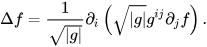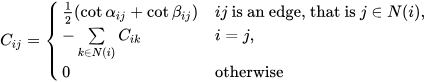Students: Daniel Perazzo, Sanowar Munshi, Francheska Kovacevic
TA: Kevin Roice
Mentors: Antonio Teran, Zachary Randell, Megan Williams
Introduction
Monitoring the health and sustainability of native ecosystems is an especially pressing issue in an era heavily impacted by global warming and climate change. One of the most vulnerable types of ecosystems for climate change are the oceans, which means that developing methods to monitor these ecosystems is of paramount importance.
Inspired by this problem, this SGI 2023 project aims to use state-of-the-art 3D reconstruction methods to monitor kelp, a type of algae that grows in Seattle’s bay area.
This project was done in partnership with Seattle aquarium and allowed us to use data available from their underwater robots as shown in the figure below.
Figure 1: Underwater robot to collect the data
This robot collected numerous pictures and videos in high-resolution, as seen in the figure below. From this data, we managed to perform the reconstruction of the sea floor, by some steps. First we perform a sparse reconstruction to get the camera poses and then we perform some experiments to perform the dense reconstruction. The input data is shown below.
Figure 2: Types of input data extracted by the robot. High-resolution images for 3D reconstruction
Sparse Reconstruction
To get the dense reconstruction working, we first performed a sparse reconstruction of the scene, in the image below we see the camera poses extracted using COLMAP [5], and their trajectory in the underwater seafloor. It should be noted that the trajectory of the camera differs substantially from the trajectory of the real robot. This could be caused by the lack of a loop closure during the trajectory of the camera.
Figure 3: Camera poses extracted from COLMAP.
With these camera poses, we can reconstruct the depth maps, as shown below. These are very good for debugging, since we can visualize and get a grasp of how the output of COLMAP differs from the real result. As can be seen, there are some artifacts for the reconstruction of the depth for this image. And this will reflect in the quality of the 3D reconstruction.
Figure 4: Example of depth reconstruction using the captured camera poses extracted by COLMAP
3D Reconstruction
After computing the camera poses, we can go to the 3D reconstruction step. We used some techniques to perform 3D reconstruction of the seafloor using the data provided to us by Dr. Zachary Randell and his team. For our reconstruction tests we used COLMAP [1]. In the image below we present the image of the reconstruction.
Figure 5: Reconstruction of the sea-floor.
We can notice that the reconstruction of the seabed has a curved shape, which is not reflected in the real seabed. This error could be caused by the fact that, as mentioned before, this shape has a lack of a loop closure.
We also compared the original images, as can be seen in the figure below. Although “rocky”, it can be seen that the quality of the images is relatively good.
Figure 6: Comparison of image from the robot video with the generated mesh.
We also tested with NeRFs [2] in this scene using the camera poses extracted by COLMAP. For these tests, we used nerfstudio [3]. Due to the problems already mentioned for the camera poses, the results of the NeRF reconstruction are really poor, since it could not reconstruct the seabed. The “cloud” error was supposed to be the reconstructed view. An image for this result is shown below:
Figure 7: Reconstruction of our scene with NeRFs. We hypothesize this being to the camera poses.
We also tested with a scene from the Sea-thru-NeRF [4] dataset, which yielded much better results:
Figure 8: Reconstruction of Sea-thru-NeRF with NeRFs. The scene was already prepared for NeRF reconstruction
Although the perceptual results were good, for some views, when we tried to recover the results using NeRFs yielded poor results, as can be seen on the point cloud bellow:
Figure 9: Mesh obtained from Sea-thru-NeRF scene.
As can be seen, the NeRF interpreted the water as an object. So, it reconstructed the seafloor wrongly.
Conclusions and Future Work
3D reconstruction of the underwater sea floor is really important for monitoring kelp forests. However, for our study cases, there is a lot to learn and research. More experiments could be made that perform loop closure to see if this could yield better camera poses, which in turn would result in a better 3D dense reconstruction. A source for future work could be to prepare and work in ways to integrate the techniques already introduced on Sea-ThruNeRF to nerfstudio, which would be really great for visualization of their results. Also, the poor quality of the 3D mesh generated by nerfstudio will probably increase if we use Sea-ThruNeRF. These types of improvements could yield better 3D reconstructions and, in turn, better monitoring for oceanographers.
References
[1] Schonberger, Johannes et al. “Structure-from-motion revisited.” IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016.
[2] Mildenhall, Ben, et al. “Nerf: Representing scenes as neural radiance fields for view synthesis.” Communications of the ACM. 2021
[3] Tancik, M., et al. “Nerfstudio: A modular framework for neural radiance field development”. ACM SIGGRAPH 2023.
[4] Levy, D., et al. “SeaThru-NeRF: Neural Radiance Fields in Scattering Media.” IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2023.
[5] Schonberger, Johannes L., and Jan-Michael Frahm. “Structure-from-motion revisited.” IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2016.
Students: Gabriele Dominici, Daniel Perazzo, Munshi Sanowar Raihan, Biruk Abere, Sana Arastehfar
TA: Jiri Mirnacik
Mentor: Tongzhou Wang
Introduction
In reinforcement learning (RL), an agent is placed in an environment, and is required to complete some task from a starting state. Traditionally, RL is often studied under the single-task setting, where the agent is taught to do one task and one task only. However, multi-task agents are much more general and useful. A robot that knows to do all household tasks is much more valuable than one that only opens the door. In particular, many useful tasks of interest are goal-reaching tasks, i.e., reaching a specific given goal state from any starting state.
Each RL environment implicitly defines a distance-like geometry on its states:
“distance”(state A, state B) := #steps needed for an agent to go from state A to state B.
Such a distance-like object is called a quasimetric. It is a relaxation of the metric/distance function in that it can be asymmetrical (i.e., d(x,y) != d(y,x) in general). For example,
Going up a hill is harder than going down the hill.
Dynamic systems that model velocity are generally asymmetrical (irreversible).
Asymmetrical & irreversible dynamics occur frequently in games, e.g., this ice-sliding puzzle. (Game: Professor Layton and Pandora’s Diabolical Box)
This quasimetric function captures how the environment evolves with respect to agent behavior. In fact, for any environment, its quasimetric is exactly what is needed to efficiently solve all goal-reaching tasks.
Quasimetric RL (QRL) is a goal-reaching RL method via learning this quasimetric function. By training on local transitions (state, action, next state), QRL learns to embed states into a latent representation space, where the latent quasimetric distance coincides with the quasimetric geometry for the environment. See https://www.tongzhouwang.info/quasimetric_rl/ for details.
The QRL paper explores the control capabilities of the learned quasimetric function, but not the representation learning aspects. In this project, we aim to probe the properties of learned latent spaces, which have a quasimetric geometry that is trained to model the environment geometry.
Setup. We design grid-world-like environments, and use an provided implementation of QRL in PyTorch to train QRL quasimetric functions. Afterwards, we perform qualitative and visual analyses on the learned latent space.
Environments
Gridworld with directions
In reinforcement learning for the Markov decision process, the agent has access to the internal state of the world. When the agent takes an action, the environment changes accordingly and returns the new state. In our case, we try to simulate a robot trying to reach a goal.
Our agent has only three actions: go forward, turn right and turn left. We assume that the agent has reached the goal if it is around the goal with a small margin of error. For simplicity, we fix the initial position and the goal position. We set the angular velocity and the step size to be fixed for the robot.
The environment returns to the agent the position it is currently in, and the vector direction the robot is currently facing. Following the example in the original QRL paper, we have a constant reward of -1 for the agent which encourages the agent to reach the goal as quickly as possible.
Training
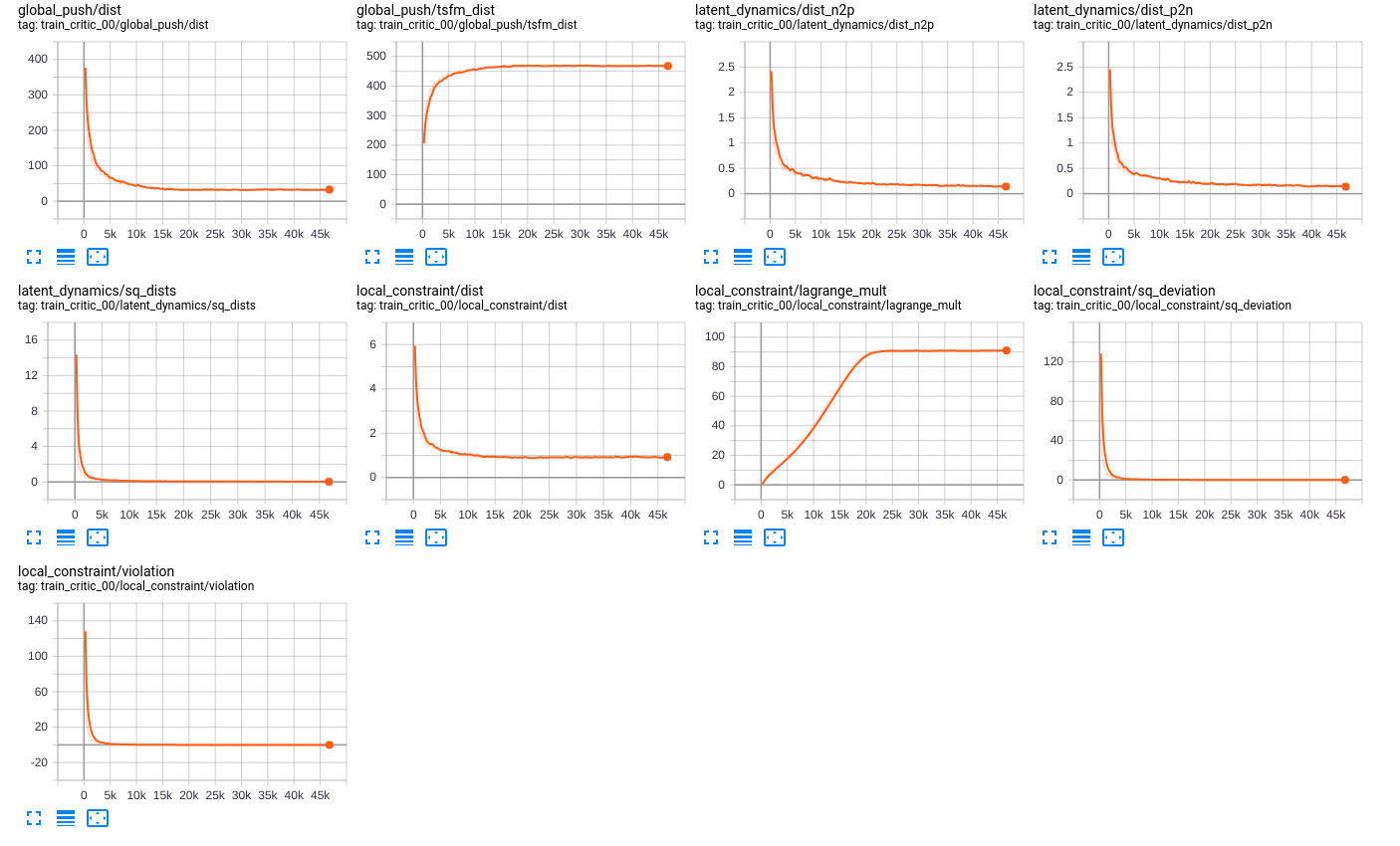
For this project, we tested QRL on the aforementioned environments, where we obtained some interesting results. Firstly, we performed an offline version of QRL using only a critic network. For this setting, we used a dataset of trajectories created by actors performing a random trajectory. This random trajectory is then loaded when training starts.As shown in the figure in the previous section, we have a robot performing a random trajectory.
