Students: Daniel Perazzo, Sanowar Munshi, Francheska Kovacevic
TA: Kevin Roice
Mentors: Antonio Teran, Zachary Randell, Megan Williams
Introduction
Monitoring the health and sustainability of native ecosystems is an especially pressing issue in an era heavily impacted by global warming and climate change. One of the most vulnerable types of ecosystems for climate change are the oceans, which means that developing methods to monitor these ecosystems is of paramount importance.
Inspired by this problem, this SGI 2023 project aims to use state-of-the-art 3D reconstruction methods to monitor kelp, a type of algae that grows in Seattle’s bay area.
This project was done in partnership with Seattle aquarium and allowed us to use data available from their underwater robots as shown in the figure below.

Figure 1: Underwater robot to collect the data
This robot collected numerous pictures and videos in high-resolution, as seen in the figure below. From this data, we managed to perform the reconstruction of the sea floor, by some steps. First we perform a sparse reconstruction to get the camera poses and then we perform some experiments to perform the dense reconstruction. The input data is shown below.

Figure 2: Types of input data extracted by the robot. High-resolution images for 3D reconstruction
Sparse Reconstruction
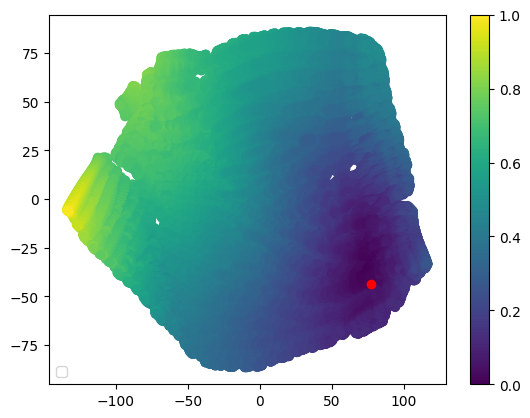
To get the dense reconstruction working, we first performed a sparse reconstruction of the scene, in the image below we see the camera poses extracted using COLMAP [5], and their trajectory in the underwater seafloor. It should be noted that the trajectory of the camera differs substantially from the trajectory of the real robot. This could be caused by the lack of a loop closure during the trajectory of the camera.

Figure 3: Camera poses extracted from COLMAP.
With these camera poses, we can reconstruct the depth maps, as shown below. These are very good for debugging, since we can visualize and get a grasp of how the output of COLMAP differs from the real result. As can be seen, there are some artifacts for the reconstruction of the depth for this image. And this will reflect in the quality of the 3D reconstruction.

Figure 4: Example of depth reconstruction using the captured camera poses extracted by COLMAP
3D Reconstruction
After computing the camera poses, we can go to the 3D reconstruction step. We used some techniques to perform 3D reconstruction of the seafloor using the data provided to us by Dr. Zachary Randell and his team. For our reconstruction tests we used COLMAP [1]. In the image below we present the image of the reconstruction.

Figure 5: Reconstruction of the sea-floor.
We can notice that the reconstruction of the seabed has a curved shape, which is not reflected in the real seabed. This error could be caused by the fact that, as mentioned before, this shape has a lack of a loop closure.
We also compared the original images, as can be seen in the figure below. Although “rocky”, it can be seen that the quality of the images is relatively good.

