use RXMesh to read that data, set up our attributes, and then pass that into a kernel to perform some processing. Once we move that data from the device to the host, we can either perform further processing or render it using Polyscope.
It is important to look at the kernel as computing per geometric element. This means we only need to think of computation on a single mesh element of a certain type (i.e., vertex, edge, or face) since RXMesh then takes this computation and runs it in parallel on all mesh elements of that type.
Writing kernels for queries
While our basic workflow covers how to perform for_each operation using the GPU, we may often require geometric connectivity information for different geometry processing tasks. To do that, RXMesh implements various query operations. To understand the different types of queries, check out this part of the README.
We can say there are two parts to run a query.
The first part consists of creating the launchbox for the query, which defines the threads and (shared) memory allocated for the process along with calling the function from the host to run on the device.
The second part consists of actually defining what the kernel looks like.
We will look at these one by one.
Here’s an example of how a launchbox is created and used for a process where we want to find all the vertex normals:
Notice how, in replacing the for_each part of our basic workflow, we instead declare the launchbox and call our function compute_vertex_normal (which we will look at next) from our main function.
We must also define the kernel which will run on the device.
template <typename T, uint32_t blockThreads>
__global__ static void compute_vertex_normal(const rxmesh::Context context,
rxmesh::VertexAttribute<T> coords,
rxmesh::VertexAttribute<T> normals)
{
auto vn_lambda = [&](FaceHandle face_id, VertexIterator& fv){
// get the face's three vertices coordinates
glm::fvec3 c0(coords(fv[0], 0), coords(fv[0], 1), coords(fv[0], 2));
glm::fvec3 c1(coords(fv[1], 0), coords(fv[1], 1), coords(fv[1], 2));
glm::fvec3 c2(coords(fv[2], 0), coords(fv[2], 1), coords(fv[2], 2));
// compute the face normal
glm::fvec3 n = cross(c1 - c0, c2 - c0);
// the three edges length
glm::fvec3 l(glm::distance2(c0, c1),
glm::distance2(c1, c2),
glm::distance2(c2, c0));
// add the face's normal to its vertices
for (uint32_t v = 0; v < 3; ++v) {
// for every vertex in this face
for (uint32_t i = 0; i < 3; ++i) {
// for the vertex 3 coordinates
atomicAdd(&normals(fv[v], i), n[i] / (l[v] + l[(v + 2) % 3]));
}
}
};
auto block = cooperative_groups::this_thread_block();
Query<blockThreads> query(context);
ShmemAllocator shrd_alloc;
query.dispatch<Op::FV>(block, shrd_alloc, vn_lambda);
}
A few things to note about our kernel
We pass in a few arguments to our kernel.
We pass the context which allows RXMesh to access the data structures on the device.
We pass in the coordinates of each vertex as a VertexAttribute
We pass in the normals of each vertex as an attribute. Here, we accumulate the face’s normal on its three vertices.
The function that performs the processing is a lambda function. It takes in the handles and iterators as arguments. The type of the argument will depend on what type of query is used. In this case, since it is an FV query, we have access to the current face(face_id) the thread is acting on as well as the vertices of that face using fv.
Notice how within our lambda function, we do the same as before with our for_each operation, i.e., accessing the data we need using the attribute handle and processing it for some output for our attribute.
Outside our lambda function, notice how we need to set some things up with regards to memory and the type of query. After that, we call the lambda function to make it run using query.dispatch
Visualizing face normals
Now that we’ve learnt all the pieces required to do some interesting calculations using RXMesh, let’s try a new one out.
Try to visualize the face normals of a given mesh. This would mean obtaining an output like this for the dragon mesh given in the repository:
Here’s how to calculate the face normals of a mesh:
Take a vertex. Calculate two vectors that are formed by subtracting the selected vertex from the other two vertices.
Take the cross product of the two vectors.
The vector obtained from the cross product is the normal of the face.
Now try to perform the calculation above. We can do this for each face using the vertices it is connected to.
All the information above should give you the ability to implement this yourself. If required, the solution is given below.