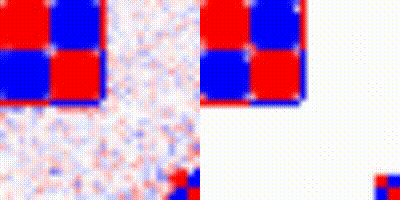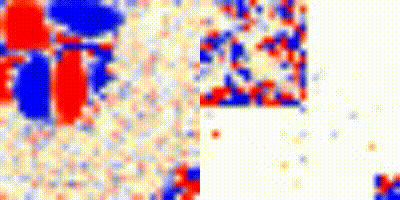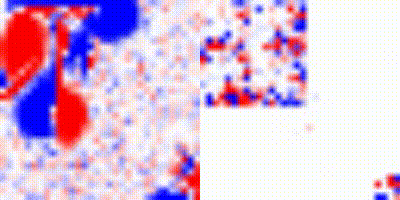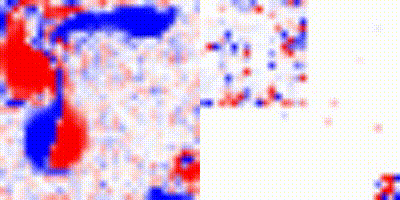
We trained in QRL varying the parameters for training the neural network. Using QRL we let the network train for various steps, as can be seen below:
After performing this training we analysed what would the agent learn, however, unfortunately, it seems that the agent is stuck, as can be seen in the figure below:
To get a better understanding of the problem, we performed some experiments using A2C implementation from stable_baselines. Instead of using the angle set-up as mentioned early, we used a setting where we return the angle directly. We also performed various runs, ~10 for A2C and always testing the trajectories. Although there were some runs that A2C did not manage to find the right trajectory, on some it did. We show the best results bellow:
We also performed some tests varying the parameters for quasimetric learning and inserting an intermediary state for the agent to reach the goal. After varying some parameters, including batch size and the coordinate space the agent is traversing. The improved results can be seen bellow, where the agents manage to reach the goal. Also, instead of, during the visualization, instead of using a greedy approach we instead use a categorical distribution, varying a temperature parameter to make it more random:
These results were preliminary and we will not analyze these results for the next section.
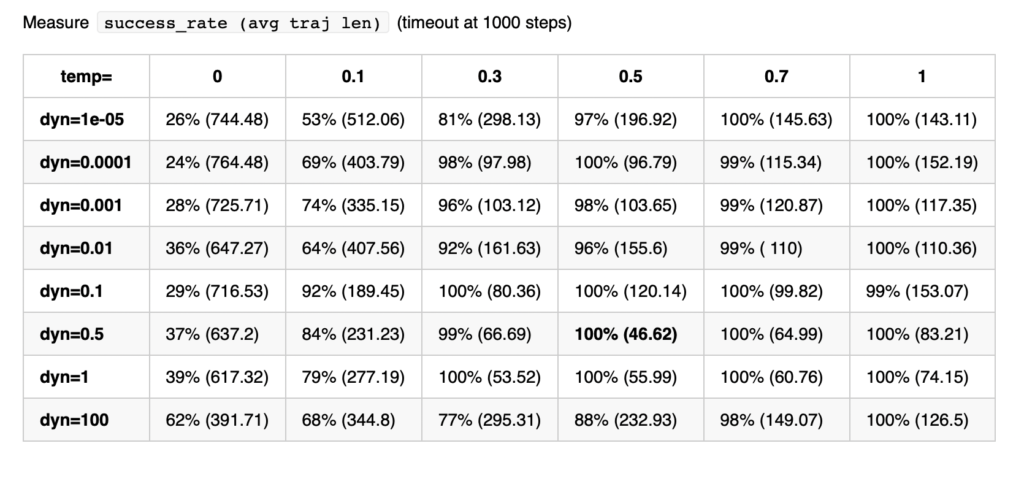
We also performed an analysis on different settings, using different weights for our dynamic loss and and varying the previously mentioned temperature parameter. The table is shown bellow
Analyses
As previously said, we inspect the latent space learnt by the neural network to represent each state. In such a manner, it would be possible to inspect how the model reasons about the environment and the task.
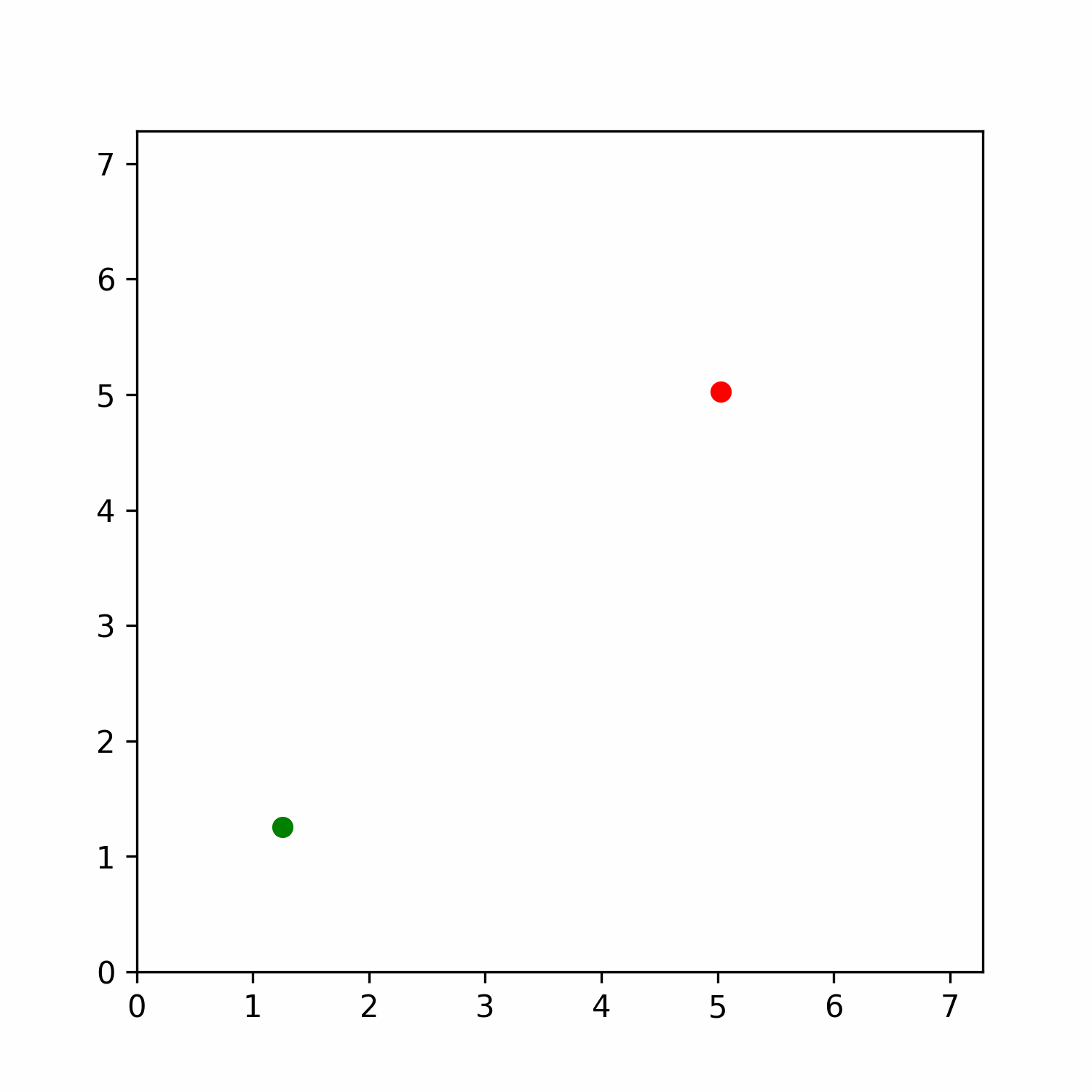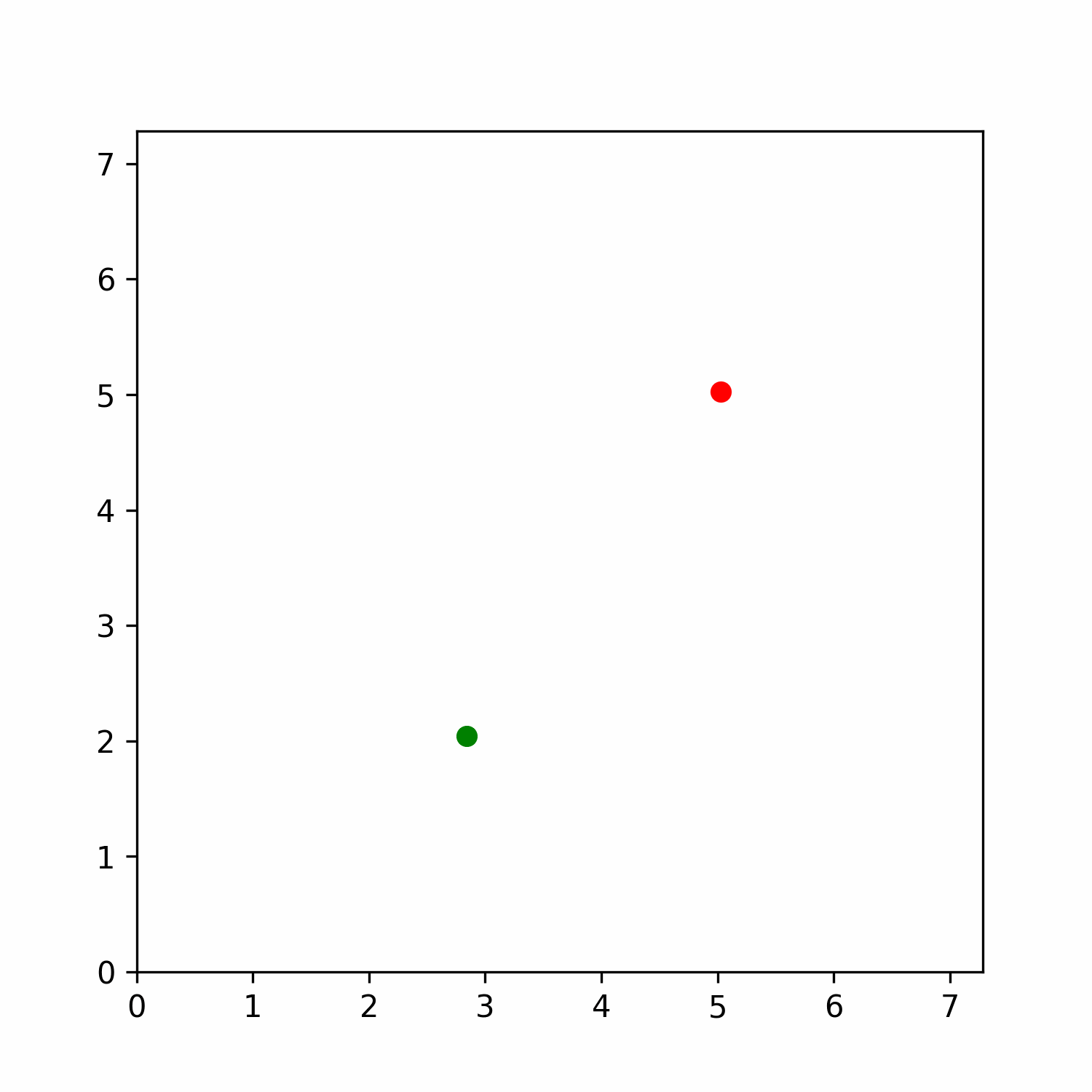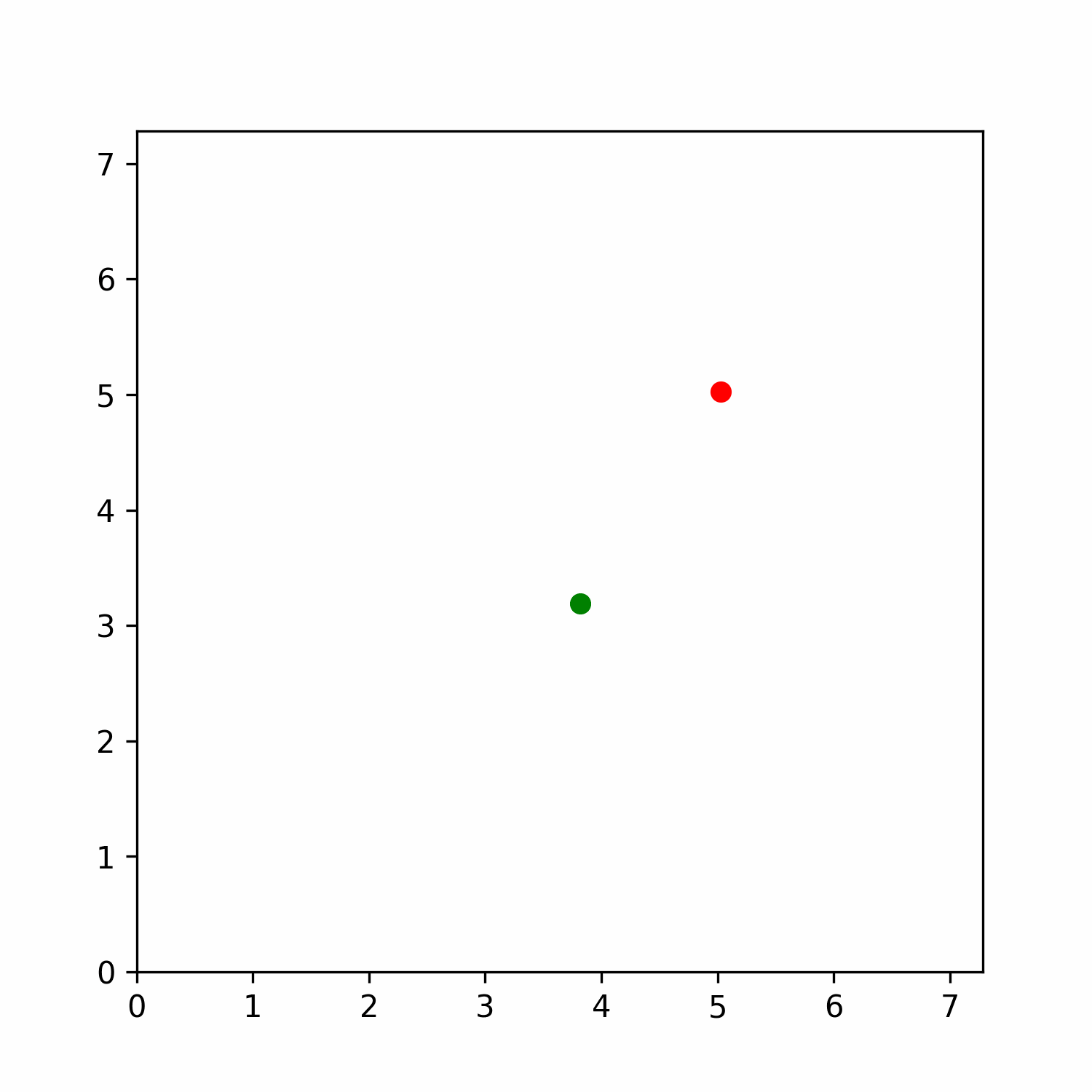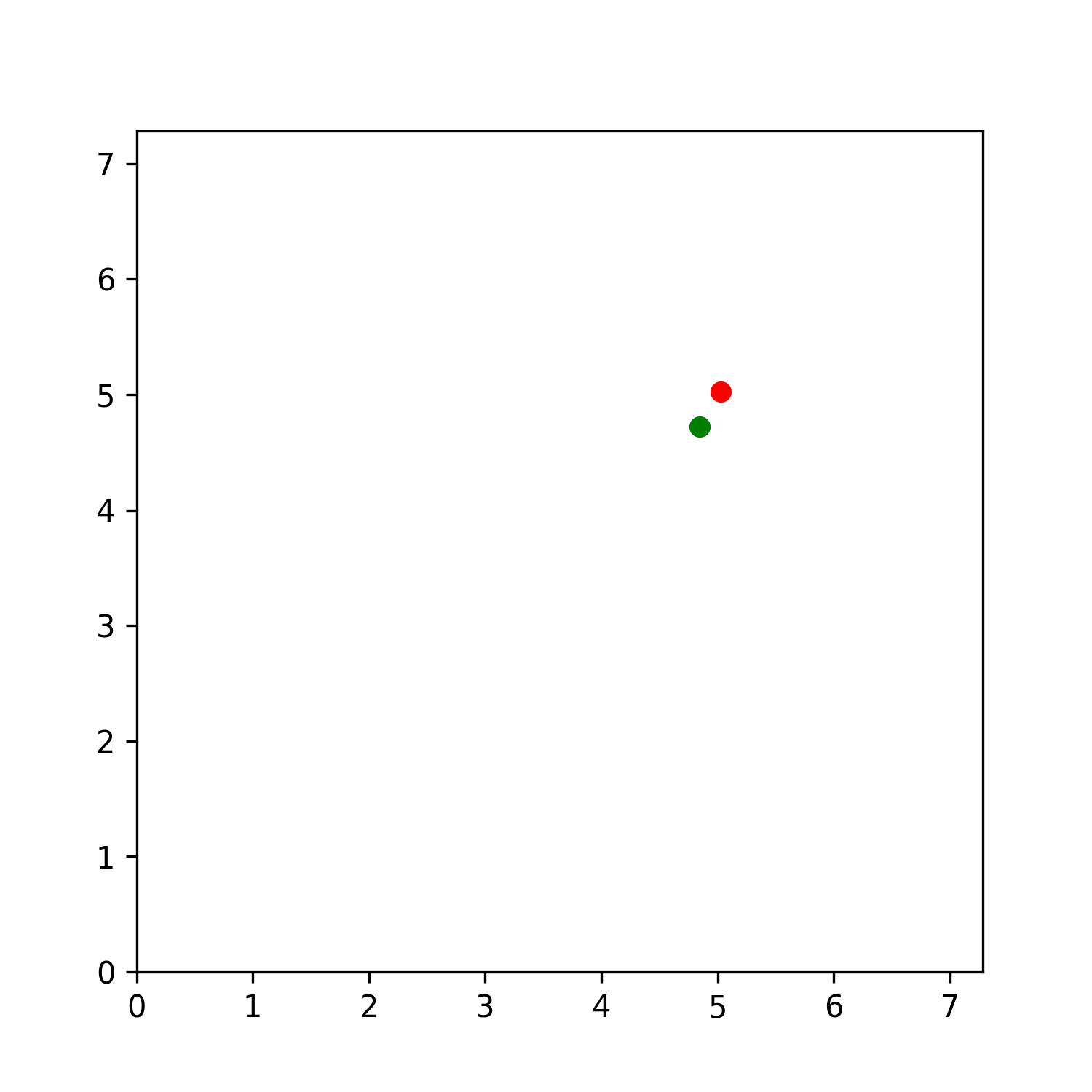
To do so, we sampled via a grid of parameters the state space of the Gridworld with directions environment. The grid was computed across 50 x values, 50 y values and 16 angle values equally separated. Then, we stored the latent representation computed by the model for each state and applied a t-SNE dimensionality reduction to qualitative evaluate the latent space referred to the state space.
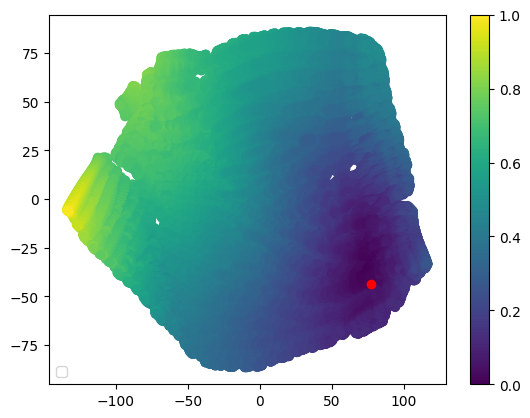
Figure 6: t-SNE representation of the latent space of the state space. The color represents the normalized predicted quasimetric distance between that state and the goal (red dot).