Figure 6: Comparison of image from the robot video with the generated mesh.
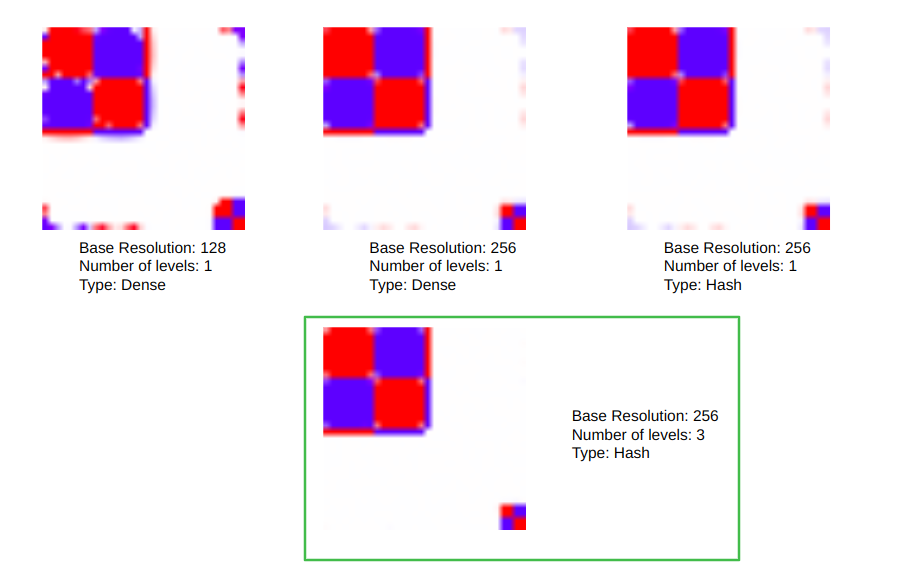
We also tested with NeRFs [2] in this scene using the camera poses extracted by COLMAP. For these tests, we used nerfstudio [3]. Due to the problems already mentioned for the camera poses, the results of the NeRF reconstruction are really poor, since it could not reconstruct the seabed. The “cloud” error was supposed to be the reconstructed view. An image for this result is shown below:

Figure 7: Reconstruction of our scene with NeRFs. We hypothesize this being to the camera poses.
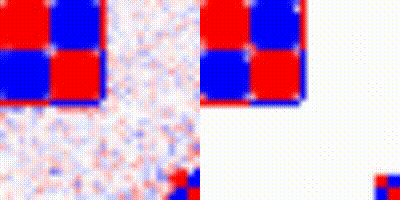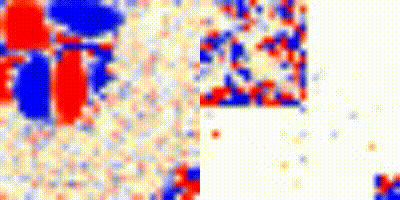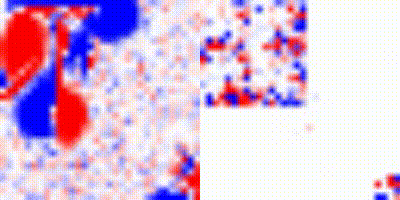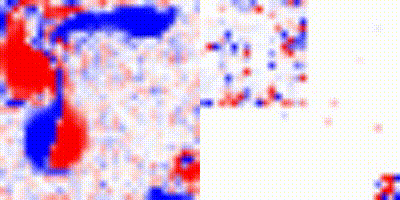
We also tested with a scene from the Sea-thru-NeRF [4] dataset, which yielded much better results:

Figure 8: Reconstruction of Sea-thru-NeRF with NeRFs. The scene was already prepared for NeRF reconstruction
Although the perceptual results were good, for some views, when we tried to recover the results using NeRFs yielded poor results, as can be seen on the point cloud bellow:

Figure 9: Mesh obtained from Sea-thru-NeRF scene.
As can be seen, the NeRF interpreted the water as an object. So, it reconstructed the seafloor wrongly.
Conclusions and Future Work
3D reconstruction of the underwater sea floor is really important for monitoring kelp forests. However, for our study cases, there is a lot to learn and research. More experiments could be made that perform loop closure to see if this could yield better camera poses, which in turn would result in a better 3D dense reconstruction. A source for future work could be to prepare and work in ways to integrate the techniques already introduced on Sea-ThruNeRF to nerfstudio, which would be really great for visualization of their results. Also, the poor quality of the 3D mesh generated by nerfstudio will probably increase if we use Sea-ThruNeRF. These types of improvements could yield better 3D reconstructions and, in turn, better monitoring for oceanographers.
References
[1] Schonberger, Johannes et al. “Structure-from-motion revisited.” IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016.
[2] Mildenhall, Ben, et al. “Nerf: Representing scenes as neural radiance fields for view synthesis.” Communications of the ACM. 2021
[3] Tancik, M., et al. “Nerfstudio: A modular framework for neural radiance field development”. ACM SIGGRAPH 2023.
[4] Levy, D., et al. “SeaThru-NeRF: Neural Radiance Fields in Scattering Media.” IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2023.
[5] Schonberger, Johannes L., and Jan-Michael Frahm. “Structure-from-motion revisited.” IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2016.