The kernel that runs on the device:
template <typename T, uint32_t blockThreads>
global static void compute_face_normal(
const rxmesh::Context context,
rxmesh::VertexAttribute coords, // input
rxmesh::FaceAttribute normals) // output
{
auto vn_lambda = [&](FaceHandle face_id, VertexIterator& fv) {
// get the face's three vertices coordinates
glm::fvec3 c0(coords(fv[0], 0), coords(fv[0], 1), coords(fv[0], 2));
glm::fvec3 c1(coords(fv[1], 0), coords(fv[1], 1), coords(fv[1], 2));
glm::fvec3 c2(coords(fv[2], 0), coords(fv[2], 1), coords(fv[2], 2));
// compute the face normal
glm::fvec3 n = cross(c1 - c0, c2 - c0);
normals(face_id, 0) = n[0];
normals(face_id, 1) = n[1];
normals(face_id, 2) = n[2];
};
auto block = cooperative_groups::this_thread_block();
Query<blockThreads> query(context);
ShmemAllocator shrd_alloc;
query.dispatch<Op::FV>(block, shrd_alloc, vn_lambda);
}
Color a vertex depending on how many vertices it is connected to.
Test the above on different meshes and see the results. You can access different kinds of mesh files from the “Input” folder in the RXMesh repo and add your own meshes if you’d like.
By the end of this, you should be able to do the following:
Know how to create new subdirectories in the RXMesh Fork
Know how to create your own for_each computations on the mesh
Know how to create your own queries
Be able to perform some basic geometric analyses’ using RXMesh queries
This blog was written by Sachin Kishan during the SGI 2024 Fellowship as one of the outcomes of a two week project under the mentorship of Ahmed Mahmoud and support of Supriya Gadi Patil as teaching assistant.
Hi! I am Brittney Fahnestock, and I am a rising senior at the State University of New York at Oswego. This is one of the smaller, less STEM-based state schools in New York. That being said, I am a mathematics education and mathematics double major. Most of my curriculum has been pedagogy-based, teaching mathematics and pure mathematics topics like algebraic topology.
So, as you might have read, that does not seem to have applied mathematics, coding, or geometry processing experience. If you are thinking that, you are right! I have minimal experience with Python, PyTorch, and Java. All of my experience is either based on statistical data modeling or drawing cute pictures in Java. So again, my experience has not been much help with what was about to take place!
The introduction week was amazing, but hard. It helped me catch up information-wise since I had minimal experience with geometry processing. However, the exercises were time-consuming and challenging. While I felt like I understood the math during the lectures, coding up that math was another challenge. The exercise helped to make all of the concepts that were lectured about more concrete. While I did not get them all working perfectly, the reward was in trying and thinking about how I could get them to work or how to improve my code.
Now, onto what my experience was like during the research! In the first week, we worked with Python. I did a lot more of the coding than expected. I felt lost many times with what to do, but in our group, we were trying to get out of our comfort zones. Getting out of our comfort zones allows us to grow as researchers and as humans. As a way to make sure we were productive, we did partner coding. My partner knew a lot more about coding than I did. This was a great way to learn more about the topic with guidance!
We worked with splines, which of course was new for me, but they were interesting. Splines not only taught me about coding and geometry but also the continuity of curves and surfaces. The continuity was my favorite part. We watched a video explaining how important it is for there to be strong levels of continuity for video games, especially when the surfaces are reflective.
Week two was a complete change of pace. The language used was C++, but no one in the group had any experience with C++. Our mentor decided that we would guide him with the math and coding, but he would worry about the syntax specifics of C++. I guess this was another form of partner/group coding. While it exposed us to C++, our week was aimed at helping us understand the topics and allowing us to explore what we found interesting.
We worked with triangle marching and extracting iso-values with iso-segmentation and simplices. I had worked with simplicies in an algebraic topology context and found it super interesting to see the overlap in the two fields.
I have an interest in photography, so the whole week I saw strong connections to a passion of mine. This helped me to think of new questions and research ideas. While a week was not quite long enough to accomplish our goal, we plan on meeting after SGI to continue our work!
I can not wait for the last three weeks of SGI so I can continue to learn new ideas about geometry processing and research!