Figure 6 shows how these latent spaces learned by the model are meaningful with respect to the predicted quasimetric distance between two states. Inspecting it more in depth, it is possible to see how it also has some properties in this environment. Mostly, if you move along the x-axis in the reduced space, you advance in the y-axis in the env with different angles, while if you move along the y-axis in the reduced space, you advance in the x-axis in the environment. In addition, we believe that this behavior would also be present in other environments, but it needs further analysis.
We also inspect the latent space learnt at different levels of the network (e.g. after including the possible actions and after the encoder in the quasimetric network), and all of them have similar representations.
Conclusion & Future directions
Even in basic environments with limited action spaces, understanding the decision-making of agents with policies learned by neural networks can be challenging. Visualization and analysis of the learned latent space provide useful insights, but they require careful interpretation as results can be misleading.
As quasimetric learning is a nuanced topic, many problems from this week remain open and there are several interesting directions to pursue after these initial experiments:
Investigate the performance of quasimetric learning in various environments. What general properties of the environment are favorable for this approach?
Analyze world-models and multi-step planning. In this project, we examined only a 1-step greedy strategy.
Formulate and analyze quasimetric learning within a multi-environment context.
Design and evaluate more intricate environments suitable for real robot control
Students: Tewodros (Teddy) Tassew, Anthony Ramos, Ricardo Gloria, Badea Tayea
TAs: Heng Zhao, Roger Fu
Mentors: Yingying Wu, Etienne Vouga
Introduction
Shape analysis has been an important topic in the field of geometry processing, with diverse interdisciplinary applications. In 2005, Reuter, et al., proposed spectral methods for the shape characterization of 3D and 2D geometrical objects. The paper demonstrates that the Laplacian operator spectrum is able to capture the geometrical features of surfaces and solids. Besides, in 2006, Reuter, et al., proposed an efficient numerical method to extract what they called the “Shape DNA” of surfaces through eigenvalues, which can also capture other geometric invariants. Later, it was demonstrated that eigenvalues can also encode global properties like topological features of the objects. As a result of the encoding power of eigenvalues, spectral methods have been applied successfully to several fields in geometry processing such as remeshing, parametrization and shape recognition.
In this project, we present a discrete surface characterization method based on the extraction of the top smallest k eigenvalues of the Laplace-Beltrami operator. The project consists of three main parts: data preparation, geometric feature extraction, and shape classification. For the data preparation, we cleaned and remeshed well-known 3D shape model datasets; in particular, we processed meshes from ModelNet10, ModelNet40, and Thingi10k. The extraction of geometric features is based on the “Shape DNA” concept for triangular meshes which was introduced by Reuter, et al. To achieve this, we computed the Laplace-Beltrami operator for triangular meshes using the robust-laplacian Python library.
Finally, for the classification task, we implemented some machine learning algorithms to classify the smallest k eigenvalues. We first experimented with simple machine learning algorithms like Naive Bayes, KNN, Random Forest, Decision Trees, Gradient Boosting, and more from the sklearn library. Then we experimented with the sequential model Bidirectional LSTM using the Pytorch library to try and improve the results. Each part required different skills and techniques, some of which we learned from scratch and some of which we improved throughout the two previous weeks. We worked on the project for two weeks and received preliminary results. The GitHub repo for this project can be found in this GitHub repo.
Data preparation
The datasets used for the shape classification are:
1. ModelNet10: The ModelNet10 dataset, a subset of the larger ModelNet40 dataset, contains 4,899 shapes from 10 categories. It is pre-aligned and normalized to fit in a unit cube, with 3,991 shapes used for training and 908 shapes for testing.
2. ModelNet40: This widely used shape classification dataset includes 12,311 shapes from 40 categories, which are pre-aligned and normalized. It has a standard split of 9,843 shapes for training and 2,468 for testing, making it a widely used benchmark.
3. Thingi10k: Thingi10k is a large-scale dataset of 10,000 models from thingiverse.com, showcasing the variety, complexity, and quality of real-world models. It contains 72 categories that capture the variety and quality of 3D printing models.
For this project, we decided to use a subset of the ModelNet10 dataset to perform some preprocessing steps on the meshes and apply a surface classification algorithm due to the number of classes it has for analysis. Meanwhile, the ModelNet10 dataset is unbalanced, so we selected 50 shapes for training and 25 for testing per class.
Moreover, ModelNet datasets do not fully represent the surface representations of objects; self-intersections and internal structures are present, which could affect the feature extraction and further classification. Therefore, for future studies, a more careful treatment of mesh preprocessing is of primary importance.
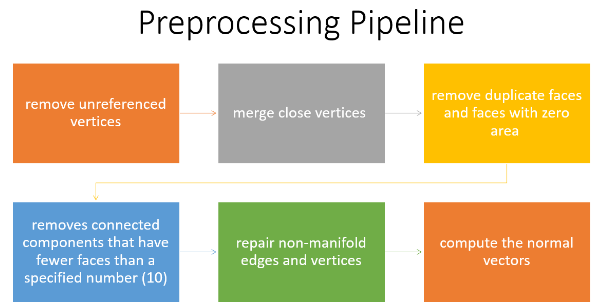
Preprocessing Pipeline
After the dataset preparation, the preprocessing pipeline consists of some steps to clean up the meshes. These steps are essential to ensure the quality and consistency of the input data, and to avoid errors or artifacts. We used the PyMeshLab library, which is a Python interface to MeshLab, for mesh processing. The pipeline consists of the following steps:
1.Remove unreferenced vertices: This method gets rid of any vertices that don’t belong to a face.
2. Merge nearby vertices: This function combines vertices that are placed within a certain range (i.e., ε = 0.001).
3.Remove duplicate faces and faces with zero areas: It eliminates faces with the same features or no area.
4. Removes connected components that have fewer faces than a specified number (i.e. 10): The effectiveness and accuracy of the model can be enhanced by removing isolated mesh regions that are too small to be useful.
5.Repair non-manifold edges and vertices: It corrects edges and vertices that are shared by more than two faces, which is a violation of the manifold property. The mesh representation can become problematic with non-manifold geometry.
6.Compute the normal vectors: The orientation of the adjacent faces is used to calculate the normal vectors for each mesh vertex.
These steps allow us to obtain clean and consistent meshes that are ready for the remeshing process.
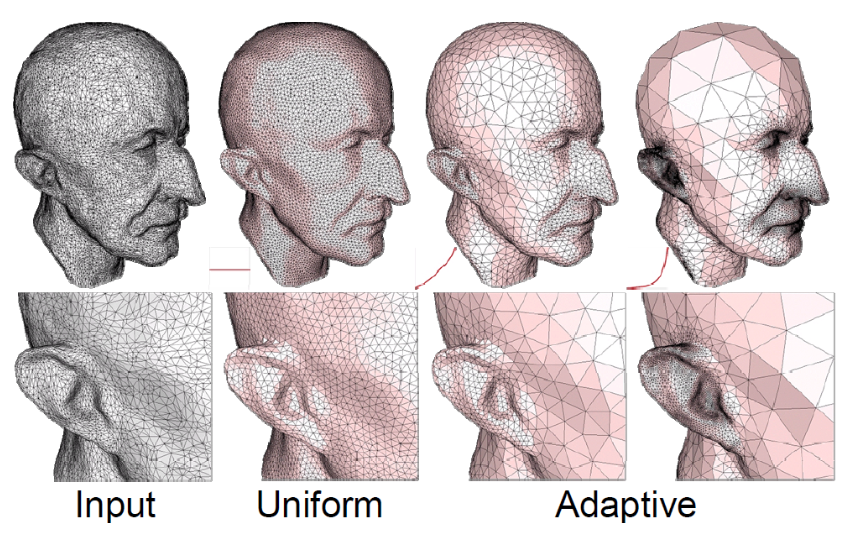
Figure 1 Preprocessing Pipeline
Adaptive Isotropic Remeshing
The quality of the meshes is one of the key problems with the collected 3D models. When discussing triangle quality, it’s important to note that narrow triangles might result in numerical inaccuracies when the Laplace-Beltrami operator is being computed. In that regard, we remeshed each model utilizing adaptive isotropic remeshing implemented in PyMeshLab. Triangles with a favorable aspect ratio can be created using the procedure known as isotropic remeshing. In order to create a smooth mesh with the specified edge length, the technique iteratively carries out simple operations like edge splits, edge collapses, and edge flips.
Adaptive isotropic remeshing transforms a given mesh into one with non-uniform edge lengths and angles, maintaining the original mesh’s curvature sensitivity. It computes the maximum curvature for the reference mesh, determines the desired edge length, and adjusts split and collapse criteria accordingly. This technique also preserves geometric details and reduces the number of obtuse triangles in the output mesh.
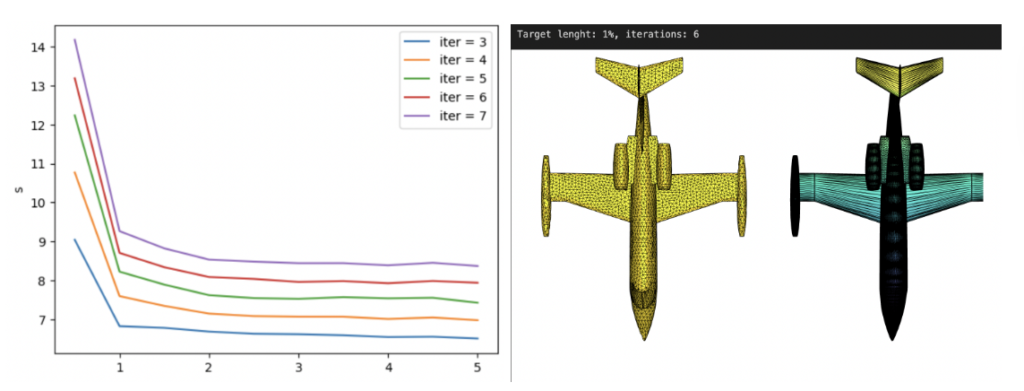
We applied the PyMeshLab function ms.meshing_isotropic_explicit_remeshing() to remesh the ModelNet10 dataset for this project. We experimented with different parameters of the isotropic remeshing algorithm from PyMeshLab to optimize the performance. The optimal parameters for time, type of remesh, and triangle quality were iterations=6, adaptive=True, and targetlen=pymeshlab.Percentage(1) respectively. The adaptive=True parameter enabled us to switch from uniform to adaptive isotropic remeshing. Figure 3 illustrates the output of applying adaptive remeshing to the airplane_0045.off mesh from the ModelNet40 training set. We also tried the pygalmesh.remesh_surface() function, but it was very slow and produced unsatisfactory results.
Figure 3 Plot for time vs target length (left) and the yellow airplane is the re-meshing result for parameter values of Iterations = 6 and targetlen = 1% while the blue airplane is the original mesh (right).
The Laplace-Beltrami Spectrum Operator
In this section, we introduce some of the basic theoretical foundations used for our characterization. Specifically, we define the Laplacian-Beltrami operator along with some of its key properties, explain the significance of the operator and its eigenvalues, and display how it has been implemented in our project.
Definition and Properties of the Laplace-Beltrami Operator
The Laplacian-Beltrami operator, often denoted as Δ, is a differential operator which acts on smooth functions on a Riemannian manifold (which, in our case, is the 3D surface of a targeted shape). The Laplacian-Beltrami operator is an extension of the Laplacian operator in Euclidean space, adjusted for curved surfaces on the manifold. Mathematically, the Laplacian-Beltrami operator acting on a function on a manifold is defined using the following formula:
where ∂idenotes the i-th partial derivative, g is the determinant of the metric tensor gij of the manifold and gijis the inverse of the metric tensor.
The Laplacian-Beltrami operator serves as a measure of how the value of f at a point deviates from its average value within infinitesimally small neighborhoods around that point. Therefore, the operator can be adopted to describe the local geometry of the targeted surface.
The Eigenvalue Problem and Its Significance
Laplacian-Beltrami operator is a second-order function applied to a surface, which could be represented as a matrix whose eigenvalues/eigenvectors provide information about the geometry and topology of a surface.
The significance of the eigenvalue problem as a result of applying the Laplace-Beltrami Operator includes:
Functional Representation. The eigenfunctions corresponding to a particular geometric surface form an orthonormal basis of all functions on the surface, providing an efficient way to represent any function on the surface.
Surface Characterization. A representative feature vector containing the eigenvalues creates a “Shape-DNA” of the surface, which captures the most significant variations in the geometry of the surface.
Dimensionality Reduction. Using eigenvalues can effectively reduce the dimensionality of the data used, aiding in more efficient processing and analysis.
Feature Discrimination. The geometric variations and differences between surfaces can be identified using eigenvalues. If two surfaces have different eigenvalues, they are likely to have different geometric properties. Surface eigenvalue analysis can be used to identify features that are unique to each surface. This can be beneficial in computer graphics and computer vision applications where it is necessary to distinguish between different surfaces.
Discrete Representation of Laplacian-Beltrami Operator
In the discrete setting, the Laplacian-Beltrami operator is defined on the given meshes. The Discrete Laplacian-Beltrami operator L can be defined and computed using different approaches. An often-used representation is using the cotangent matrix defined as follows:
Then L = M-1C where M is the diagonal mass matrix whose i-th entry is the shaded area as shown in Figure 4 for each vertex i. The Laplacian matrix is a symmetric positive-semidefinite matrix. Usually, L is sparse and stored as a sparse matrix in order not to waste memory.
Figure 4 (Left) Definition of edge i-j and angles for a triangle mesh. (Right) Representation of Voronoi area for vertex vi.
A Voronoi diagram is a mathematical method for dividing a plane into areas near a collection of objects, each with its own Voronoi cell. It contains all of the points that are closer to it than any other object. Since its origin, engineers have utilized the Delaunay triangulation to maximize the minimum angle among possible triangulations of a fixed set of points. In a Voronoi diagram, this triangulation corresponds to the nerve cells.
Experimental Results
In our experiments, we rescaled the vertices before computing the cotangent Laplacian. Rescaling mesh vertices changes the size of an object without changing its geometry. This Python function rescales a 3D point cloud by translating it to fit within a unit cube centered at the origin. It then scales the point cloud to have a maximum norm of 1, ensuring its center is at the origin. The function then finds the maximum and minimum values of each dimension in the input point cloud, computes the size of the point cloud in each dimension, and computes a scaling factor for each dimension. The input point cloud is translated to the center at the origin and scaled by the maximum of these factors, resulting in a point cloud with a maximum norm of 1.
Throughout this project, we used the robust-laplacian Python package to compute the Laplacian-Beltrami operator. This library deals with point clouds instead of triangle meshes. Moreover, the package can handle non-manifold triangle meshes by implementing the algorithm described in A Laplacian for Nonmanifold Triangle Meshes by Nicholas Sharp and Keenan Crane.
For the computation of the eigenvalues, we used the SciPy Python library. Let’s recall the eigenvalue problem Lv = λv, where λ is a scalar, and v is a vector. For a linear operator L, we called λ eigenvalue and v eigenvector respectively. In our project, the smallest keigenvalues and eigenfunctions corresponding to 3D surfaces formed feature vectors for each shape, which were then used as input of machine learning algorithms for tasks such as shape classification.
Surface Classification
The goal of this project was to apply spectral methods to surface classification using two distinct datasets: a synthetic one and ModelNet10. We used the Trimesh library to create some basic shapes for our synthetic dataset and performed remeshing on each shape. This was a useful step to verify our approach before working with more complicated data. The synthetic data had 6 classes with 50 instances each. The shapes were Annulus, Box, Capsule, Cone, Cylinder, and Sphere. We computed the first 30 eigenvalues on 50 instances of each class, following the same procedure as the ModelNet dataset so that we could compare the results of both datasets. We split the data into 225 training samples and 75 testing samples.
For the ModelNet10 dataset, we selected 50 meshes for the training set and 25 meshes for the testing set per class. In total, we took 500 meshes for the training set and 250 meshes for the testing set. After experimenting with different machine learning algorithms, the validation results for both datasets are summarized below in Table 1. The metric used for the evaluation procedure is accuracy.
Models
Accuracy for Synthetic Dataset
Accuracy for ModelNet 10
KNN
0.49
0.31
Random forest
0.69
0.33
Linear SVM
0.36
0.11
RBF SVM
0.60
0.10
Gaussian Process
0.59
0.19
Decision Tree
0.56
0.32
Neural Net
0.68
0.10
AdaBoost
0.43
0.21
Naive Bayes
0.23
0.19
QDA
0.72
0.21
Gradient Boosting
0.71
0.31
Table 1 Accuracy for synthetic and ModelNet10 datasets using different machine learning algorithms.
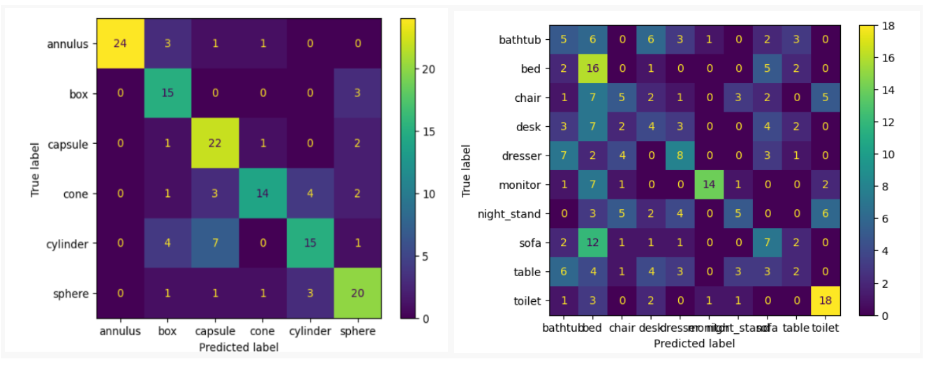
From Table 1 we can observe that the decision tree, random forest, and gradient boosting algorithms performed well on both datasets. These algorithms are suitable for datasets that have graphical features. We used the first 30 eigenvalues on 50 samples of each class for both the ModelNet and synthetic datasets, ensuring a fair comparison between the two datasets. Figure 5 shows the classification accuracy for each class using the confusion matrix.
Figure 5 Confusion matrix using Random Forest on the synthetic dataset (left) and ModelNet10 dataset (right).
We conducted two additional experiments using deep neural networks implemented in Pytorch, besides the machine learning methods we discussed before. The first experiment involved a simple MLP model consisting of 5 fully connected layers, each with the Batch Norm and ReLU activation functions. The model achieved an accuracy of 57% on the synthetic dataset and 15% on the ModelNet10 dataset for the testing set. The second experiment used a sequential model called Bidirectional LSTM with two layers. The model achieved an accuracy of 34% for the synthetic dataset and 33% for the ModelNet10 dataset based on the testing set. These are reasonable results since the ModelNet dataset contains noise, artifacts, and flaws, potentially affecting model accuracy and robustness. Examples include holes, missing components, uneven surfaces, and most importantly, the interior structures. All of these issues could potentially impact the overall performance of the models, especially for our classification purposes. We present the results in Table 2. The results indicate that the MLP model performed well on the synthetic dataset while the Bi-LSTM model performed better on the ModelNet10 dataset.
Models
Accuracy for Synthetic Dataset
Accuracy for ModelNet 10
MLP
0.57
0.15
Bi-LSTM
0.34
0.33
Table 2 Accuracy for synthetic and ModelNet10 datasets using deep learning algorithms.
Future works
We faced some challenges with the ModelNet10 dataset. The dataset had several flaws that resulted in lower accuracy when compared to the synthetic dataset. Firstly, we noticed some meshes with disconnected components, which caused issues with the computation of eigenvalues, since we would get one zero eigenvalue for each disconnected component, lowering the quality of the features computed for our meshes. Secondly, these meshes had internal structures, i.e., vertices inside the surface, which also affected the surface recognition power of the computed eigenvalues, as well as other problems related to self-intersections and non-manifold edges.
The distribution of eigenvalues in a connected manifold is affected by scaling. The first-keigenvalues are related to the direction encapsulating the majority of the manifold’s variation. Scaling by α results in a more consistent shape with less variation along the first-k directions. On the other hand, scaling by 1/α causes the first-k eigenvalues to grow by α2, occupying a higher fraction of the overall sum of eigenvalues. This implies a more varied shape with more variance along the first-k directions.
To address the internal structures problem, we experimented with several state-of-the-art surface reconstruction algorithms for extracting the exterior shape and removing internal structures using the Ball Pivoting, Poisson Distribution methods from the Python PyMeshLab library, and Alpha Shapes. One of the limitations of ball pivoting is that the quality and completeness of the output mesh depend on the choice of the ball radius. The algorithm may miss some parts of the surface or create holes if the radius is too small. Conversely, if the radius is too large, the method could generate unwanted triangles or smooth sharp edges. Ball pivoting also struggles with noise or outliers and can result in self-intersections or non-manifold meshes.
By using only vertices to reconstruct the surface, we significantly reduced the computational time but the drawback was that the extracted surface was not stable enough to recover the entire surface. It also failed to remove the internal structures completely. In future work, we intend to address this issue and create an effective algorithm that can extract the surface from this “noisy” data. For this issue, implicit surface approaches show great promise.
References
Reuter, M., Wolter, F.-E., & Niklas Peinecke. (2005). Laplace-spectra as fingerprints for shape matching. Solid and Physical Modeling. https://doi.org/10.1145/1060244.1060256
Reuter, M., Wolter, F.-E., & Niklas Peinecke. (2006). Laplace–Beltrami spectra as “Shape-DNA” of surfaces and solids. Computer Aided Design, 38(4), 342–366. https://doi.org/10.1016/j.cad.2005.10.011
Reuter, M., Wolter, F.-E., Shenton, M. E., & Niethammer, M. (2009). Laplace–Beltrami eigenvalues and topological features of eigenfunctions for statistical shape analysis. 41(10), 739–755. https://doi.org/10.1016/j.cad.2009.02.007
Nealen, A., Igarashi, T., Sorkine, O., & Alexa, M. (2006). Laplacian mesh optimization. Conference on Computer Graphics and Interactive Techniques in Australasia and Southeast Asia. https://doi.org/10.1145/1174429.1174494
Implicit neural representation promises infinite resolution, automatic gradients, and memory efficiency. In practice, however, these promises often do not hold. Our project explored one specific drawback of implicit neural representations: the noisy gradient. The source code of this project is available on our GitHub repository.
The noisy gradient problem of neural representation has been observed in the context of solving PDEs [1], geometry processing [2,3], topology optimization [4], and 3D reconstruction [5].
1.1. Motivational Example: 1D advection
Our goal is to solve time-dependent PDEs on neural network-based spatial representations. Let’s consider the classic 1D advection equation:
This equation describes the passive advection of some scalar field u carried along at a constant speed a.
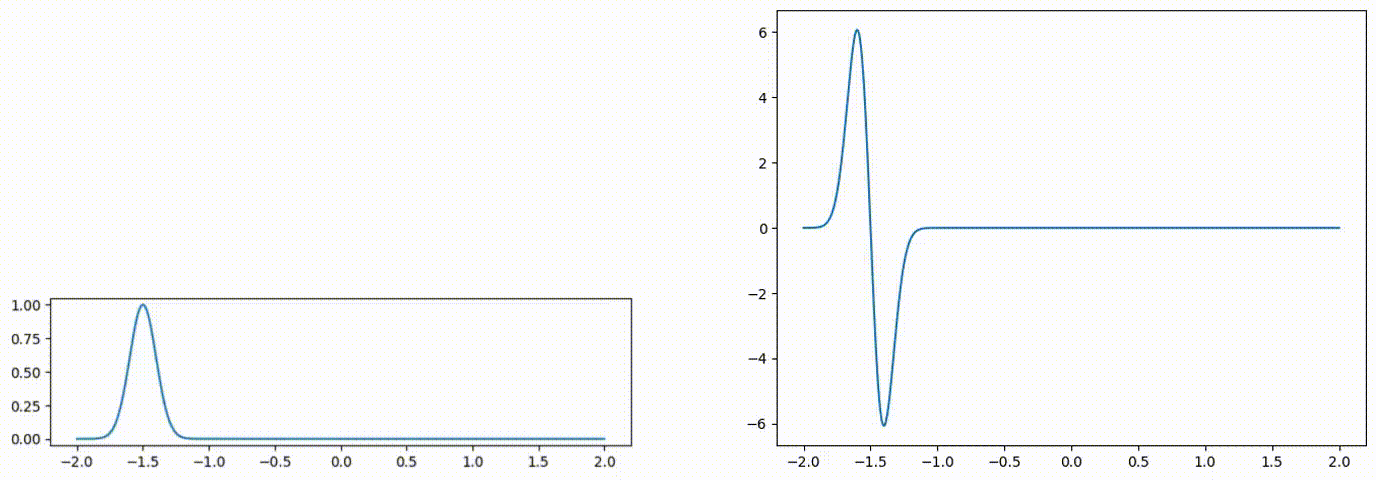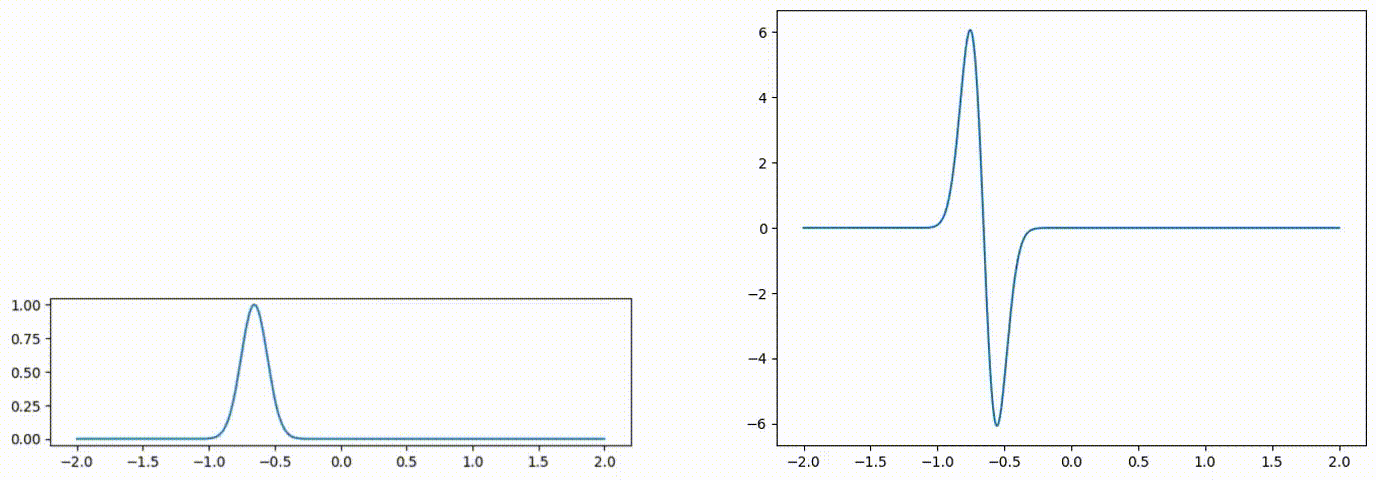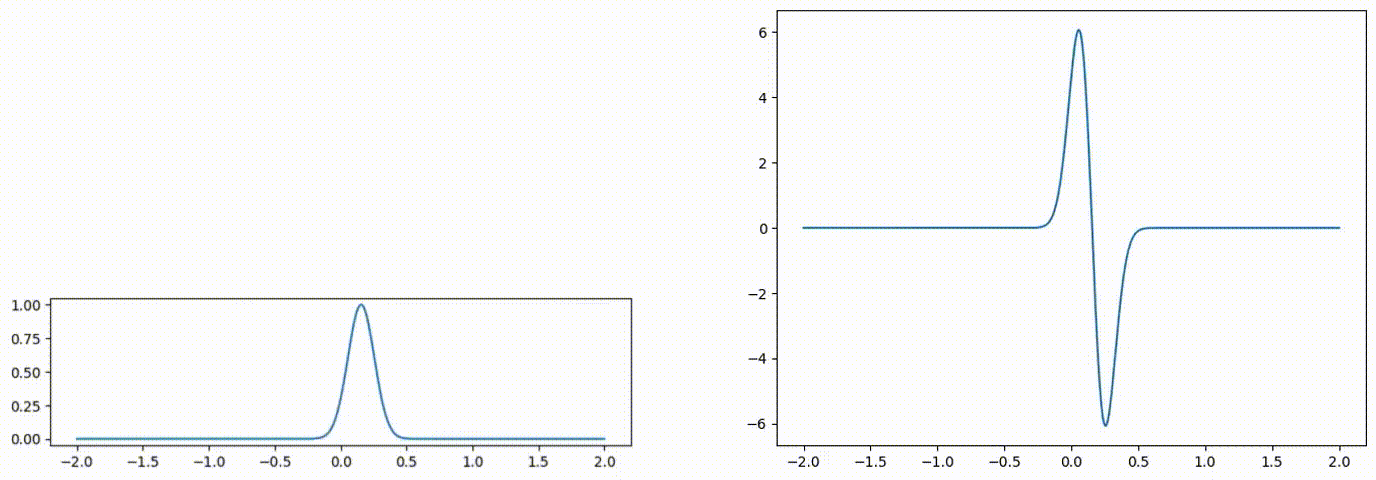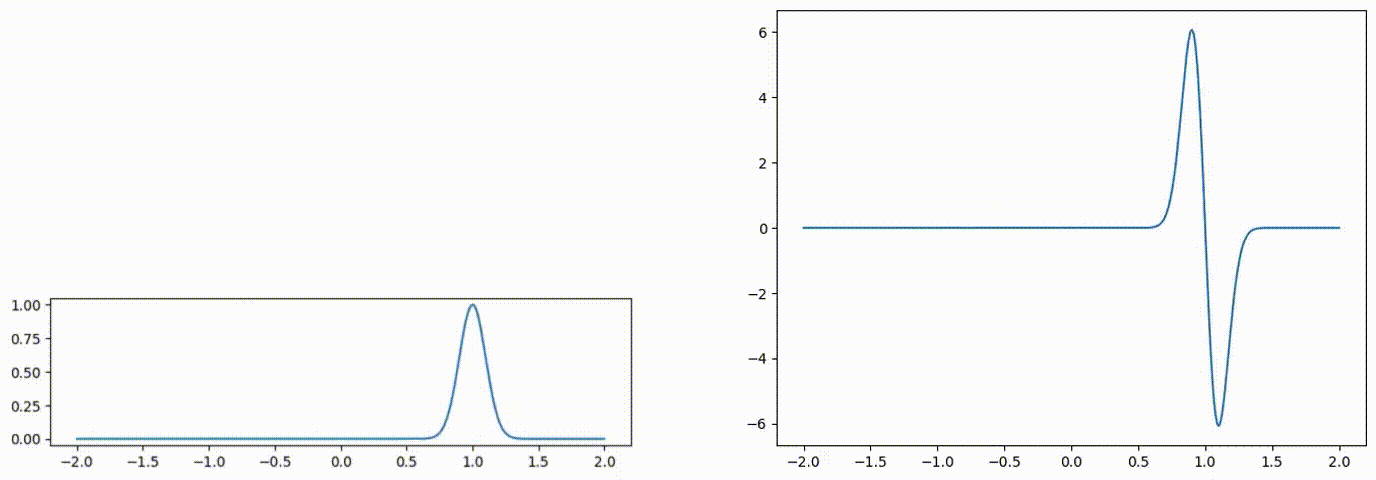
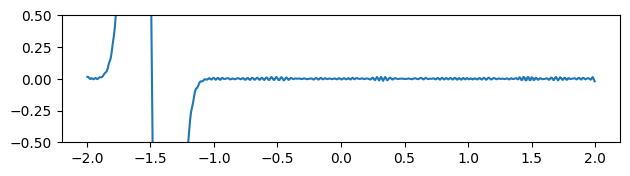
Fig 1: Advected scalar field (left), and gradient of the advected quantity (right) over time.
We will parameterize each time-discretized spatial field with a neural network. The field quantity at an arbitrary location can be queried via network inference f(x). The weights of this network are updated at each time step with optimization-based time integration [1].
1.2. The Problem: Noisy Gradients
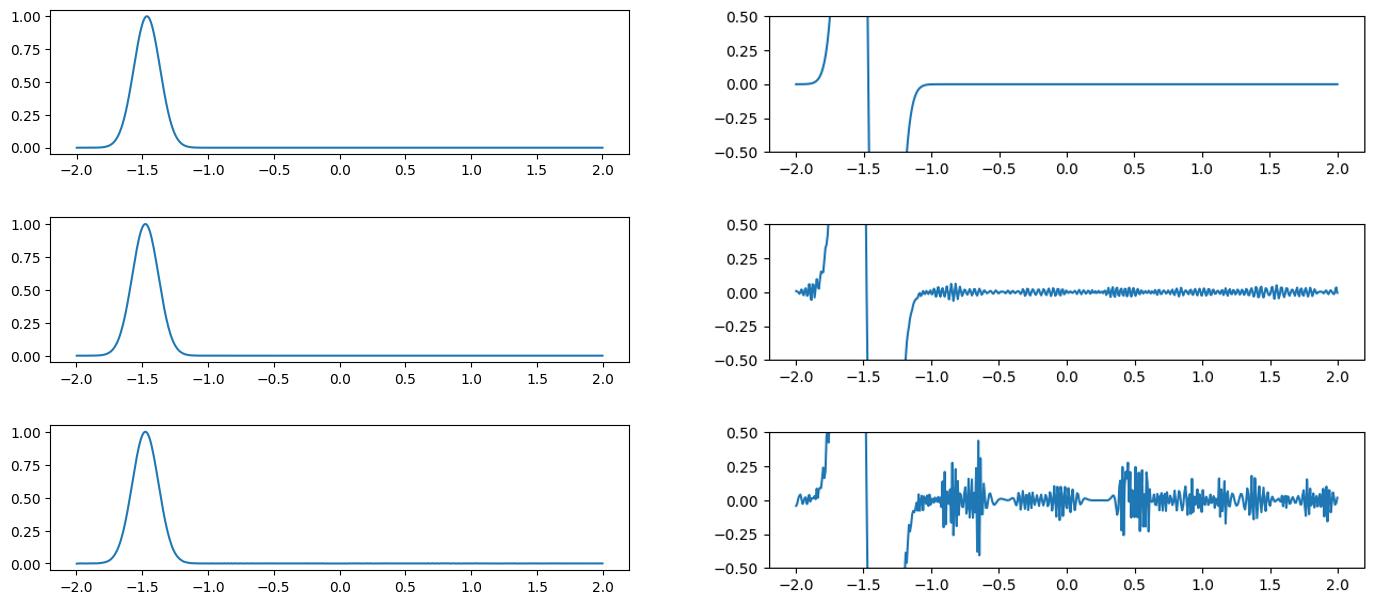
Fig 2: Comparisons of advected values and gradients of different neural representations. Ground truth (top row), the sine activation (middle row), and the Gaussian activation (bottom row).
Following the INSR literature, we explore different activation functions for our neural network-based scalar field. The figure above compares the predicted scalar quantity and their gradients for both sine [8] and Gaussian [12] activation networks. The predicted scalar quantity matches the ground truth well in all cases. But the gradient of the advected quantity is extremely noisy regardless of the choice of the activation function.
In the subsequent sections, we will tackle this problem using several approaches that fall into two categories: pure neural representation (Section 2) and hybrid grid-neural representations (Section 3).
2. Pure Neural Representations
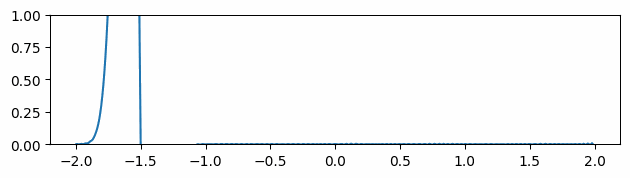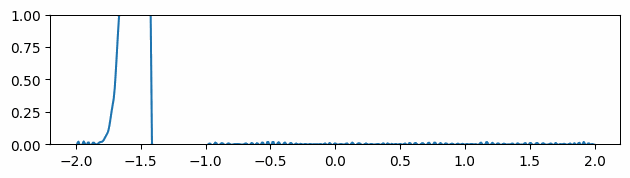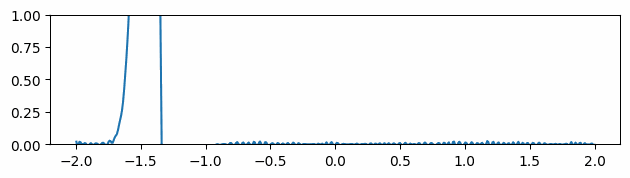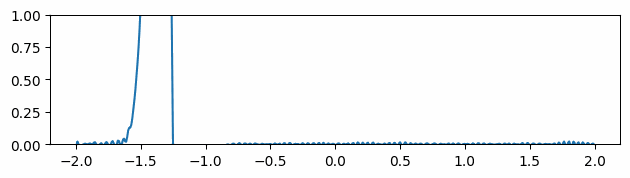
2.1 Tuning Omega
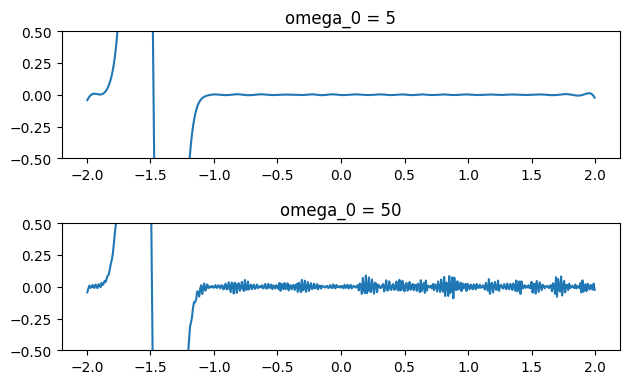
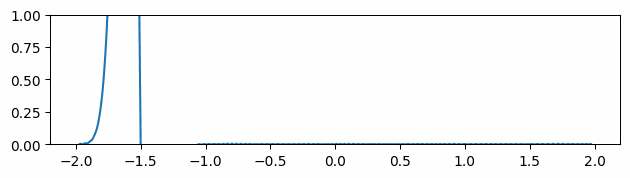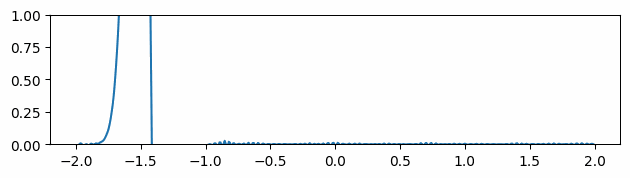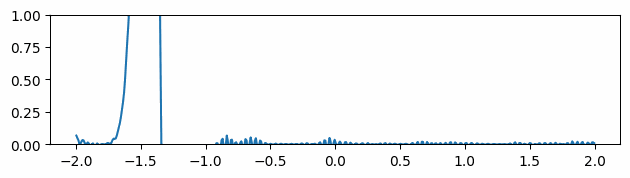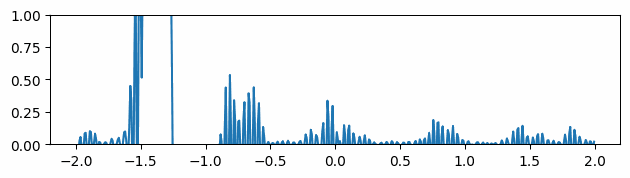
Fig 3: Large omega values cause noisy gradients, while small omega values give smoother gradients.
The omega hyperparameter controls the frequency range that the SIREN network learns [8]. In general, if we reduce the value of omega, the gradients learned by the networks become less noisy. As seen in the figure above, choosing omega = 5 ensures the network has smooth gradients, while choosing a larger value like 50 gives us very noisy gradients. However, finding the optimal omega value is a non-trivial task. Users need to tune this parameter for each problem.
2.2. Finite Differences
Fig 4: Gradients estimated by finite difference method.
Instead of calculating the gradients by taking the derivative of the output with respect to the inputs using autodiff, we can also use finite differences to approximate the gradients. Because finite difference stencils have local compact supports, they are less susceptible to noise. Indeed, the gradients of the finite difference solution are much less noisy than the autodiff version (see figure above).
2.3 Averaging
Fig 5: Evolving of the gradient of the function over time in the mean gradients approach.
Instead of using the gradients computed by autodiff, we spatially average them by calculating the mean at four more neighboring points for each location. Although the gradients seem smoother at the very beginning, it is easy to see that after a few timesteps, the gradient’s peaks become fictitiously taller, degrading the results (Fig 5).
2.4 Initializing with Ground Truth Gradients
Fig 6: Evolving of the gradient of the function over time where the gradients are initialized to be the ground truth gradients.
At timestep 0, the neural network is trained to predict the initial values of the function we are trying to optimize. In addition, similarly to what is done in Sobolev training [6], we force the model to have the same gradients as the desired function.
This method does reduce the noise in the gradient over time (Fig 6), but the information gathered from the extra supervision used in the initialization steps slowly dissolves. Furthermore, these gradients are not always available or not suitable for setting up a loss function in such a manner, making this solution not always applicable.
3. Hybrid grid-neural representations
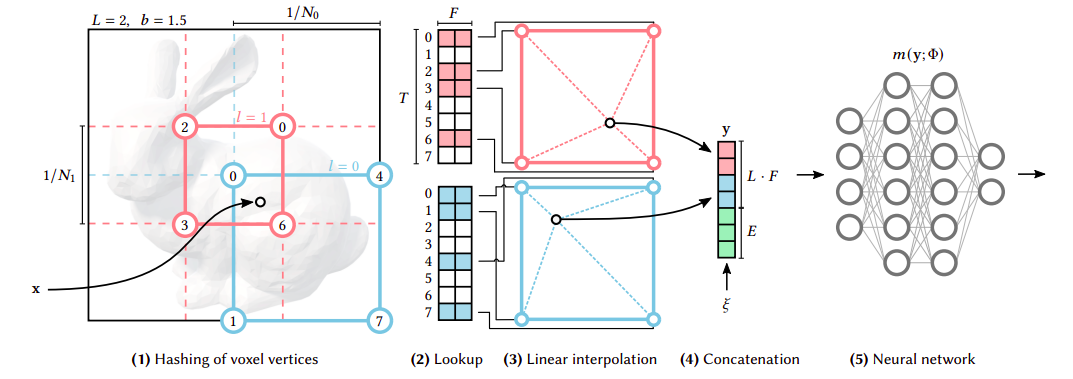
Fig 7: Description of the multi-resolution hashgrid (reproduced from [7]).
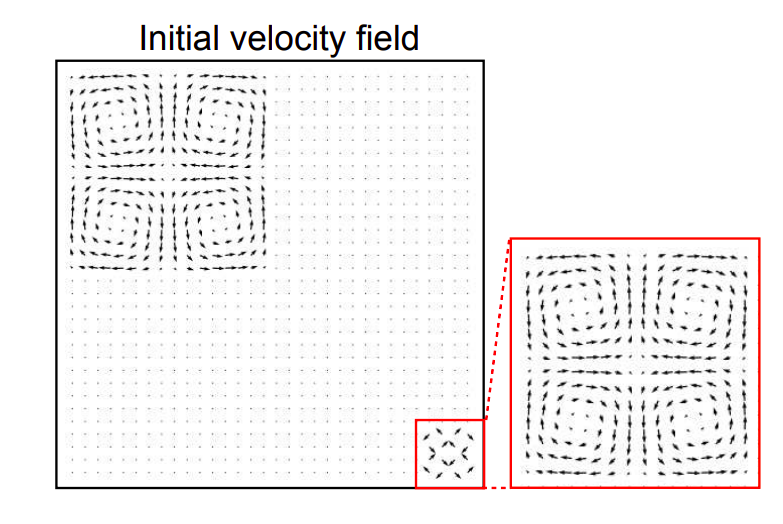
To address neural representations’ long training time, Muller et al. [7] developed a multi-resolution hash grid approach: instantNGP. In the following section, we explore instantNGP’s gradient quality. We benchmark it on a 2D fluid example. The figure below shows the example’s initial condition:
Fig 8: Vortex velocity field (reproduced from [1]).
When we try to fit this initial condition using a pure neural representation (i.e., NOT instantNGP), we observe highly noisy gradients, consistent with the results reported in Section 2.1.
Fig 9: Gradient we obtained using pure neural representations for the proposed 2D vortex problem.
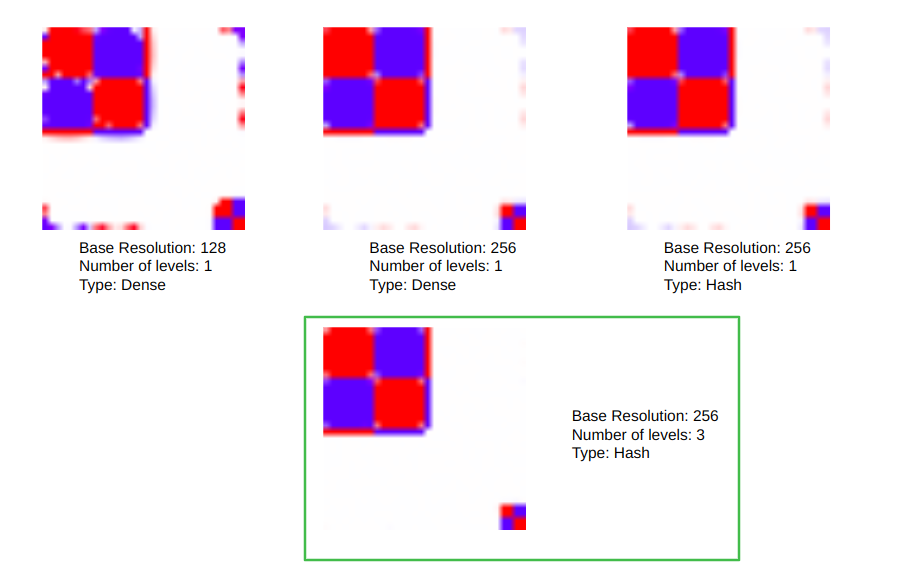
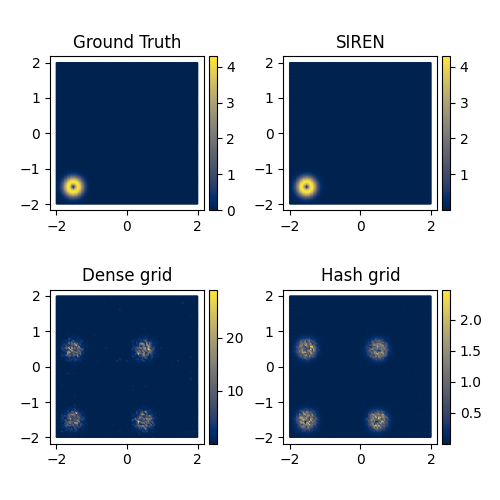
Next, we investigated hybrid neural-grid representations, varying the type of the grids and the type of the hash (See Fig 10).
Fig 10: Different gradients for different resolutions.
The parameters outlined in green obtained the best result. In this case, we use a base resolution of 256 and a 3-level hash grid.
However, those results only accounted for the initial conditions. If we let the gradients evolve for 99 timesteps according to the PDE, we observe that the gradients start diverging, as can be seen in the video below.
Fig 11: Evolution of the gradients for the 2D fluids for the two vortices example. This test was done with a dense grid of 512 resolution.
In summary, although our hybrid approach seems excellent for the first timesteps, it also appears to limit the expressivity of the network during subsequent evolution.
Due to these problems in the 2D Fluid scenario, we investigated the gradients’ performance in another environment: the 2D Advection problem.
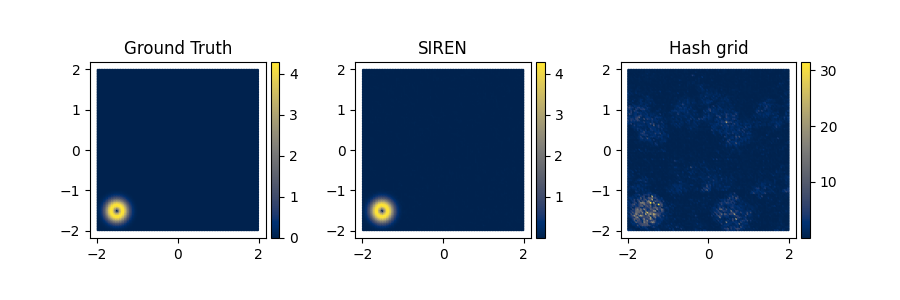
Fig 12: Comparison of Gradient Magnitudes for Different methods.
We used the same network configurations (base resolution, number of levels, number of hidden layers, and hidden features) as the 2D Fluid problem. The hybrid neural-grid representation performs significantly worse than the pure neural representation using SIREN (see Fig 12). Here the network is asked to fit the initial condition only.
Next, we tried to tune the configuration parameters. We discovered that the models performed better for the 2D Advection scenario when the number of level is increased. The best result is given by the following parameters: number of Levels: 16; per Level Scale: 1.5; Base resolution: 16.
Fig 13: Comparison of Gradient Magnitudes for Hash grid’s best parameters.
Even though the hash grid’s performances improved, the figure above demonstrates that the gradients are still much noisier than the pure neural representation (SIREN).
As such, we conclude that the hybrid grid-neural representation’ performance is not consistently better than the pure neural representation. In fact, it’s sometimes worse, as demonstrated in the 2D advection example.
4. Future Work
Since our tests and other SIREN works [8] show that tuning the omega hyperparameter is essential for the gradient results, one possible next step is to perform automatic gradient tuning, as proposed in meta-learning techniques [9].
Another possible approach is supervising the gradients. Instead of using the original function to compute the gradients, it is possible to use a separate loss function that certifies the correct gradient values over time. Essentially, we aim to write down the evolution equation of the gradient itself and couple this equation with the original PDE.
Future work should also consider a theoretical understanding of the gradient problem. One possible cause for this problem is the global non-compact support of neural networks. This initially motivates us to explore hybrid grid-neural networks. Other works [7, 10, 11] used similar approaches to extract local features to feed into the network, enforcing a locality to the neural network.
5. References
[1] Chen, Honglin, Wu Rundi, Eitan Grinspun, Changxi Zheng, and Peter Yichen Chen. “Implicit Neural Spatial Representations for Time-dependent PDEs.” International Conference on Machine Learning (ICML). 2023.
[2] Mehta, Ishit, Manmohan Chandraker, and Ravi Ramamoorthi.” A level set theory for neural implicit evolution under explicit flows.” European Conference on Computer Vision (ECCV). 2022.
[3] Yang, Guandao, Serge Belongie, Bharath Hariharan, and Vladlen Koltun. “Geometry processing with neural fields.” Neural Information Processing Systems (NeurIPS). 2021.
[4] Zehnder, Jonas, Yue Li, Stelian Coros, and Bernhard Thomaszewski. “Ntopo: Mesh-free topology optimization using implicit neural representations.” Neural Information Processing Systems (NeurIPS). 2021.
[5] Verbin, Dor, Peter Hedman, Ben Mildenhall, Todd Zickler, Jonathan T. Barron, and Pratul P. Srinivasan. “Ref-nerf: Structured view-dependent appearance for neural radiance fields.” Conference on Computer Vision and Pattern Recognition (CVPR). 2022.
[6] Czarnecki, Wojciech M., Simon Osindero, Max Jaderberg, Grzegorz Swirszcz, and Razvan Pascanu. “Sobolev training for neural networks.” Neural Information Processing Systems (NeurIPS). 2017.
[7] Müller, Thomas, Alex Evans, Christoph Schied, and Alexander Keller. “Instant neural graphics primitives with a multiresolution hash encoding.” ACM Transactions on Graphics (ToG) 41. 2022.
[8] Sitzmann, Vincent, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. “Implicit neural representations with periodic activation functions.” Neural Information Processing Systems (NeurIPS). 2020.
[9] Hospedales, Timothy, Antreas Antoniou, Paul Micaelli, and Amos Storkey. “Meta-learning in neural networks: A survey.” IEEE transactions on pattern analysis and machine intelligence 44.9. 2021.
[10] Sun, Cheng, Min Sun, and Hwann-Tzong Chen. “Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction.” Conference on Computer Vision and Pattern Recognition (CVPR). 2022.
[11] Barron, Jonathan T., Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. “Zip-NeRF: Anti-aliased grid-based neural radiance fields.” International Conference on Computer Vision (ICCV). 2023.
[12] Shin-Fang Chng, Sameera Ramasinghe, Jamie Sherrah, Simon Lucey. “Gaussian Activated Radiance Fields for High Fidelity Reconstruction and Pose Estimation” The European Conference on Computer Vision (ECCV). 2022.